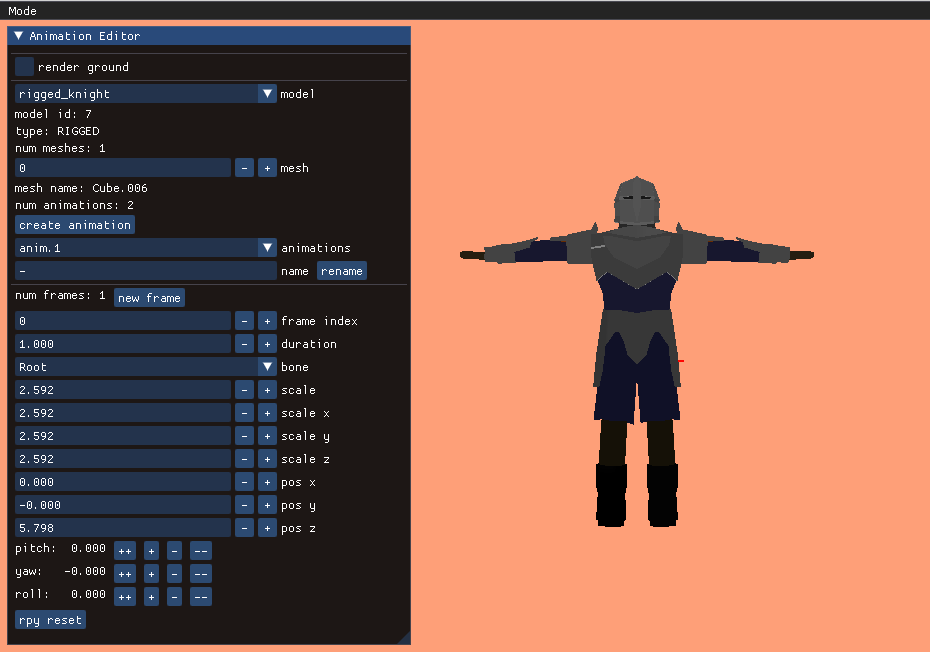
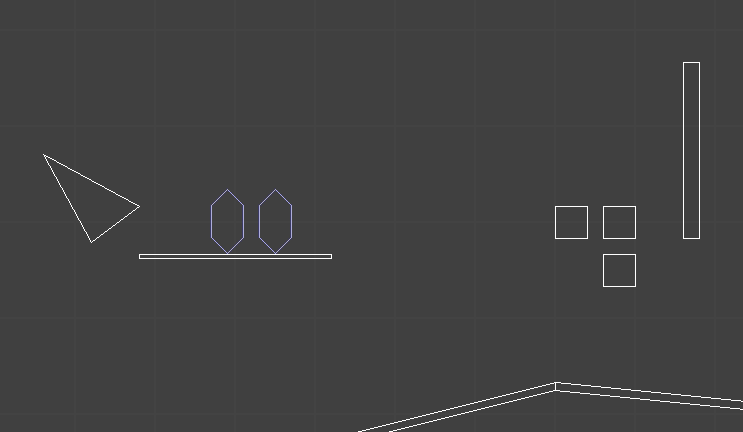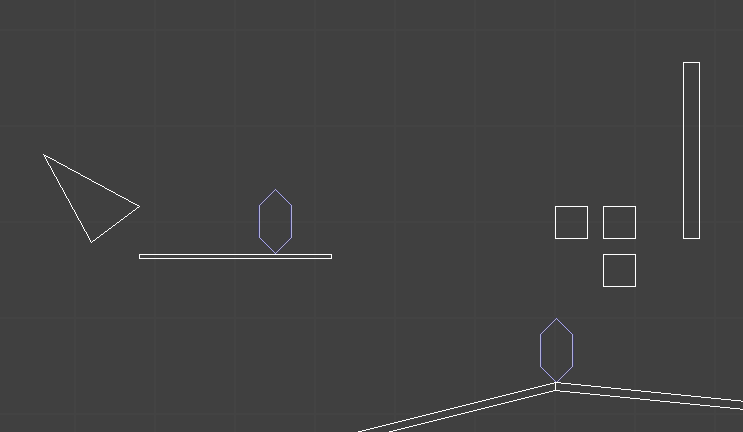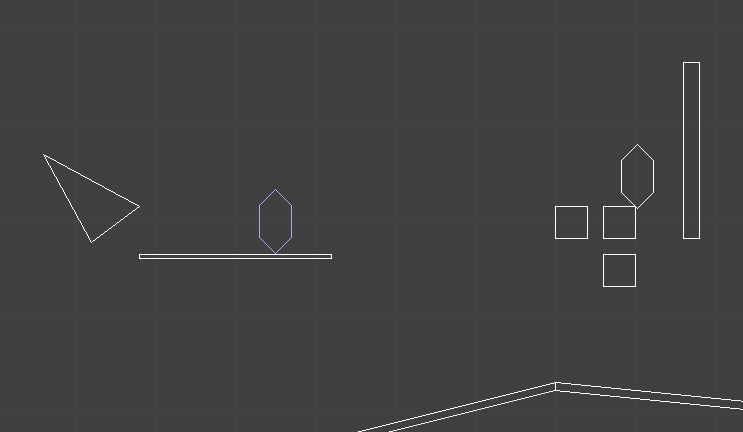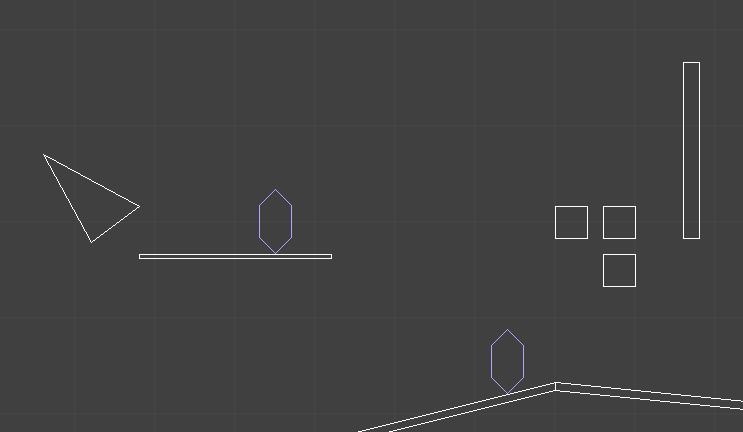In the previous post, I updated the sidescroller project with skeletal meshes — meshes that can be posed. In this post we animate those meshes.
As a fun fact, we’re about 4 months into this project and I’ve written about 5600 lines of code. It keeps piling up.
Animations
An animation defines where the \(m\) mesh vertices are as a function of time:
\[\vec{p}_i(t) \text{ for } i \text{ in } 1:m\]
That’s rather general, and would require specifying a whole lot of functions for a whole lot of mesh vertices. We’ll instead leverage the mesh skeletons from the last blog post, and define an animation using a series of poses, also called keyframes:
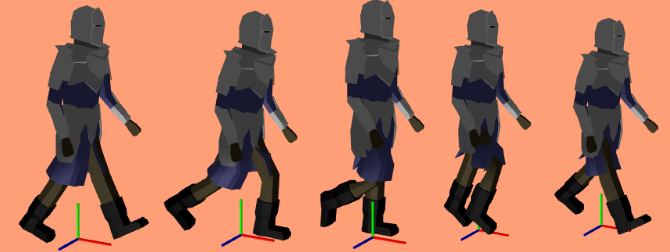
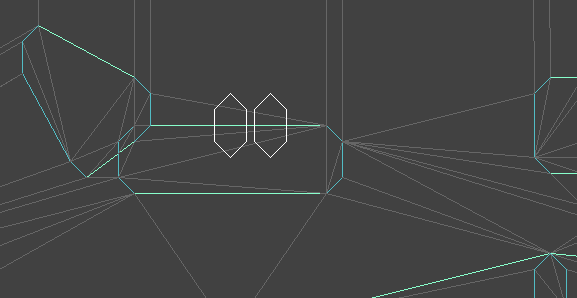
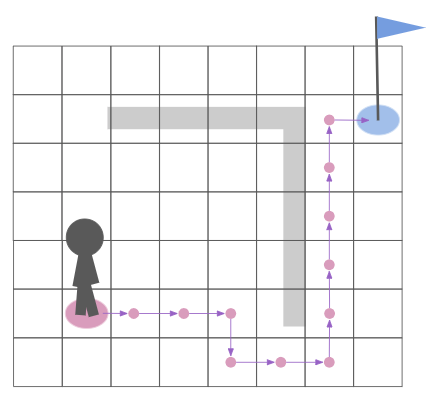
5 keyframes from the walk animation
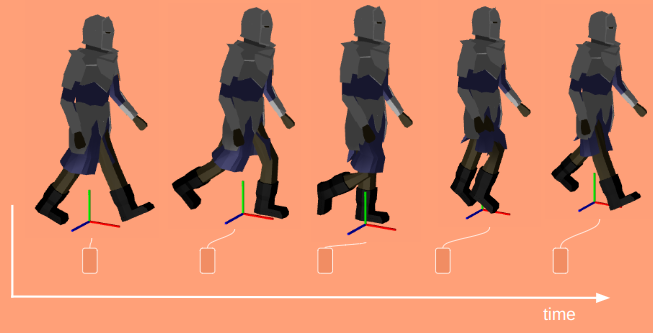
A single keyframe defines all of the bone transforms that pose the model in a certain way. A series of them acts like a series of still frames in a movie – they act as snapshots of the mesh’s motion over time:
When we’re in-between frames, we have to somehow interpolate between the surrounding frames. The simplest and most common method is linear interpolation, where we linearly blend between the frames based on the fraction of time we are between them:
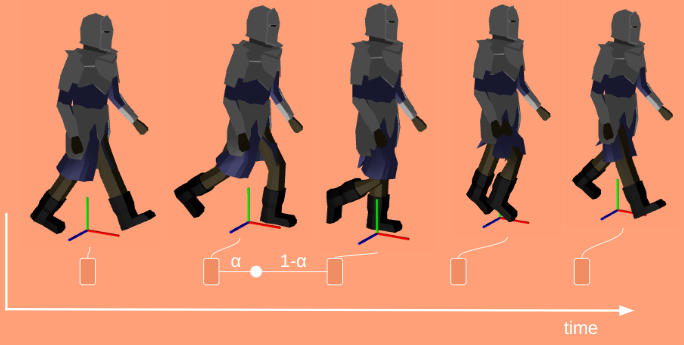
Here \(\alpha\) ranges from 0 at the previous frame and 1 at the next frame:
Each frame is a collection of bone transforms. We could interpolate between the transform matrices directly, but it is more common to decompose those into position \(\vec{p}\), orientation \(\vec{q}\), and scale \(\vec{s}\), and interpolate between those instead. If we’re a fraction \(\alpha\) between frames \(f^{(k)}\) and \(f^{(k+1)}\), then the transform components for the \(i\)th bone are:
You’ll notice that the position and scaling vectors use linear interpolation, but we’re using spherical linear interpolation for the rotation. This is why we decompose it – basic linear interpolation doesn’t work right for rotations.
Conceptually, animation is super simple. A keyframe just stores some components and a duration:
struct Keyframe {
f32 duration;
std::vector<glm::vec3> positions; // for each bone
std::vector<glm::quat> orientations;
std::vector<glm::vec3> scales;
};
and an Animation is just a named list of keyframes:
If you want a simple animation, you slap down some spaced-out frames and let interpolation handle what happens in-between. If you want a nice, detailed animation, you can fill out your animation with a higher density of frames, or define special interpolation methods or easing functions to give you a better effect.
Posing a mesh is as simple as interpolating the keyframes and then applying its transforms to the mesh. To do that, its useful to keep track of how long our animation has been playing, and which frames we’re between. To this end we define an AnimationIndex:
struct AnimationIndex {
f32 t_total; // elapsed time since the start of the animation
f32 t_frame; // elapsed time since the start of the current frame
int i_frame; // index of the current frame
};
Advancing the index requires updating our times and the frame index:
We can use our interpolated keyframe to pose our mesh:
void PoseMeshToAnimationFrame(
std::vector<glm::mat4>* bone_transforms_curr,
std::vector<glm::mat4>* bone_transforms_final,
const Mesh& mesh,
const Keyframe& frame)
{
size_t n_bones = bone_transforms_final->size();
for (size_t i_bone = 0; i_bone < n_bones; i_bone++) {
glm::vec3 pos = frame.positions[i_bone];
glm::quat ori = frame.orientations[i_bone];
glm::vec3 scale = frame.scales[i_bone];
// Compute the new current transform
glm::mat4 Sbone = glm::translate(glm::mat4(1.0f), pos);
Sbone = Sbone * glm::mat4_cast(ori);
Sbone = glm::scale(Sbone, scale);
// Incorporate the parent transform
if (mesh.bone_parents[i_bone] >= 0) {
const glm::mat4& Sparent =
(*bone_transforms_curr)[mesh.bone_parents[i_bone]];
Sbone = Sparent * Sbone;
}
// Store the result
const glm::mat4& Tinv = mesh.bone_transforms_orig[i_bone];
(*bone_transforms_curr)[i_bone] = Sbone;
(*bone_transforms_final)[i_bone] = Sbone * Tinv;
}
}
Adding Animations to the Game
Now that we have animations, we want to integrate them into the sidescroller game. We can do that!
These aren’t beautiful masterpieces or anything, since I clumsily made them myself, but hey – that’s scrappy do-it-to-learn-it gamedev.
We are now able to call StartAnimation on a RigComponent, specifying the name of the animation we want. For example, if the player loses contact with the ground, we can start either the falling or jumping animations with a code snippet like this:
if (!player_movable->support.is_supported) {
// Fall or Jump!
StartAnimation(player_rig, jump_pressed ? "jump" : "fall");
game->player_state_enum = PlayerActionState::AIRBORNE;
}
This looks up the requested animation and sets our animation index to its initial value.
There is one additional thing we need to get right. Instantaneously transitioning to a new animation can look jarring. Watch what happens here were I start punching in the air:
The knight’s legs suddenly snap to their idle positions!
What we’d like instead is to blend seamlessly from the pose the model is at when StartAnimation is called to the poses specified by the new animation. We can already blend between any two poses, so we just leverage that knowledge to blend between the initial pose and the animation pose.
We specify a fadeout time \(t_\text{fadeout}\) whenever we start a new animation. For the first \(t_\text{fadeout}\) seconds of our animation, we linearly interpolate between our initial pose based on how much time has elapsed. If we happen to start in a pose close to what the animation plays from, this effect won’t be all that noticeable. If we happen to start in a wildly different pose we’ll move the mesh over more naturally.
Editing Animations
Animations contain a lot of data. There a multiple frames and a bunch of things bones can do per frame. I didn’t want to specify those transforms in code, nor manually in some sort of textfile.
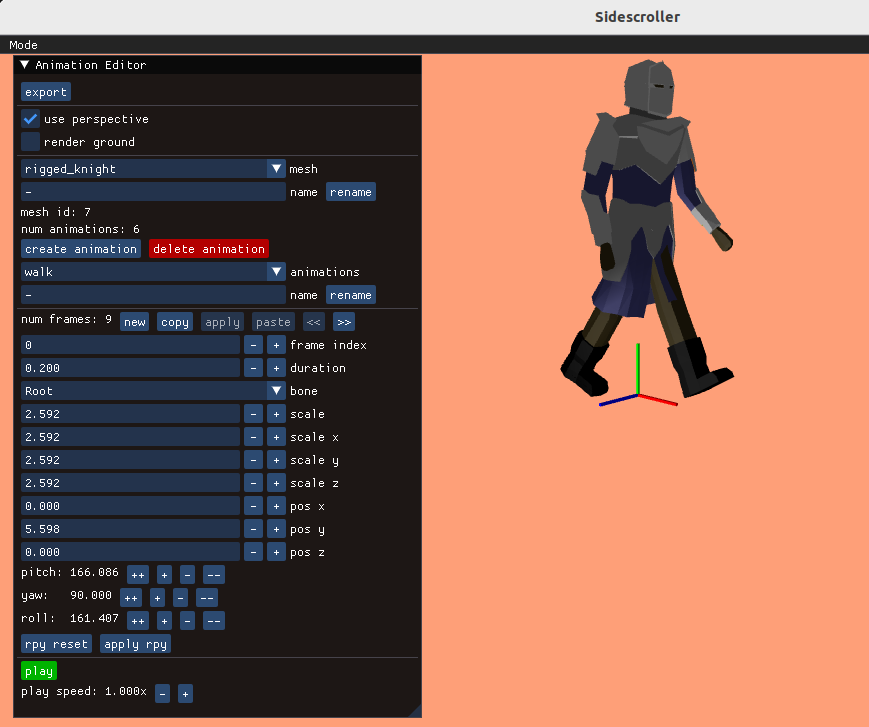
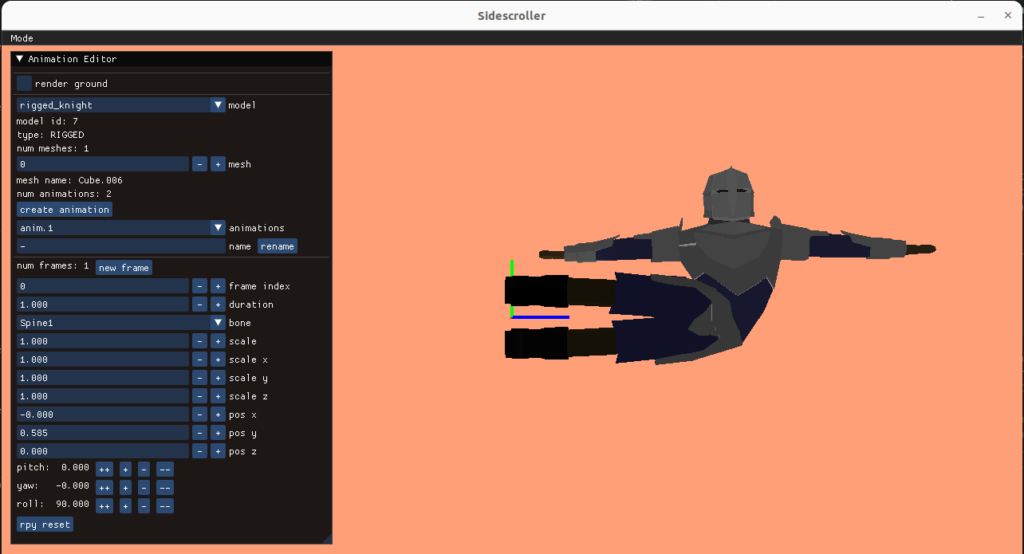
I made a basic animation editor using ImGUI and used that to craft my animations:
Its fairly rudimentary, but gets the job done.
One could argue that I should have stuck with Blender’s animation tools. There are a few advantages to rolling my own editor:
Blender doesn’t run on my Linux laptop and keeps crashing
My model format has somewhat departed from Blender’s
I want to be able to edit hitspheres and hurtspheres down the road
My objective is to learn, not turn a profit or release a real game
The right trade-off will of course depend on your unique situation.
Conclusion
Going from pose-able meshes to animations was mainly about figuring out how to tie a bunch of poses together over time. Now that we have that, and a way to cleanly transition between animations, we’re pretty much set.
Animations in big games can be a lot more complicated. We might have overlapping animations for various parts of a mesh, such as facial animations that play simultaneously with body-level animations. We could implement inverse kinematics to help with automatically placing our feet at natural stepping locations (or when climbing to grasp at natural handholds). There are a bunch of fancier techniques that give you tighter control over the mesh too, but at the core of it, what we did here covers the fundamentals.
Next I plan to work on a basic combat system and get some other entities into the game. In order for this to be a proper level, we kind of need that. And maybe we’ll do some ladders.
This month I’m continuing the work on the side scroller and moving from static meshes to meshes with animations. This is a fairly sizeable jump as it involves a whole host of new concepts, including bones and armatures, vertex painting, and interpolation between keyframes. For reference, the Skeletal Animation post on learnopengl.com prints out to about 16 pages. That’s a lot to learn. Writing my own post about it helps me make sure I understand the fundamentals well enough to explain them to someone else.
Moving Meshes
Our goal is to get our 3D meshes to move. This primarily means adding having the ability to make our player mesh move in prescribed ways, such as jumping, crouching, attacking, and climbing ladders.
So far we’ve been working with meshes, i.e. vertex and face data that forms our player character. We want those vertices to move around. Our animations will specify how those vertices move around. That is, where the \(m\) mesh vertices are as a function of time:
\[\vec{p}_i(t) \text{ for } i \text{ in } 1:m\]
Unfortunately, a given mesh has a lot of vertices. The low-poly knight model I’m using has more than 1.5k of them, and its relatively tiny. Specifying where each individual vertex goes over time would be an excessive amount of work.
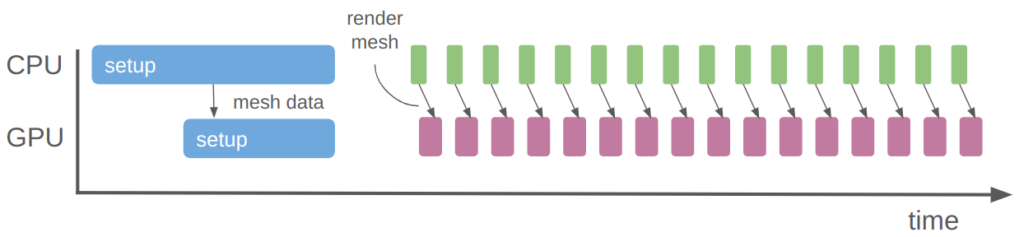
Not only would specifying an animation on a per-vertex level be a lot of work, it would be very slow. One of the primary advantages of a graphics card is that we can ship the data over at setup time and not have to send it all over again:
With the rendering we’re doing now, we just update a few small uniforms every frame to change the player position. The mesh data itself is already on the GPU, stored as a vertex buffer object.
So fully specifying the vertex positions over time is both extremely tedious and computationally expensive. What do we do instead?
When a character moves, many of their vertices typically move together. For example, if my character punches, we expect all of the vertices in their clenched fist to together, their forearm arm to follow. Their upper arm follows that, maybe with a bend, etc. Vertices thus tend to be grouped, and we can leverage the grouping for increased efficiency.
Bones
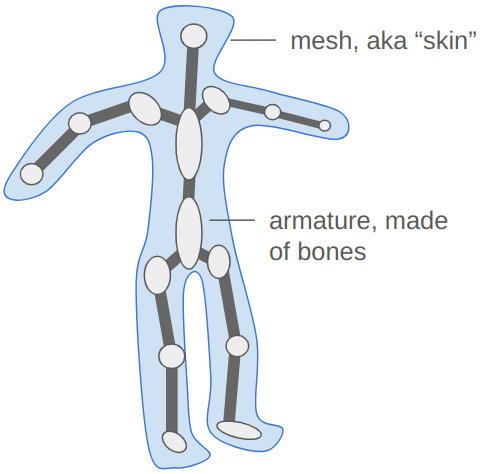
You know how artists sometimes have these wooden figures that they can bend and twist into poses? That’s the industry-standard way to do 3D animation.
We create an armature, which is a sort of rigid skeleton that we can use to pose the mesh. The armature is made up of rigid entities, bones, which can move around to produce the movement expected in our animation. There are far fewer bones than vertices. We then compute our vertex positions based on the bones positions – a vertex in the character’s fist is going to move with the fist bone.
This approach solves our problems. The bones are much easier to pose and thus build animations out of, and we can continue to send the mesh and necessary bone information to the GPU once at startup, and just send the updated bone poses whenever we render the mesh.
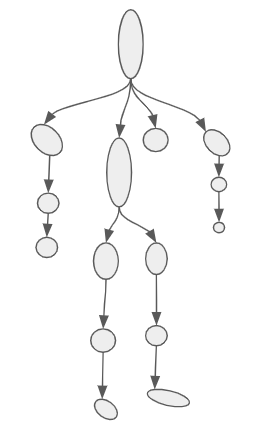
The bones in an armature have a hierarchical structure. Every bone has a single parent and any number of children, except the root bone, which has no parent.
Unlike my oh-so-fancy drawing, bones don’t actually take up space. They are actually just little reference frames. Each bone’s reference frame is given by a transformation \(T\) with respect to its parent. More specifically, \(T\) transforms a point in the bone’s frame to that of its parent.
For example, we can use this transform to get the “location” of a bone. We can get the position of the root bone by transforming the origin of its frame to its parent – the model frame. This is given by \(T_\text{root} \vec{o}\), where \(\vec{o}\) is the origin in homogenous coordinates: \([0,0,0,1]\). Our transforms use 4×4 matrices so that we can get translation, which is ubiquitous in 3D graphics.
Similarly, the position of one of the root bone’s children with transform \(T_\text{c}\) can be obtained by first computing its position in the root bone’s frame, \(T_\text{c} \vec{o}\), and then convert that to the model frame, \(T_\text{root} T_\text{c} \vec{o}\).
The order of operation matters! It is super important. It is what gives us the property that moving a leaf bone only affects that one bone, but moving a bone higher up in the hierarchy affects all child bones. If you ever can’t remember which order it is, and you can’t just quickly test it out in code, try composing two transforms together.
Let’s call the aggregated transform for bone \(c4\), this product of its ancestors, \(\mathbb{T}_{c4}\).
It is these transformations that we’ll be changing in order to produce animations. Before we get to that, we have to figure out how the vertices move with the bones.
Transforming a Vertex
The vertices are all defined in our mesh. They have positions in model-space.
Each bone has a position (and orientation) in model space, as we’ve already seen.
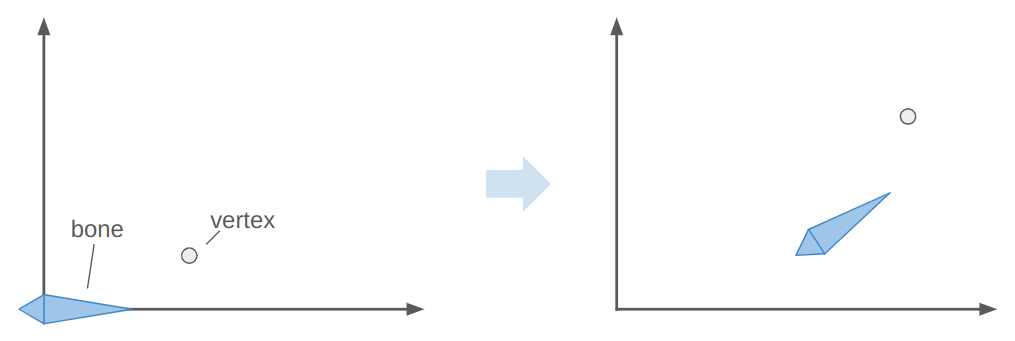
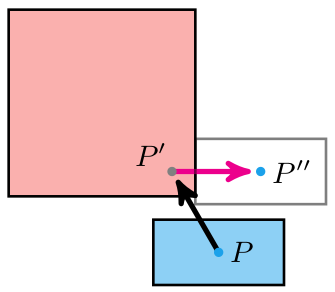
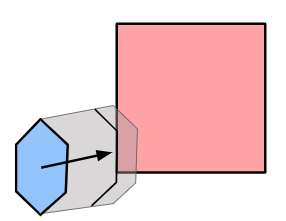
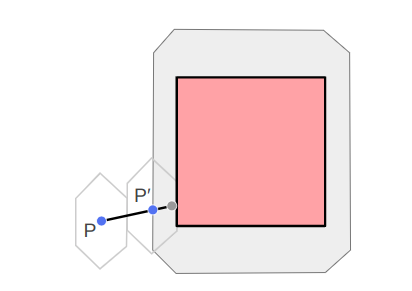
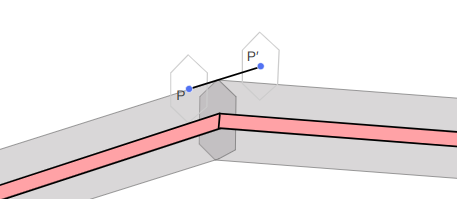
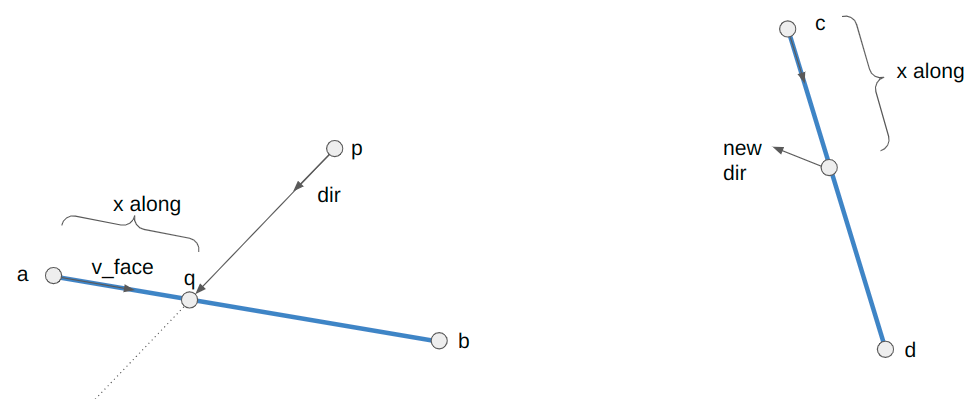
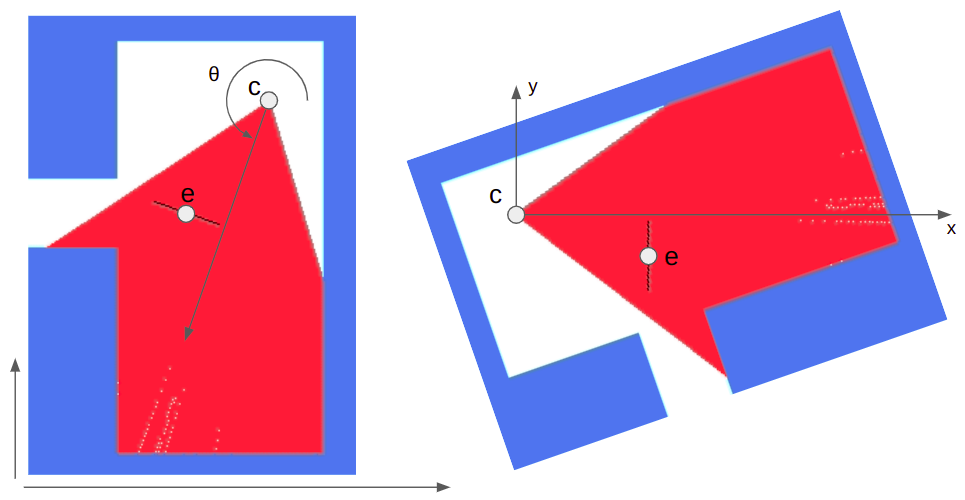
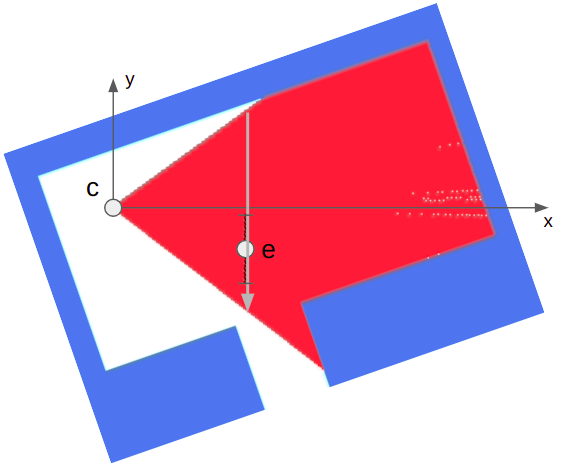
Let’s consider what happens when we associate a vertex with a bone. That is, we “connect” the vertex to the bone such that, if the bone moves, the vertex moves with it. We expect the vertex to move along in the bone’s local frame:
Here the bone both translates to the right and up, and rotates counter-clockwise about 30 degrees. In the image, the vertex does the same.
The image above has the bone starting off at the origin, with its axis aligned with the coordinate axes. This means the vertex is starting off in the bone’s reference frame. To get the vertex into the bone frame (it is originally defined in the model frame), we have to multiply it by \(\mathbb{T}^{-1}\). Intuitively, if \(\mathbb{T} \vec{p}\) takes a point from bone space to model space then the inverse takes a point from model space to bone space.
The bone moved. That means it has a new transform relative to its parent, \(S\). Plus, that parent bone may have moved, and so forth. We have to compute a new aggregate bone transform \(\mathbb{S}\). The updated position of the vertex in model space is thus obtained by transforming it from its original model space into bone space with \(\mathbb{T}^{-1}\) and then transforming it back to model space according to the new armature configuration with \(\mathbb{S}\):
\[\vec v’ = \mathbb{S} \mathbb{T}^{-1} \vec v\]
We can visualize this as moving a vertex in the original mesh pose to the bone-relative space, and then transforming it back to model-space based on the new armature pose:
This means we should store \(\mathbb{T}^{-1}\) for each bone in the armature – we’re going to need it a lot. In any given frame we’ll just have to compute \(\mathbb{S}\) by walking down the armature. We then compute \(\mathbb{S} \mathbb{T}^{-1}\) and pass that to our shader to properly pose the model.
Bone Weights
The previous section let us move a vertex associated with a single bone. That works okay for very blocky models composed of rigid segments. For example, a stocky robot or simple car with spinning wheels. Most models are less rigid. Yes, if you punch someone you want the vertices in your fist to follow the hand bone, but as you extend your elbow the vertices near the joint will follow both the bone from the upper arm and the bone from the lower arm. We want a way to allow this to happen.
Instead of a vertex being associated with one bone, we allow a vertex to be associated with multiple bones. We have the final vertex combination be a mix of any number of other bones:
where the nonnegative weights \(\vec w\) sum to one.
In practice, most vertices are associated with one one or two bones. It is common to allow up to 4 bone associations, simply because that covers most needs and then we can use the 4-dimensional vector types supported by OpenGL.
Data-wise, what this means is:
In addition to the original mesh data, we also need to provide an armature, which is a hierarchy of bones and their relative transformations.
We also need to associate each vertex with some set of bones. This is typically done via a vec4 of weights and an ivec4 of bone indices. We store these alongside the other vertex data.
The vertex data is typically static and can be stored on the graphics card in the vertex array buffer.
We compute the inverse bone transforms for the original armature pose on startup.
When we want to render a model, we pose the bones, compute the current bone transforms \(\mathbb{S}\), and then compute and sent \(\mathbb{S} \mathbb{T}^{-1}\) to the shader as a uniform.
Coding it Up
Alright, enough talk. How do we get this implemented?
We start by updating our definition for a vertex. In addition to the position, normal, and texture coordinates, we now also store the bone weights:
struct RiggedVertex {
glm::vec3 position; // location
glm::vec3 normal; // normal vector
glm::vec2 tex_coord; // texture coordinate
// Up to 4 bones can contribute to a particular vertex
// Unused bones must have zero weight
glm::ivec4 bone_ids;
glm::vec4 bone_weights;
};
This means we have to update how we set up the vertex buffer object:
Note the use of glVertexAttribIPointer instead of glEnableVertexAttribArray for the bone ids. That problem took me many hours to figure out. It turns out that glVertexAttribPointer accepts integers but has the card interpret them as floating point, which messes everything up it you indent to actually use integers on the shader side.
As far as our shader goes, we are only changing where the vertices are located, not how they are colored. As such, we only need to update our vertex shader (not the fragment shader). The new shader is:
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aNormal;
layout (location = 2) in vec2 aTexCoord;
layout (location = 3) in ivec4 aBoneIds;
layout (location = 4) in vec4 aBoneWeights;
out vec3 pos_world;
out vec3 normal_world;
out vec2 tex_coords;
const int MAX_BONES = 100;
const int MAX_BONE_INFLUENCE = 4;
uniform mat4 model; // transform from model to world space
uniform mat4 view; // transform from world to view space
uniform mat4 projection; // transform from view space to clip space
uniform mat4 bone_transforms[MAX_BONES]; // S*Tinv for each bone
void main()
{
// Accumulate the position over the bones, in model space
vec4 pos_model = vec4(0.0f);
vec3 normal_model = vec3(0.0f);
for(int i = 0 ; i < MAX_BONE_INFLUENCE; i++)
{
j = aBoneIds[i];
w = aBoneWeights[j]
STinv = bone_transforms[j];
pos_model += w*(STinv*vec4(aPos,1.0f));
normal_model += w*(mat3(STinv)*aNormal);
}
pos_world = vec3(model * pos_model);
normal_world = mat3(model) * normal_model;
gl_Position = projection * view * model * pos_model;
tex_coords = vec2(aTexCoord.x, 1.0 - aTexCoord.y);
}
Note that the normal vector doesn’t get translated, so we only use mat3. The vertice’s texture coordinate is not affected.
Testing it Out
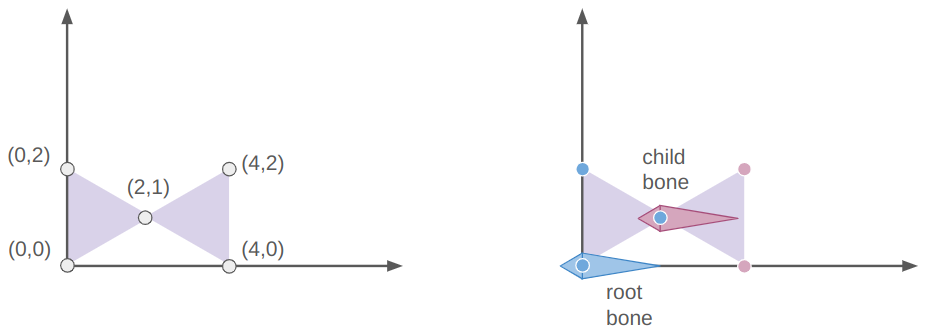
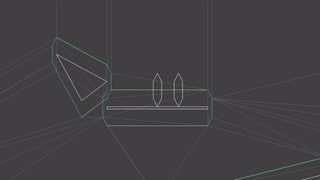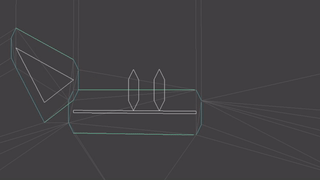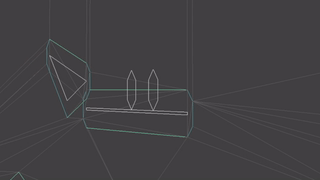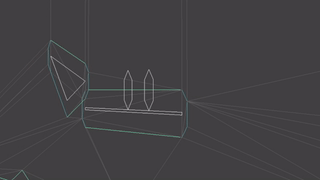
Let’s start with something simple, a 2-triangle, 2-bone system with 5 vertices:
The root bone is at the origin (via the identity transform) and the child bone is at [2,1,0]. The vertices of the left triangle are all associated only with the root bone and the rightmost two vertices are only associated with the child bone.
If we slap on a sin transform for the child bone, we wave the right triangle:
If we instead slap a sin transform on the root bone, we wave both triangles as a rigid unit:
We can apply a sin to both triangles, in which case the motions compose like they do if you bend both your upper and lower arms:
We can build a longer segmented arm and move each segment a bit differently:
Posing a Model
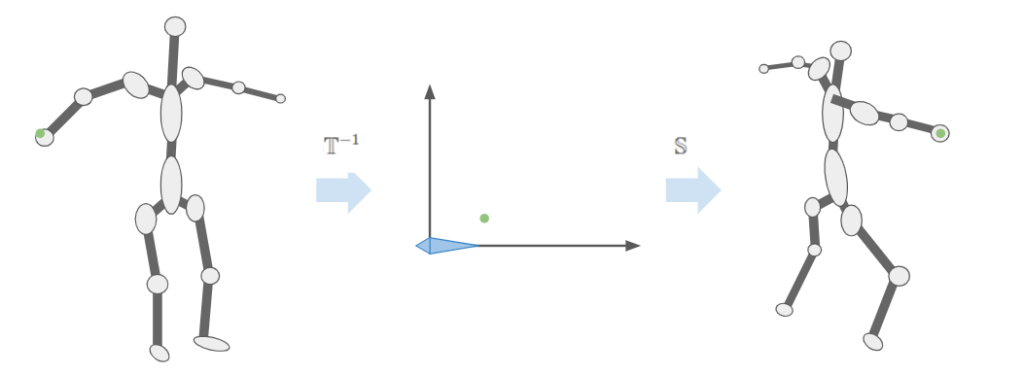
Now that we’ve built up some confidence in our math, we can start posing our model (The low-poly knight by Davmid, available here on Sketchfab) The ideas are exactly the same – we load the model, define some bone transforms, and then use those bone transforms to render its location.
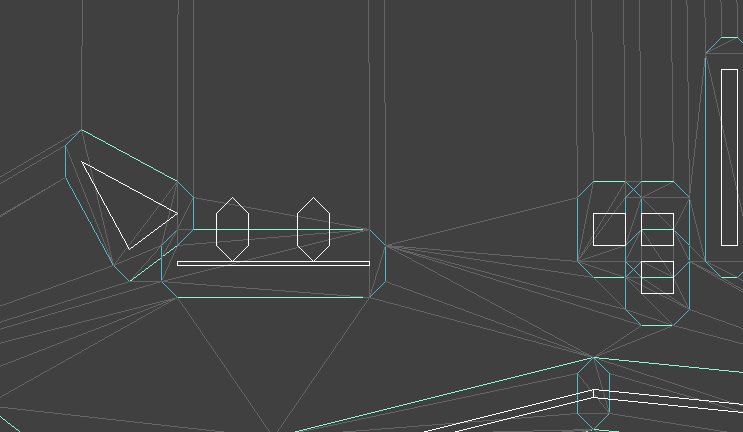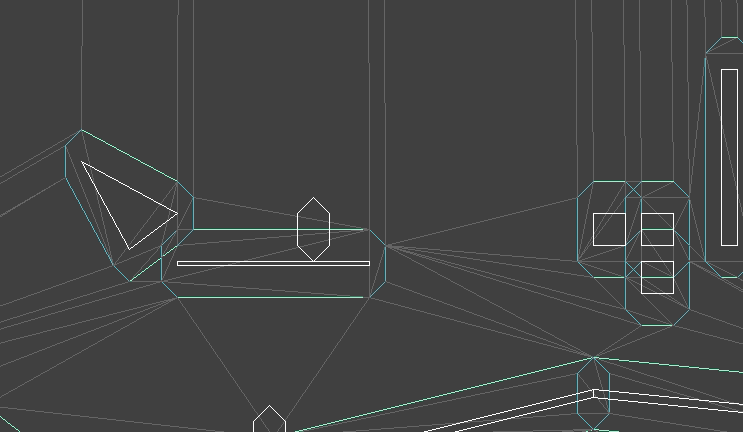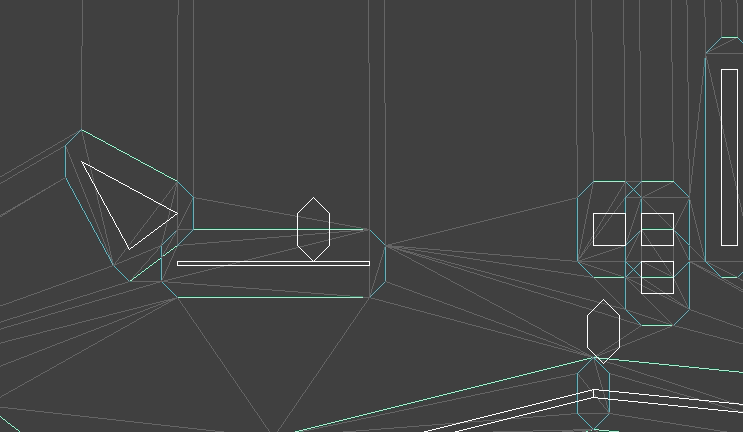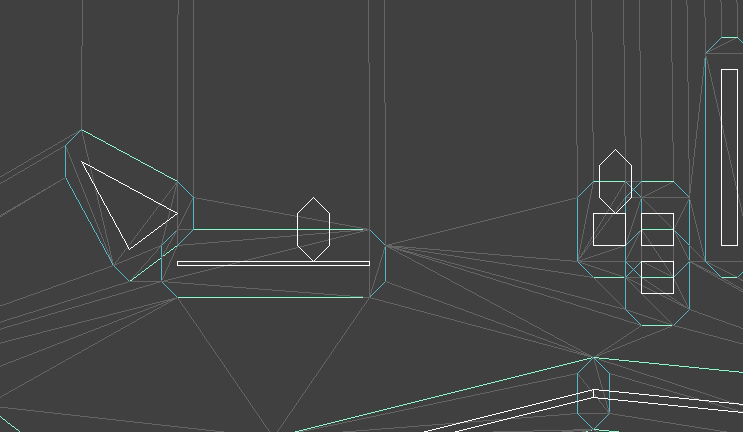
I created an animation editing mode that lets us do this posing. As before, the UI stuff is all done with Dear ImGUI. It lets you select your model, add animations, add frames to those animations, and adjust the bone transforms:
A single frame represents an overall model pose by defining the transformations for each bone:
The position, orientation, and scale are stored separately, mainly because it is easier to reason about them when they are broken out like this. Later, when we do animation, we’ll have to interpolate between frames, and it is also easier to reason about interpolation between these components rather than between the overall transforms. A bone’s local transform \(S\) is simply the combination of its position, orientation, and scale.
We calculate our fine bone transforms \(\mathbb{S} \mathbb{T}^{-1}\) for our frame and then pass that off to the shader for rendering:
When you get down to it, the math behind rigged meshes isn’t all too bad. The main idea is that you have bones with transforms relative to their parent bone, and that vertices are associated with a combination of bones. You have to implement rigged meshes that store your bones and vertex weights, need a shader for rigged meshes, and a way to represent your model pose.
This main stuff doesn’t take too long to implement in theory, but this post took me way longer to develop than normal because I wrote a bunch of other supporting code (plus banged my head against the wall when things didn’t initially work – its hard to debug a garbled mess).
Adding my own animation editor meant I probably wanted to save those animations to disk. That meant I probably wanted to save my meshes to disk too, which meant saving the models, textures, and materials. Getting all that set up took time, and its own fair share of debugging. (I’m using a WAD-like data structure like I did for TOOM).
The animation editor also took some work. Dear ImGUI makes writing UI code a lot easier, but adding all of the widgets and restructuring a lot of my code to be able to have separate application modes for things like gameplay and the animation editor simply took time. The largest time suck (and hit to motivation) for a larger project like this is knowing you have to refactor a large chunk of it to make forward progress. Its great to reach the other end though and to have something that makes sense.
We’re all set up with posable models now, so the next step is to render animations. Once that’s possible we’ll be able to tie those animations to the gameplay — have the model walk, jump, and stab accordingly. We’ll then be able to attach other meshes to our models, i.e. a sword to its hand, and tie hitspheres and hurtspheres to the animation, which will form the core of our combat system.
In the previous post I introduced a new side scroller project, and laid out some of the things I wanted to accomplish with it. One of those points was to render with the graphics card. I had never worked directly with 3D assets and graphics cards before. Unless some high-level API was doing rendering for me under the hood, I wasn’t harnessing the power of modern graphics pipelines.
For TOOM I was not using the graphics card. In fact, the whole point of TOOM was to write a software renderer, which only uses the CPU for graphics. That was a great learning experience, but there is a reason that graphics cards exist, and that reason pretty much is that software renderers spend a lot of time rendering pixels when it’d be a lot nicer to hand that work off to something that can churn through it more efficiently.
Before starting, I thought that learning to render with the graphics card would more-or-less boil down to calling render(mesh). I assumed the bulk of the benefit would be faster calls. What I did not anticipate was learning how rich render pipelines can be, with customized shaders and data formats opening up a whole world of neat possibilities. I love it when building a basic understanding of something suddenly causes all sorts of other things to click. For example, CUDA used to be an abstract, scary performance thing that only super smart programmers would do. Now that I know a few things, I can conceptualize how it works. It is a pretty nice feeling.
Learning OpenGL
I learned OpenGL the way many people do. I went to learnopengl.com and followed their wonderful tutorials. It took some doing, and it was somewhat onerous, but it was well worth it. The chapters are well laid out and gradually build up concepts.
This process had me install a few additional libraries. First off, I learned that one does not commonly directly use OpenGL. It involves a bunch of function pointers corresponding to various OpenGL versions, and getting the right function pointers from the graphics driver can be rather tedious. Thus, one uses a service like GLAD to generate the necessary code for you.
As recommended by the tutorials, I am using stb_image by the legendary Sean Barrett for loading images for textures, and assimp for loading 3D asset files. I still find it hilarious that they can get away with basically calling that last one Butt Devil. Lastly, I’m using the OpenGL mathematics library (glm) for math types compatible with OpenGL. I am still using SDL2 but switched to the imgui_impl_opengl3 backend. These were all pretty easy to use and install — the tutorials go a long way and the rest is pretty self-explanatory.
I did run into an issue with OpenGL where I didn’t have a graphics driver new enough to support the version that learnopengl was using (3.3). I ended up being able to resolve it by updating my OS to Ubuntu 22.04. I had not upgraded in about 4 years on account of relying on this machine to compile thetextbooks, but given that they’re out I felt I didn’t have to be so paranoid anymore.
In the end, updating to Jammy Jellyfish was pretty easy, except it broke all of my screen capture software. I previously used Shutter and Peek to take screenshots and capture GIFs. Apparently that all went away with Wayland, and now I need to give Flameshot permission every time I take a screenshot and I didn’t have any solution for GIF recordings, even if login with Xorg.
In writing this post I buckled down and tried Kooha again, which tries to record but then hangs forever on save (like Peek). I ended up installing OBS Studio, recording a .mp4, and then converting that to a GIF in the terminal via ffmpeg:
This was only possible because of this excellent stack overflow answer and this OBS blog post. The resulting quality is actually a lot better than Peek, and I’m finding I have to adjust some settings to make the file size reasonable. I suppose its nice to be in control, but I really liked Peek’s convenience.
Moving to 3D
The side scroller logic was all done in a 2D space, but now rendering can happen in 3D. The side scroller game logic will largely remain 2D – the player entities will continue to move around 2D world geometry:
but that 2D world geometry all exists at depth \(z=0\) with respect to a perspective-enabled camera:
Conceptually, this is actually somewhat more complicated than simply calling DrawLine for each edge, which is what I was doing before via SDL2:
for edge in mesh
DrawLine(edge)
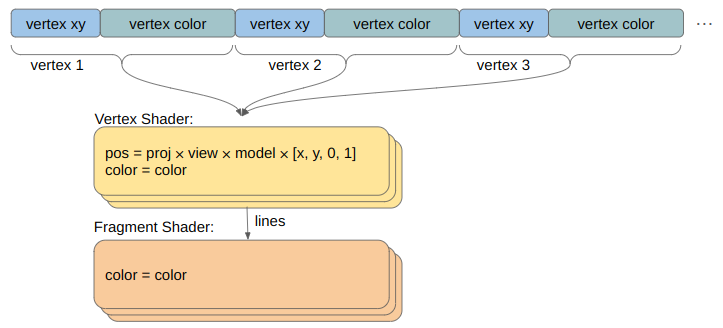
Rendering in 3D requires:
setting up a vertex buffer and filling it with my mesh data, including color
telling OpenGL how to interpret said data
using a vertex shader that takes the position and color attributes and transforms them via the camera transformations into screen space
using a dead-simple fragment shader that just passes on the received vertex colors
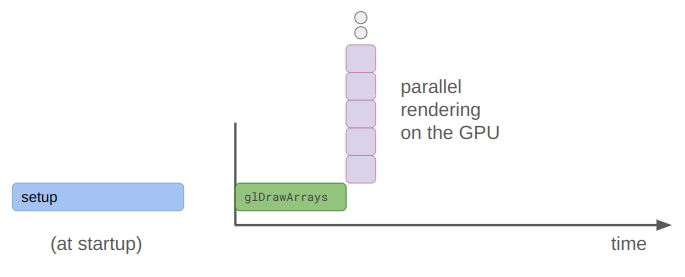
calling glDrawArrays with GL_LINES to execute all of this machinery
This is not hard to do per se, but it is more complicated. One nice consequence is that there is only a single draw call for all this mesh data rather than a bunch of independent line draw calls. The GPU then crunches it all in parallel:
The coordinate transforms for this are basically what learnopengl recommends:
an identity model matrix since the 2D mesh data is already in the world frame
a view matrix obtained via glm::lookat based on a camera position and orientation
a projection matrix obtained via glm::perspective with a 45-degree viewing angle, our window’s aspect ratio, and \(z\) bounds between 0.1 and 100:
This setup worked great to get to parity with the debug line drawing I was doing before, but I wanted to be using OpenGL for some real mesh rendering. I ended up defining two shader programs in addition to the debug-line-drawing one: one for textured meshes and one for material-based meshes. I am now able to render 3D meshes!
This low-poly knight was created by Davmid, and is available here on Sketchfab. The rest of the assets I actually made myself in Blender and exported to FBX. I had never used Blender before. Yeah, its been quite a month of learning new tools.
The recording above also includes a flashlight effect. This was of course based on the learnopengl tutorials too.
Rendering with shaders adds a ton of additional options for effects, but also comes with a lot of decisions and tradeoffs around how data is stored. I would like to simplify my approach and end up with as few shaders as possible. For now its easiest for me to make models in Blender with basic materials, but maybe I can move the material definitions to a super-low-res texture (i.e., one pixel per material) and then only use textured models.
Architecture
It is perhaps worth taking a step back to talk about how this stuff is architected. That is, how the data structures are arranged. As projects get bigger, it is easier to get lost in the confusion, and a little organization goes a long way.
First off, the 3D stuff is mostly cosmetic. It exists to look good. It is thus largely separate from the underlying game logic:
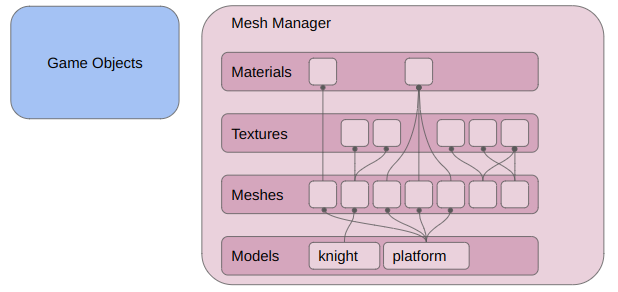
I created a MeshManager class that is responsible for storing my mesh-related data. It currently keeps track of four things:
Materials – color properties for untextured meshes
Textures – diffuse and specular maps for textured meshes
Meshes – the 3D data associated with a single material or texture
Models – a named 3D asset that consists of 1 or more meshes
struct Material {
std::string name;
glm::vec3 diffuse; // diffuse color
glm::vec3 specular; // specular color
f32 shininess; // The exponent in the Phong specular equation
};
struct Texture {
GLuint id; // The OpenGL texture id
std::string filepath; // This is essentially its id
};
struct Mesh {
std::string name; // The mesh name
std::vector<Vertex> vertices;
// Indices into `vertices` that form our mesh triangles
std::vector<u32> indices;
// An untextured mesh has a single material, typemax if none.
// If the original mesh has multiple materials,
// the assimp import process splits them.
u16 material_id;
// A textured mesh has both a diffuse and a specular texture
// (typemax if none)
u16 diffuse_texture_id;
u16 specular_texture_id;
GLuint vao; // The OpenGL vertex array object id
GLuint vbo; // The OpenGL vertex buffer id associated with `vertices`
GLuint ebo; // The element array buffer associated with `indices`
};
struct Model {
std::string filepath; // The filepath for the loaded model
std::string name; // The name of the loaded model
std::vector<u16> mesh_ids; // All mesh ids
};
Visually, this amounts to:
All of this data can be loaded from the FBX files via assimp. In the future, I’ll also be writing this data out and back in via my own game data format.
My game objects are currently somewhat of a mess. I have an EntityManager that maintains a set of entities:
struct Entity {
u32 uid; // Unique entity id
u32 flags;
common::Vec2f pos; // Position in gamespace
// A dual quarter edge for the face containing this position
core::QuarterEdgeIndex qe_dual;
u16 movable_id; // The movable id, or 0xFFFF otherwise
u16 collider_id; // The collider id, or 0xFFFF otherwise
};
Entities have unique ids and contain ids for the various resources they might be associated with. For now this includes a movable id and a collider id. I keep those in their own managers as well.
A movable provides information around how an entity is moving. Right now it is just just a velocity vector and some information about what the entity is standing on.
A collider is a convex polygon that represents the entity’s shape with respect to collision with the 2D game world:
The player is the only entity that currently does anything, and there is only one collider size from which the Delaunay mesh is built. I’ll be cleaning up the entity system in the future, but you can see where its headed – it is a basic entity component system.
Editing Assets
I want to use these meshes to decorate my game levels. While I could theoretically create a level mesh in Blender, I would much prefer to be able to edit the levels in-game using smaller mesh components.
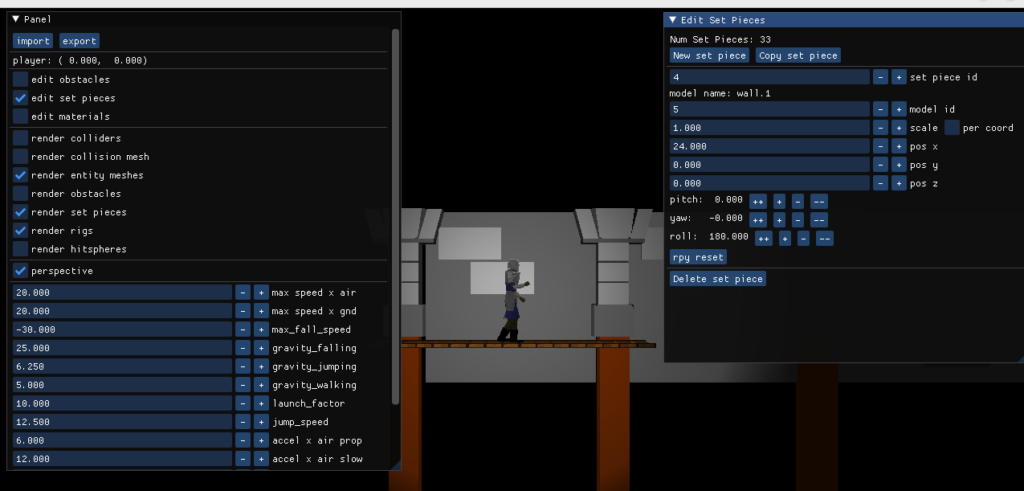
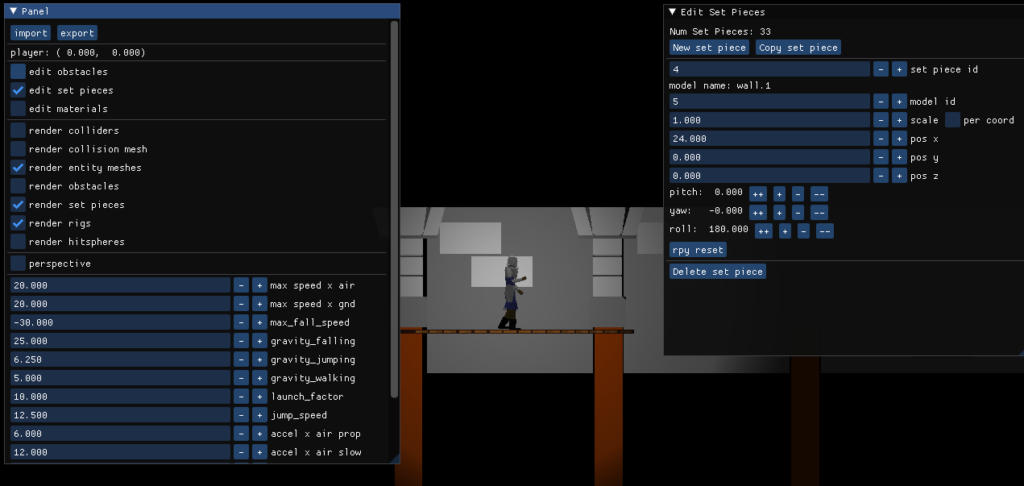
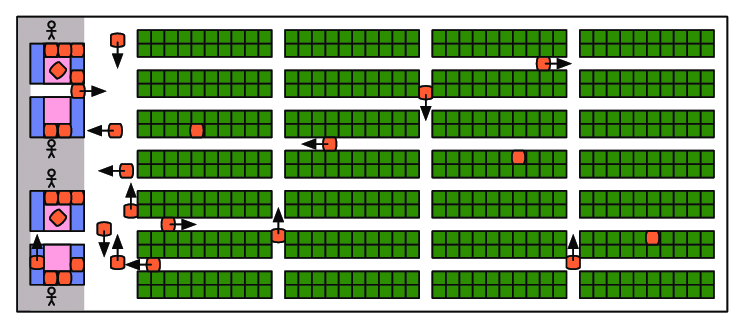
I created a very basic version of this using ImGUI wherein one can create and edit a list of set pieces:
This is leaps and bounds better than editing the level using a text file, or worse, hard-coding it. At the same time, it is pretty basic. I don’t highlight the selected set piece, I don’t have mouse events hooked up for click and drag, and my camera controls aren’t amazing. I do have some camera controls though! And I can set the camera to orthographic, which helps a lot:
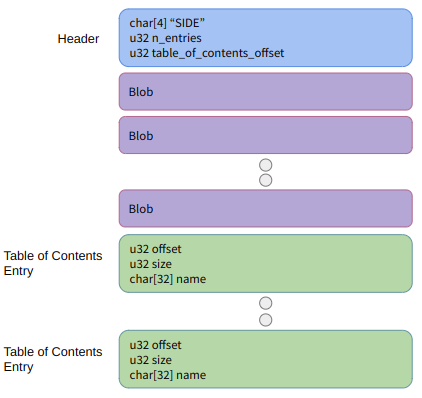
The inclusion of this set piece editor meant that I needed a way to save and load game data. (You can see the import and export buttons on the top-left). I went with the same WAD-file-like approach that I used for TOOM, which is a binary finally consisting of a basic header, a list of binary blobs, followed by a table of contents:
Each blob consists of a name and a bunch of data. It is up to me to define how to serialize or deserialize the data associated with a particular blob type. Many of them just end up being a u32 count followed by a list of structs.
One nice result of using a WAD-like binary is that I don’t always have to copy the data out to another data structure. With TOOM, I was copying things out in the C++ editor but was referencing the data as-is directly from the binary in the C code that executed the game. Later down the road I’ll probably do something similar with a baked version of the assets that the game can refer to.
There are some tradeoffs. Binary files are basically impossible to edit manually. Adding new blob types doesn’t invalidate old save files, but changing how a blob type is serialized or deserialized does. I could add versions, but as a solo developer I haven’t found the need for it yet. I usually update the export method first, run my program and load using the old import method, export with the new method, and then update my import method. This is a little cumbersome but works.
With TOOM I would keep loading and overwriting a single binary file. This was fine, but I was worried that if I ever accidentally corrupted it, I would have a hard time recreating all of my assets. With this project I decided to export new files every time. I have a little export directory and append the timestamp to the filename, ex: sidescroller_2023_12_22_21_28_55.bin. I’m currently loading the most recent one every time, but I still have older ones available if I ever bork things.
Conclusion
This post was a little less targeted than normal. I usually talk about how a specific thing works. In this case, I didn’t want to re-hash how OpenGL works, and instead covered a somewhat broad range of things I learned and did while adding meshes to my game project. A lot of things in gamedev are connected, and by doing it I’m learning what the implications of various decisions are and oftentimes, why things are as they are.
There are a lot of concepts to learn and tools to use. The last month involved:
OpenGL
GLAD
assimp
stb_image
Blender
OBS Studio
textures
Phong lighting
shaders
…
I am often struck by how something foreign and arcane like using a GPU seems mysterious and hard to do from the outset, but once you dive in you can pull back the curtains and figure it out. Sure, I still have a ton to learn, but the shape of the thing is there, and I can already do things with it.
With TOOM‘done’Or rather, as done as I want it to be., I found myself wanting to try something new. So, I started a new vscode workspace and embarked on a new side project – a 2D side scroller.
My overarching goal, once again, is to explore and take it as far as I find it interesting. That being said, I want to overcome the challenge of building a stable game with general 2D physics. By that I mean, “vectorial” physics of the sort used by Braid, with arbitrary 2D level geometry:
One reason for this goal is that I’ve tried to noodle it out before, but was surprised to find a significant lack of resources. In fact, I had to laugh out loud when I read this excellent heavily cited blog post about 2D platformers. It covers tile-based and rastered platforms in great detail, only to leave vectorial platformers with a vague “you do it yourself” and a warning not to use a physics engine. Well, challenge accepted! Let’s get into it!
There are a few other things I want to learn from this adventure. I plan to eventually use 3D GPU-accelerated graphics. Its worth knowing how that works, and the work on TOOM convinced me that drawing with the CPU is super slow. The aesthetic I have in mind is pretty low-poly, so while I’d normally go with pixel art because that’s all I can reasonably attempt myself, I nevertheless want to give 3D a try. The other big reason to go with 3D is that I can build an animation system and animate characters once rather than 8x for the various viewing angles. I was wanting to build a skeletal animation system, but felt that 2D skeletal animation systems very easily feel flat without serious artistic effort.
The general image I have in my mind is a souls-like 2D platformer with movement and combat somewhat similar to playing Link in Super Smash, except with some additional movement mechanics like ladders and other climbable surfaces and no bubble shield. It’ll probably never be a full game but maybe I can make a proper level and boss at the end.
I’ll be using C++ and vscode for this, on Linux. I’ll try to minimize library use, but will leverage SDL2 as my platform library and probably OpenGL for 3D graphics. I love ImGui and will use that for dev UI.
What I tried first Didn’t Work
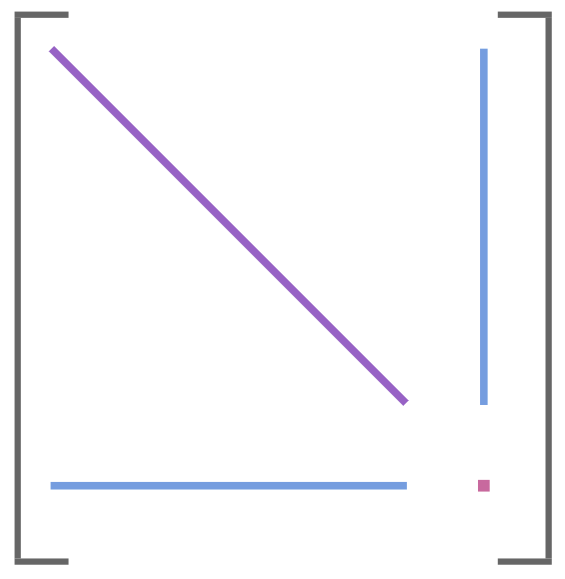
When I first started, I tried to go with an object system where the world is made of convex polygonal colliders. Seems reasonable:
The player (and one enemy) have colliders represented by these six-sided shapes. The white polygons are static geometry. So far so good.
When an entity moves, it ticks forward by \(\Delta t\). I could have done this the boring way by:
Moving the entity its full distance
Checking for collisions
Shunting the entity out of any colliding polygons
I’ve written about why this is a bad idea. In short, this approach can cause tunneling or other weird physics effects, especially when the entity is moving fast or when there are multiple intersecting bodies.
The system I implemented sought to instead find the first collision. This is the same as taking the source polygon and sweeping it along the direction of travel and finding the longest sweep \(\delta t \in [0, \Delta t]\) that does not intersect anything:
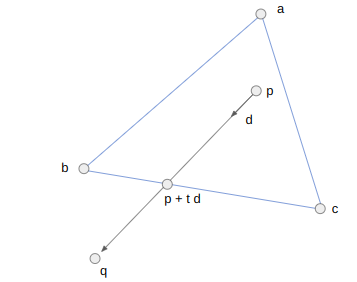
This sweeping method is harder to formulate. We aren’t really colliding the player’s collider with each static collider. Instead, we are colliding the swept player collider with each static colliderWe can use a broad collision phase narrow down to a small number of local potential colliders., but we still want to back out the maximum step we can take in our direction of motion. So we’re effectively sweeping the player collider along \(\Delta t \cdot \boldsymbol{v}\) and then checking for collisions, and we have to find the smallest \(\delta t\) such that the volume swept along \(\delta t \cdot \boldsymbol{v}\) does not collide.
The way I implemented that was to fall back to our trusty strategy of using the Minkowski sumWhich is really a Minkowski difference.. That is, we can expand the other polygon by the player’s collision volume first, and then all we have to do is check whether the line segment between the player’s starting location and that location shifted by \(\Delta t \cdot \boldsymbol{v}\) intersects with the polygon:
That mostly worked. It just has a lot of trouble with corner cases. For example, when the player is standing on a surface and we’re traveling along it. We don’t want floating point errors to accidentally place the player inside the supporting polygon. This was particularly problematic in the gameplay gif above, where the player ends up wedged between two squares and slides through one of them.
I had a lot of trouble with walking. I wanted the player to be able to walk across colliders along the floor without treating it like a ramp and launching off for a bit:
This means we have to do some hacky checks to figure out when we’re walking along a polygon and reach its end, and may need to transition to walking along a new polygon. I tried getting this all to work reliably, and got pretty far, but ultimately the number of hacks I had to add made the system untenable and left a bad taste in my mouth.
Redesign
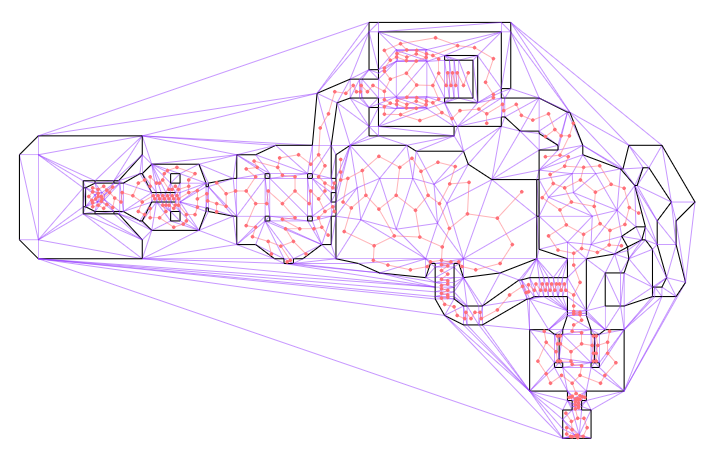
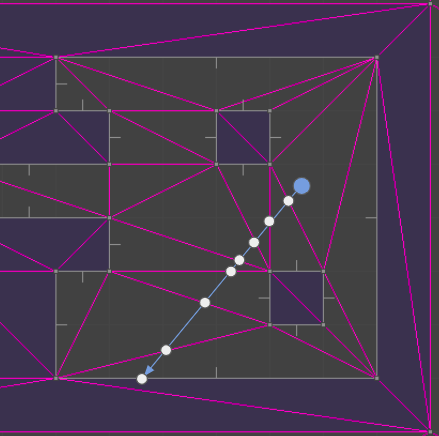
The fundamental problem is that my previous system was fully continuous, but that continuity inherently had issues with floating point effects when the player is supported by geometry. In these cases, we want something more discrete that can concretely tell us which side of the geometry we are on. Furthermore, I wanted something that could more easily tell me whether, when walking along a surface, there was another surface to walk on after passing the end of the current segment. These thoughts lead me to the trusty Delaunay mesh data structure.
I’ve written blog posts that use constrained Delaunay meshes (aka DCELs) a fewtimesnow. Now that I know this data structure exists, I keep finding uses for it.
Delaunay meshes are triangle meshes in which we try to keep the triangles as equilateral as possible (to avoid very fractured / long and narrow tiles). Constrained Delaunay meshes are the same thing, except we force certain edges to exist. This makes these meshes useful for things like representing map geometry, where we force walls to be edges in the mesh:
The E1M1 map from DOOM, after I’ve loaded it into a constrained Delaunay mesh
I actually advised that one use constrained Delaunay meshes for 2D player movement in this previous blog post. I hadn’t initially followed my own suggestion because the mesh is dependent on both the level geometry and the player collider (each polygon is expanded by the player collider via a Minkowski sum). If the player ducks and their collider shrinks, then we have to change our mesh. If an enemy has a different sized collider, then it should use a different mesh. If a piece of level geometry moves, such as a platform or door, then we need to change the mesh. All of these problems are still problems, but I’ll have to find workarounds for them. Nevertheless, I’m going with exactly what I spelled out in that earlier blog post.
My new plan was to keep track of both the player’s position and the triangle the collision mesh that they find themselves in. The collision mesh already accounts for the player’s collision volume, so we need only keep track of their center position. When they move, we check to see if their motion would take then out of their containing triangle, and if it does, we handle collisions (if necessary) at the crossed edge.
Here we see the updated system, along with the collision mesh.
Building the Mesh
Since I’ve covered how the movement works before, I’d rather focus on how we get the mesh.
This mesh is obtained by expanding each polygon by the player’s collision volume, and then adding all resulting edges to the Delaunay mesh. These edges are constrained to ensure that they remain in the final mesh (otherwise, we might flip edges in order to make them more equilateral). The main difficulty arises in the fact that the edges of the expanded polygons may intersect, and we nevertheless have to support them in our final mesh:
For example, these expanded polygons overlap.
I had previously tackled this using polygon unions via Clipper2. I could do that again, but want to avoid the loss of information that comes with replacing two or more overlapping polygons with a single polygon. For example, I might want to know which feature my player is standing on. For example, I may end up wanting to support removing objects. Plus, figuring out my own solution is a reward unto itself.
What I ended up doing was updating my method for constraining edges in a DCEL. During the development of TOOM, I had made it possible to load the DOOM level geometry and constrain the appropriate edges. Here we just added sides as we went, and constrained them after adding them:
for (Linedef linedef : linedefs) {
// Insert vertex a and b.
for (i16 i_vertex : {linedef.i_vertex_start, linedef.i_vertex_end}) {
const common::Vec2f& v = doom_vertices[i_vertex];
InsertVertexResult res = mesh.InsertVertex(v);
if (res.category == IN_FACE || res.category == ON_EDGE) {
mesh.EnforceLocallyDelaunay(res.i_qe);
vertex_indices[i_vertex] = mesh.GetVertexIndex(res.i_qe);
}
}
// Now ensure that there is a line between A and B.
// If there is not, flip edges until there is.
QuarterEdgeIndex qe_a =
mesh.GetQuarterEdge(vertex_indices[linedef.i_vertex_start]);
QuarterEdgeIndex qe_b =
mesh.GetQuarterEdge(vertex_indices[linedef.i_vertex_end]);
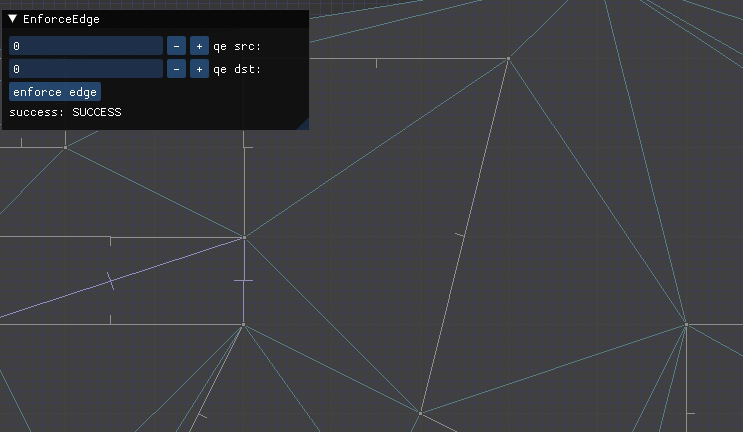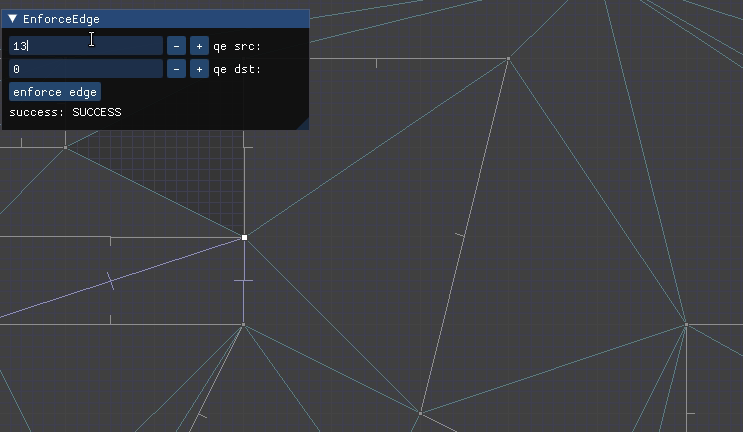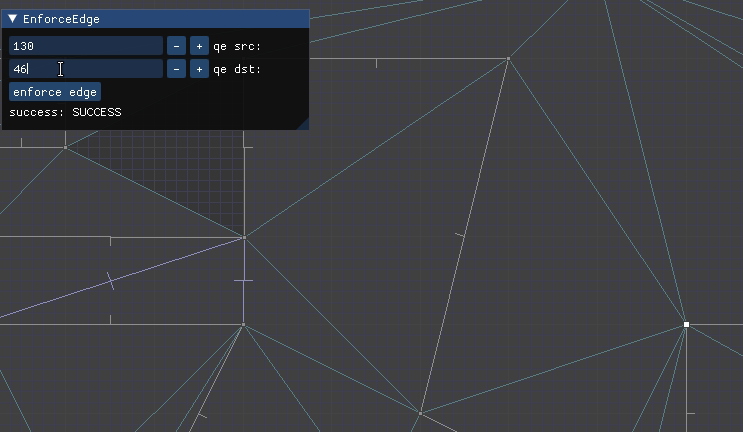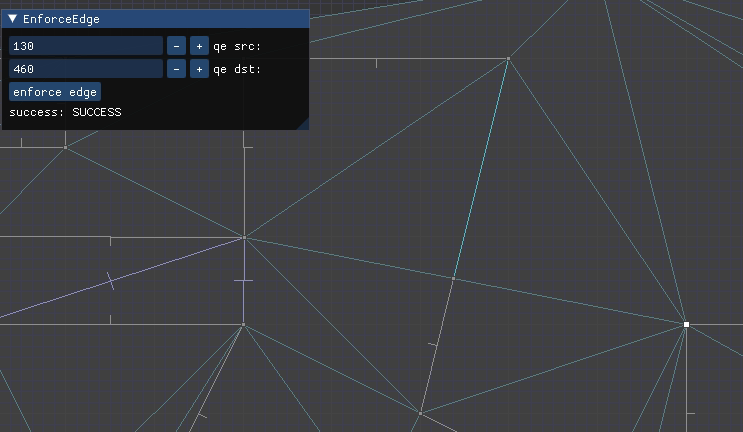
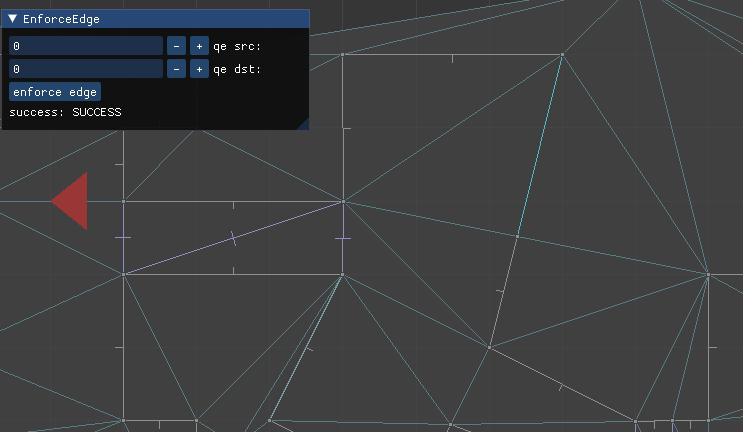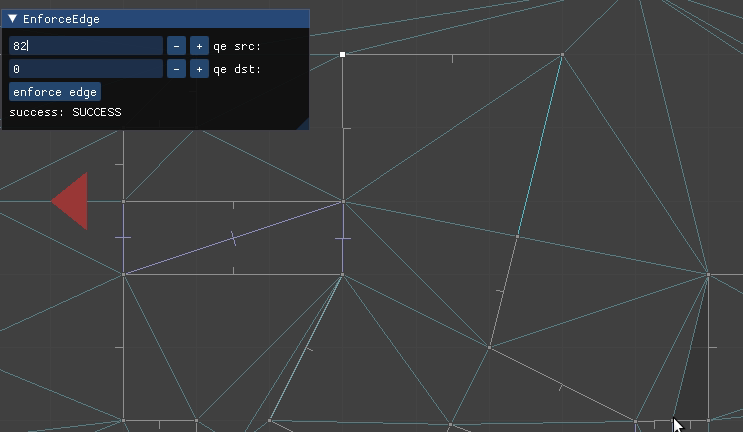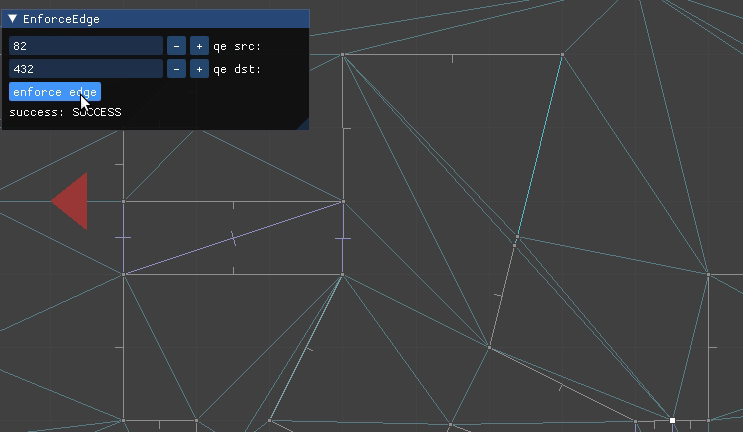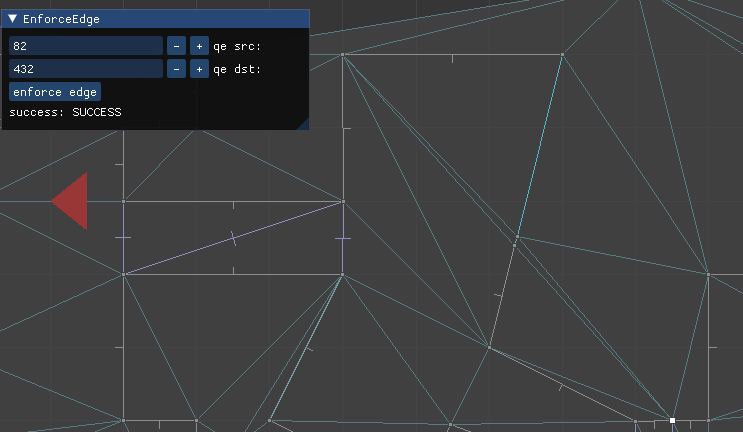
QuarterEdgeIndex qe_ab = mesh.EnforceEdge(qe_a, qe_b);
mesh.ConstrainEdge(qe_ab);
// sidedef and passability stuff...
}
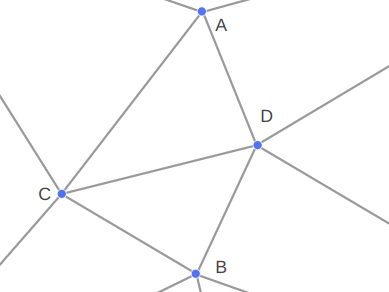
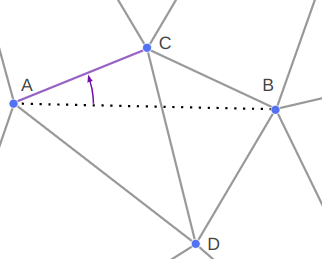
For example, we might add the vertices for A and B, and then end up with a mesh that is locally Delaunay but does not have an edge between A and B:
The call to EnforceEdge then flips CD in order to get the edge we want:
This approach worked for the DOOM maps because the sides there never crossed over one another. For example, if CD is another enforced edge, there was no way to also enforce AB by flipping edges:
I needed a more general way to specify two points A and B and then adjust the mesh such that those two points are joined by a straight line, potentially via multiple colinear segments.
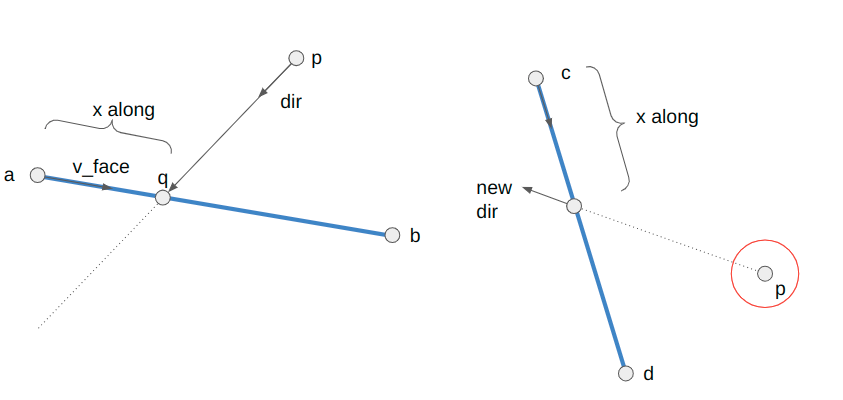
The updated algorithm has an outer loop that alternately tries tackling the problem from A to B and from B to A. As soon as it finds or produces a connection, it terminates. If it fails to make progress from both directions, it exits out.
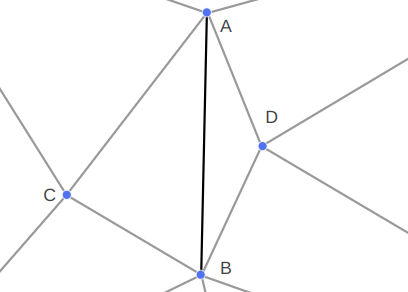
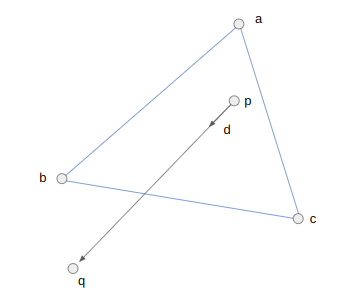
Attempting to make progress from A to B starts by finding the edge from A that is as close as possible in a counter-clockwise / right-hand sense to the desired segment AB:
We’ll call the other side of this segment C. If C = B, we are done, as then AB already exists.
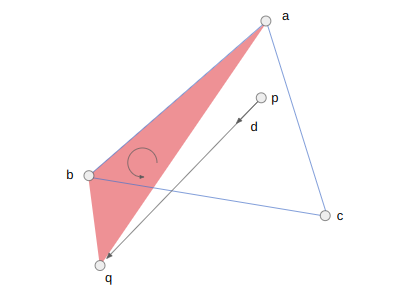
It is possible that C lies along AB. When this happens, we replace A with C and return to the outer loop:
If we haven’t returned yet, then AC is counter-clockwise of AB. We need to flip CD, where D is on the other side of AB from C. If CD is not constrained, we can flip it.
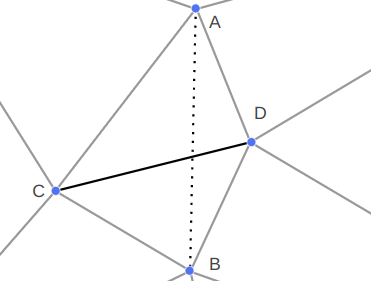
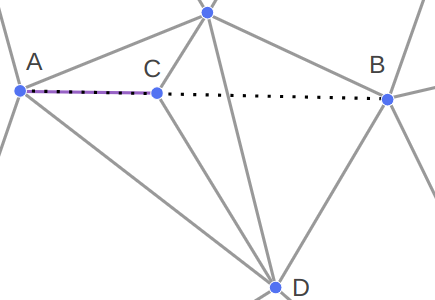
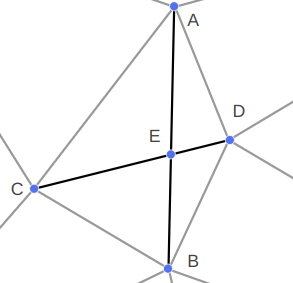
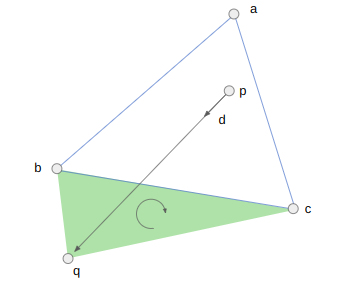
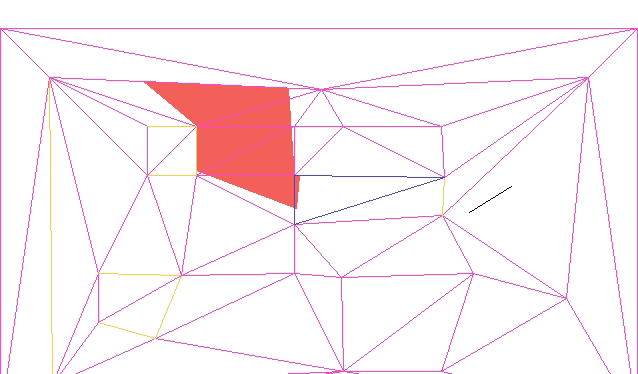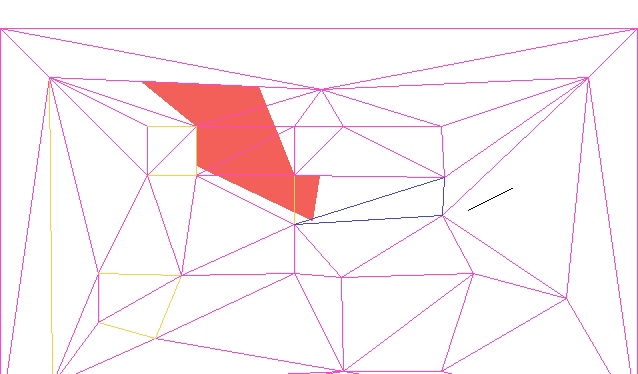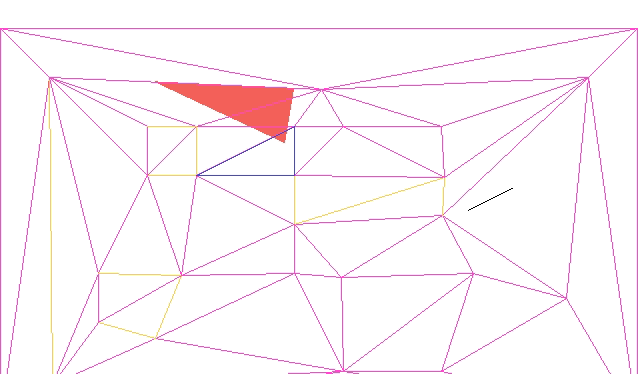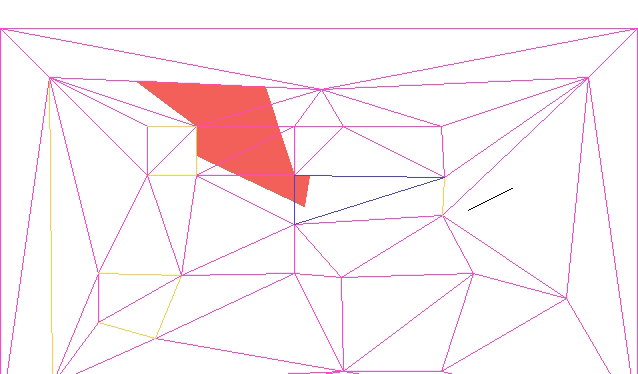
The most interesting case occurs when CD is constrained. We cannot flip CD because it is fixed – we want it to remain an edge in the final mesh. So we instead introduce a new point E at the intersection of AB and CD, split CD at E, and add AE and EB:
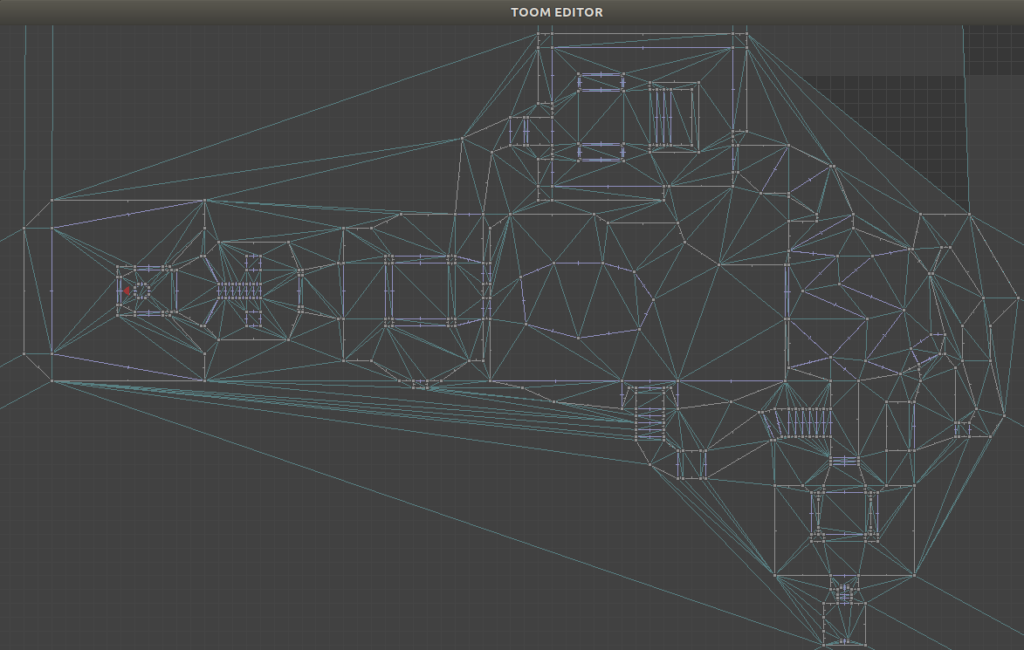
We can see this in action in the TOOM mesh editor, updated with this method:
Here we have a constrained edge
Here we have to flip or intersect multiple edges
So far I’m just building a mesh with constrained edges matching those of the expanded collision polygons, and only have a single such mesh to reflect the player’s collision polygon. I do not yet track which polygon corresponds to which triangle, nor do edges otherwise have any special properties. Nevertheless, what I have is sufficient for basic 2D player movement.
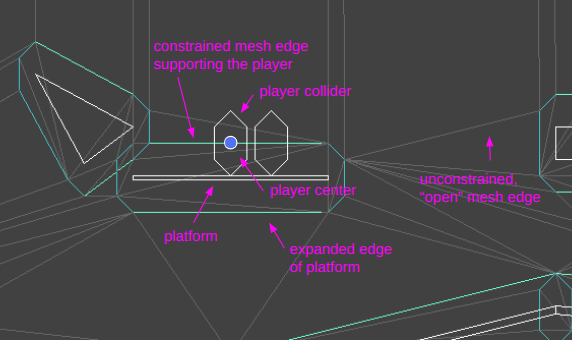
The player (and any other entity) has a 2D position and a triangle face in which their position lies. The 2D position is continuous, but the triangle face is discrete. Having something discrete resolves the issue with floating point rounding – we know exactly which side of a line we are (supposed to be) on.
Note that the constrained Delaunay mesh does not actually contain the white collider polygons:
I’ll probably talk about this more next time, but movement physics currently get processed in two different ways. If the moving entity is airborne, then they move according to the standard laws of physicsApply acceleration, use velocity and delta t to get future position, sweep along the line segment, and check for triangle traversals.. If we collide with a solid edge, we lose all velocity going into it and then continue on in our new direction. Colliding with a solid edge can result in the agent transitioning to the supported state.
If the moving entity is standing or walking on a surface, i.e. is supported, we handle things a bit differently. Here their velocity is projected along the supporting surface. Any time they move past the end of the supporting surface, we find the next supporting edge (if there is one) and allow them to transition over. If they are moving fast enough or there is no supporting edge to connect to, they transition to being airborne.
The player walking across supporting surfaces
Conclusion
Constrained Delaunay meshes resolved many of the tricky issues that arose with tackling 2D player movement for arbitrary terrain geometry. Knowing which face a player is in is a discrete fact that removes the issues with numeric imprecision in general polygon-on-polygon collisions, without having to resort to shunting. It also naturally allows us to leverage the mesh to query things like the next supporting face.
The code for the updated Delaunay mesh is available here.
In the future I hope to support additional motion states, such as climbing on ladders and surfaces. I’ll want to add support for dropping down “through” a platform, wall slides and jumps, and some other basic sidescroller movement features. I want to add 3D GPU graphics, and with that, animations and combat. It turns out there is a lot that goes into a basic game.
One of the most interesting parts of the Convex Optimization lectures by Stephen Boyd was the realization that (continuous) optimization more-or-less boils down to repeatedly solving Ax = b. I found this quite interesting and thought I’d write a little post about it.
Constrained Optimization
An inequality-constrained optimization problem has the form:
One popular algorithm for solving this problem is the interior point method, which applies a penalty function that prevents iterates \(\boldsymbol{x}^{(k)}\) from becoming infeasible. One common penality function is the log barrier, which transforms our constrained optimization problem into an unconstrained optimization problem:
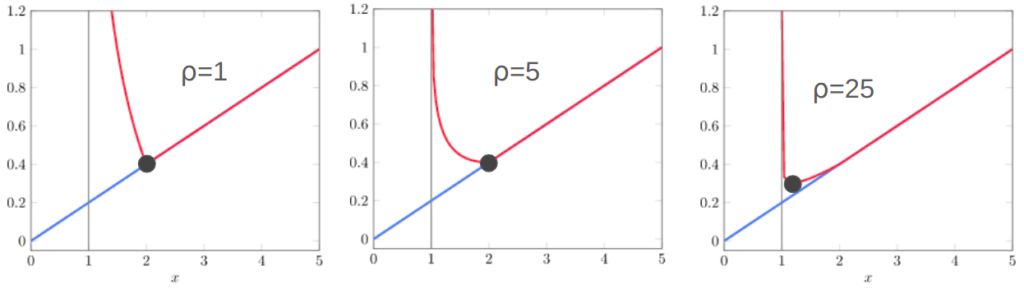
The penalty scalar \(\rho > 0\) starts small and is increased as we iterate, reducing the penalty for approaching the constraint boundary.
We thus solve our constrained optimization problem by starting with some feasible \(\boldsymbol x^{(0)}\) and then solving a series of unconstrained optimizations. So the first takeaway is that constrained optimization is often solved with iterated unconstrained optimization.
Here we see the an objective function (blue) constrained with \(x \geq 1\) (gray line). The red line shows the penalized surrogate objective. As we increase \(\rho\) and optimize, our solution moves closer and closer to \(x = 1\).
Unconstrained Optimizaton
We have found that constrained optimization can be solved by solving a series of unconstrained optimization problems.
An unconstrained optimization problem has the form:
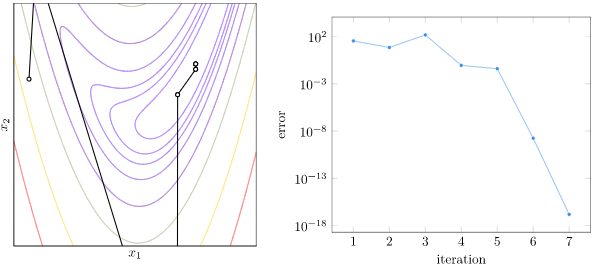
If \(f\) is continuous and twice-differentiable, we can solve this problem with Newton’s method. Here we fit a quadratic function using the local gradient and curvature and use its minimum (which we can solve for exactly) as the next iterate:
Continuous functions tend to become bowl-shaped close to their optimas, so Newton’s method tends to converge extremely quickly once we get close. Here is how that looks on the banana function:
What this means is that unconstrained optimization is done by repeatedly calculating Newton steps. Calculating \(\boldsymbol H(\boldsymbol x^{(k)})^{-1} \nabla f(x^{(k)})\) is the same as solving Ax = b:
\[\boldsymbol H\boldsymbol d = \nabla f\]
Well alrighty then, optimization is indeed a bunch of Ax = b.
What does this Mean
There are several takeaways.
One is that its nice that complicated things are just made up of simpler things that we can understand. One can take comfort in knowing that the world is understandable.
Another is that we should pay a lot of attention to how we compute Ax = b. Most of our time spent optimizing is spent solving Ax = b. If we can do that more efficiently, then we can optimize a whole lot faster.
Estimating Solve Times
How long does it take to solve Ax = b? Well, that depends. Let’s say we’re naive, and we have a random \(n \times n\) matrix \(\boldsymbol A\) and a random vector \(\boldsymbol b\). How fast can our computers solve that?
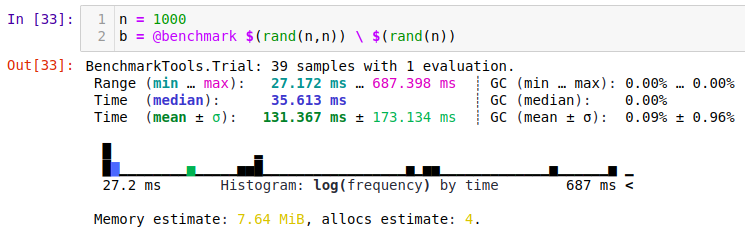
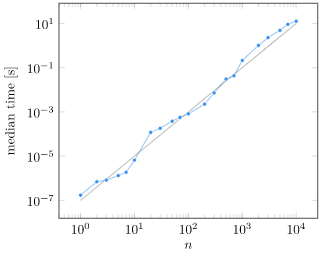
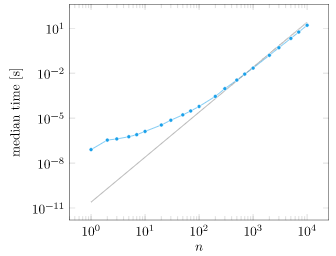
Well, it turns out that my laptop can solve a random \(1000 \times 1000\) linear system in about 0.35s:
We can plot the computation time vs. matrix size:
At first glance, what we see is that yes, computation grows as we increase \(n\). Things get a little fishy though. That trend line is \(n^2/10^7\), which is not the \(O(n^2)\) growth that we expected. What is going on?
While Julia itself is running single-threaded, the underlying BLAS library can use up to 8 threads:
Our system is sneakily making things more efficient! If we force BLAS to be single-threaded, we get the \(O(n^3)\) growth we expected after about \(n=200\) (Thank you Julia Discourse!):
What we’ve learned is pretty important – there are speedups to be had that go beyond traditional big-O notation. If you have an optimization problem, chances are that multithreading and SIMD can speed things up for you. If you have a really large optimization problem, maybe you can distribute it across multiple machines (Proximal methods, for example, are often amenable to this).
We also learned how mind-bogglingly fast linear algebra is, even on a single thread. Think about how long it would take you to manually solve Ax = b for \(n=2\) with pen and paper, and how fast the same operation would take on your machine.
If it takes 100 Newton iterates to solve an unconstrained optimization problem, then you can solve a problem with a thousand variables in 3.5s. Multiply that by another 100 for a constrained optimization problem, and you’re looking at solving a constrained optimization problem with \(n=1000\) in under 6 minutes (and often in practice, much faster).
We live in an era where we can solve extremely large problems (GPT-4 is estimated to have 1.7 billion parameters), but we can also solve smaller problems really quickly. As engineers and designers, we should feel empowered to leverage these capabilities to improve everything.
Special Structure
Appendix C of Convex Optimization talks a lot about how to solve Ax = b. For starters, generally solving \(\boldsymbol A \boldsymbol x = \boldsymbol b\) for an arbitrary \(\boldsymbol A \in \mathbb{R}^n\) and \(\boldsymbol b \in \mathbb{R}^n\) is \(O(n^3)\). When we’re using Newton’s method, we know that the Hessian is symmetric and positive definite, so we can compute the Cholesky decomposition of \(\boldsymbol A = \boldsymbol F^\top \boldsymbol F\). Overall, this takes about half as many flops as Gaussian elimination [source].
There are a bunch of other types of structure that we can take advantage of when we know that it exists. The most obvious is when \(\boldsymbol A\) is diagonal, in which case solving Ax = b is \(O(n)\).
One particularly interesting example is when \(\boldsymbol A\) has arrow structure:
When this happens, we have to solve:
\[\begin{bmatrix} \boldsymbol A & \boldsymbol B \\ \boldsymbol B^\top & \boldsymbol C \end{bmatrix} \begin{bmatrix} \boldsymbol x \\ \boldsymbol y \end{bmatrix} = \begin{bmatrix}\boldsymbol b \\ \boldsymbol c\end{bmatrix}\] where \( \boldsymbol A\) is diagonal, block-diagonal, or banded; \(\boldsymbol B\) is long and narrow; and \(\boldsymbol C\) is dense but comparatively small.
Solving a system with arrow structure can be done by first solving \(\boldsymbol A \boldsymbol u = \boldsymbol b\) and \(\boldsymbol A \boldsymbol V = \boldsymbol B\), which are both fast because we can exploit \( \boldsymbol A\)’s structure. Expanding the top row and solving gives us:
\[\boldsymbol x = \boldsymbol A^{-1} \left( \boldsymbol b – \boldsymbol B \boldsymbol y \right) = \boldsymbol u \> – \boldsymbol V \boldsymbol y\]
We can substitute this into the bottom row to get:
\[\begin{aligned} \boldsymbol B^\top \boldsymbol x + \boldsymbol C \boldsymbol y & = \boldsymbol c \\ \boldsymbol B^\top \left( \boldsymbol u \> – \boldsymbol V \boldsymbol y \right) + \boldsymbol C \boldsymbol y & = \boldsymbol c \\ \left( \boldsymbol C – \boldsymbol B^\top \boldsymbol V\right) \boldsymbol y & = \boldsymbol c \> – \boldsymbol B^\top \boldsymbol u\end{aligned}\]
Having solved that dense system of equations for \(\boldsymbol y\), we can back out \(\boldsymbol x\) from the first equation and we’re done.
You might think that arrow structure is a niche nicety that never actually happens. Well, if you look at how packages like Convex.jl, cvx, and cvxpy solve convex optimization problems, you’ll find that they expand and transform their input problems into a partitioned canonical form:
\[\begin{aligned}\underset{\boldsymbol x}{\text{minimize}} & & d + \boldsymbol c^\top \boldsymbol x + \frac{1}{\rho} p_\text{barrier}(\boldsymbol x) \\ \text{subject to} & & \boldsymbol A^\top \boldsymbol x = \boldsymbol b\end{aligned}\]
we can apply a primal-dual version of Newton’s method that finds a search direction for both \(\boldsymbol x\) and the dual variables \(\boldsymbol \mu\) by solving:
\[\begin{bmatrix} \nabla^2 p_\text{barrier}(\boldsymbol x) & \boldsymbol A^\top \\ \boldsymbol A & \boldsymbol 0\end{bmatrix} \begin{bmatrix}\Delta \boldsymbol x \\ \boldsymbol \mu \end{bmatrix} = – \begin{bmatrix}\rho \boldsymbol c + \nabla p_\text{barrier}(\boldsymbol x) \\ \boldsymbol A \boldsymbol x – \boldsymbol b\end{bmatrix}\]
Wait, what is that we see here? Not only does this have arrow structure (The Hessian matrix \(\nabla^2 p_\text{barrier}(\boldsymbol x)\) is block-diagonal), but the tip of the arrow is zero! We can thus solve for the Newton step very efficiently, even for very large \(n\).
So this esoteric arrow-structure thing turns out to be applicable to general convex optimization.
Conclusion
If you take a look at university course listings, there is a clear pattern of having classes for “Linear X” and “Nonlinear X”. For example, “EE263: Introduction to Linear Dynamical Systems” and “E209B Advanced Nonlinear Control”. You learn the linear version first. Why? Because we’re really good at solving linear problems, so whenever a problem can be framed or approximated in a linear sense, we’ve either solved it that way first or found its easiest to teach it that way first. Anything can be locally approximated by a 1st-order Taylor series and we can just work with a linear system of equations.
I love that insight, but I also love the implication that it has. If we can understand how to work with linear systems, how to exploit their structure and how to solve them quickly to sufficient accuracy, then we can speed up the solution of pretty much any problem we care about. That means we can solve pretty much any problem we care about better, more often, to a higher-degree of precision, and thereby make the world a better place.
We often want robots, drones, or video game mobs to navigate from one location to another as efficiently as possible, without running into anything.
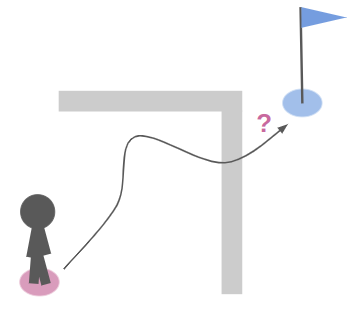
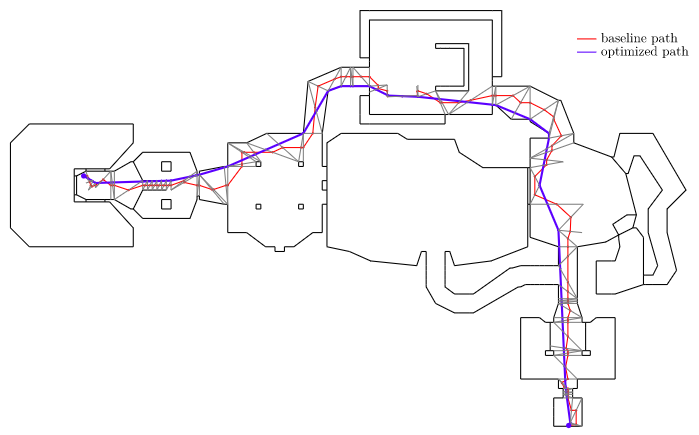
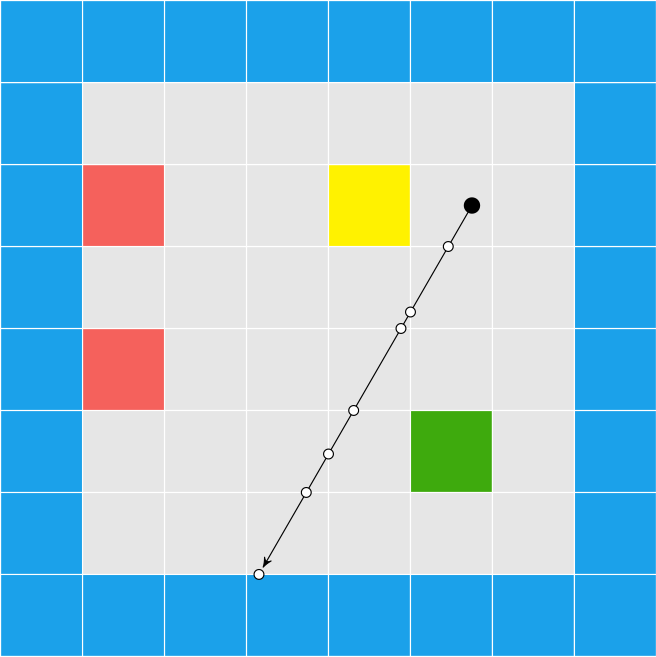
In such times of need, many of us turn to A*, in which we discretize our problem and make path planning about finding a sequence of discrete steps. But that only solves half the problem – we often end up with a chunky, often zig-zaggy solution:
The actual shortest path doesn’t look like that. It hugs the corners and moves off-axis:
This post will cover one way to solve this problem. It will continue to leverage the power of graph algorithms like A*, but will conduct local path optimization in the second phase to get a shortest path.
Phase 1: Global, Discrete Path Planning
In the first phase, we find a coarse shortest path through a graph. Graphs are incredibly useful, and let us apply discrete approaches to the otherwise continuous world.
For this to work, the planning environment has to be represented as a graph. There are many ways to achieve this, the simplest of which is to just use a grid:
For more general terrain it is more common to have tessellated geometry, often in the form of a navigation mesh. Below we see a path for a marine in a StarCraft 2 navmesh:
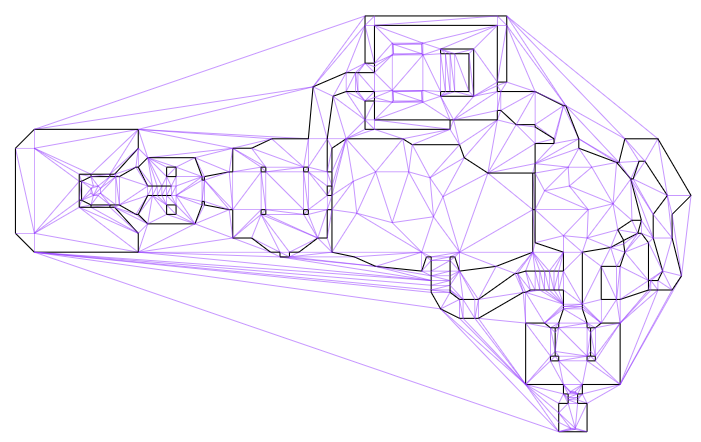
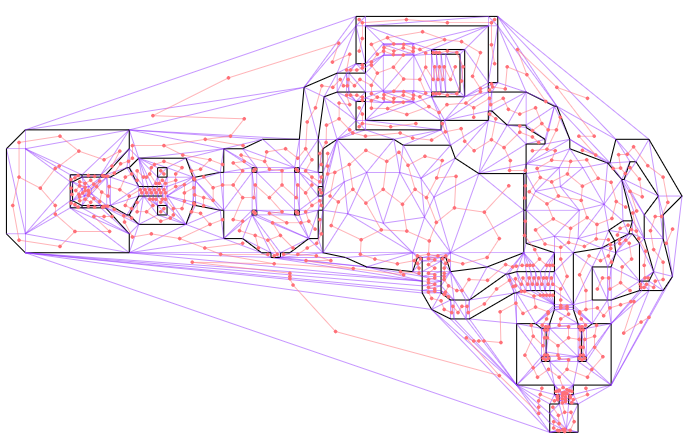
Navigation meshes, typically represented using doubly connected edge lists (DCELs), are graphs that represent both the geometry (via primal vertices and edges), and connections between faces (via dual vertices and edges). This sounds more complicated than it is. Below we see the E1M1 map from DOOM, after I’ve loaded it into a DCEL. The map walls are black and the remaining triangle edges are shown in purple:
This image above only shows the primal graph, that is, the actual map geometry. The cool thing about DCELs is that they also contain a dual graph that represents connectivity between faces (triangles). Below I additionally show that dual graph in red. I’ve ignored any edges that are not traversible by the player (i.e. walls or large z changes):
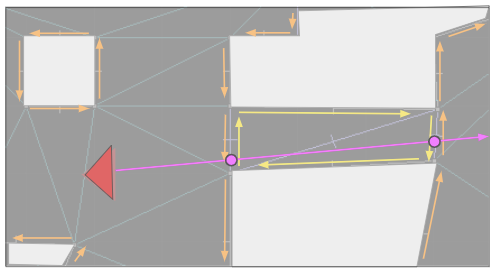
The first phase of path planning is to find the shortest path in this dual graph from our source triangle to our destination triangle. We can drop nodes that aren’t reachable:
We can run a standard graph-search algorithm on this dual graph. Each node lies at the centroid of its triangular face, and the distance between nodes can simply be the distance between the centroids. As the problem designer, you can of course adjust this as needed – maybe walking through nukage should cost more than walking over normal terrain.
In Julia this can be as simple as tossing the graph to Graphs.jl:
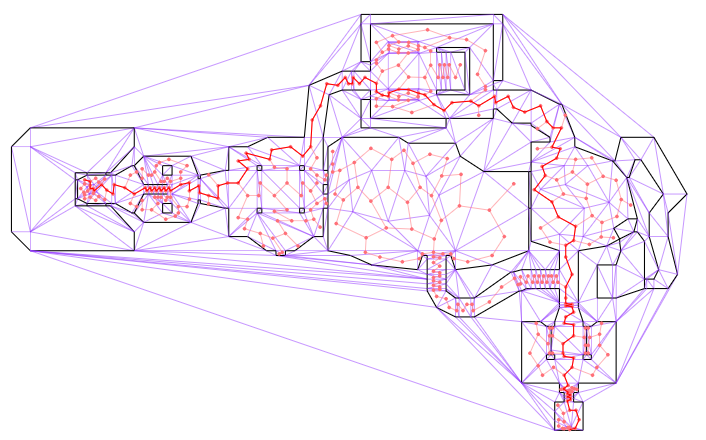
This gives us a shortest path through the triangulated environment. It is typically jagged because it can only jump between centroids. Below we see a shortest path that traverses the map:
The discrete phase of motion planning is typically very efficient, because graph search algorithms like A* or Dijkstra’s algorithm are very efficient. If our environment is more or less static, we can even precompute all shortest paths. This makes the discrete phase of motion planning very cheap.
Our problem, however, is that the resulting path is not refined. To rectify that, we need a second, local phase.
Phase 2: Local Refinement
The second phase of path planning takes our discrete path and cleans it up. Where before we were constrained to the nodes in the dual graph, in this phase we will be able to shape our path more continuously. However, we will restrain our path to continue to traverse the same sequence of faces as it did before.
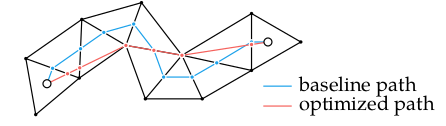
Because we are restricting ourselves to the same sequence of faces, we can ignore the rest of the graph. The first thing we’ll do is switch from traversing between centroids to traversing between edges along a specific corridor. Below we show the path slightly modified (red), with traversals between the centers of the crossed faces (gray):
That is already somewhat better, but it is not good enough. Next we will shift these crossing points along the crossed edges in order to shorten the path. This can be thought if as laying down a long rubber band along the center of the traversed corridor, and then stretching it out to tighten it so that it hugs the edges. As such, this process is often called elastic band optimization or string pulling.
This is an optimization problem. How do we formulate it?
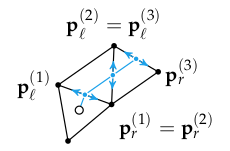
Let \(\boldsymbol{p}^{(0)}\) be our starting point, \(\boldsymbol{p}^{(n+1)}\) be our destination point, and \(\boldsymbol{p}^{(i)}\) for \(i\) in \(1:n\) be the \(n\) vertices at the edges that our path traverses. We can slide each \(\boldsymbol{p}^{(i)}\) along its edge, between its leftmost and rightmost values:
This problem is convex because \(\| \boldsymbol{p}^{(i+1)} – \boldsymbol{p}^{(i)} \|_2\) is convex and the sum of convex functions is convex, the first constraint is linear (which is convex), and the inequality constraints are simple inequality constraints. We can thus solve this problem exactly.
In a game engine or robotics product we might roll our own solver, but here I’m just going to use Convex.jl:
α = Variable(n) # interpolants
ps = Variable(2, n) # optimized points, including endpoints
problem = minimize(sum(norm(ps[:,i+1] - ps[:,i]) for i in 1:n-1))
for i in 1:n
problem.constraints += ps[:,i] == p_ls[i] + α[i]*(p_rs[i] - p_ls[i])
end
problem.constraints += α >= 0
problem.constraints += α <= 1
solve!(problem, () -> ECOS.Optimizer(), verbose=false, silent_solver=true)
α_val = evaluate(α)
ps_opt = evaluate(ps)
Easy!
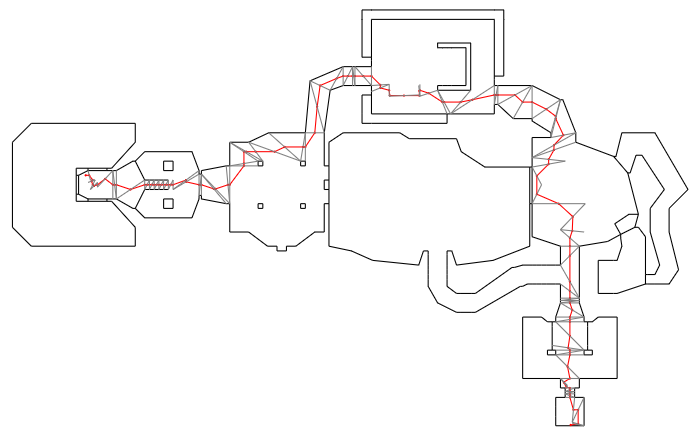
Solving our optimization problem gives us our locally-optimized shortest path:
We can see how the optimized path hugs the corners and walls and heads straight across open areas. That is exactly what we want!
Agents have Width
Okay, so this gives us an optimized path, but it treats our robot / drone / enemy unit as a point mass. Our agents typically are not point masses, but have some sort of width to them. Can we handle that?
Let’s treat our agent as being a circle with radius \(r\). You can see such a circle in the earlier image for the StarCraft 2 marine.
We now modify both phases of our path planning algorithm. Phase 1 now has to ignore edges that are not at least \(2r\) across. Our agent cannot fit through anything more narrow than that. We set the path traversal cost for such edges to infinity, or remove them from the graph altogether.
Phase 2 has the more radical change. We now adjust the leftmost and rightmost points \(\boldsymbol{p}_\ell^{(1:n)}\) and \(\boldsymbol{p}_r^{(1:n)}\) to be a distance \(r\) from the line segment endpoints. This reflects the fact that our agent, with radius \(r\), cannot get closer than \(r\) to the edge of the crossed segment.
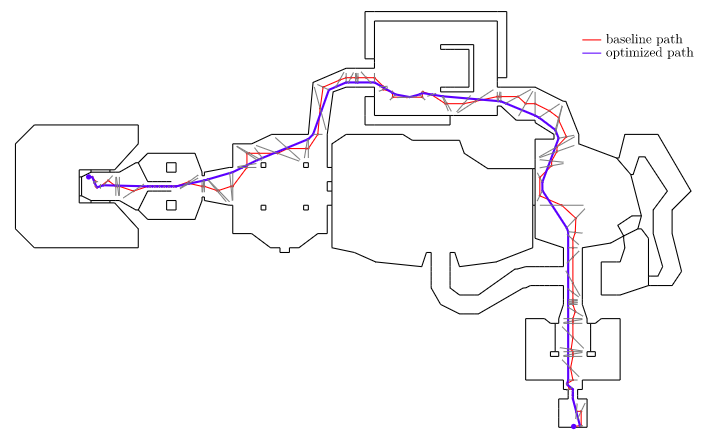
Below we show an optimized path using a small player radius. We can see how the new path continues to try to hug the walls, but maintains at least that fixed offset:
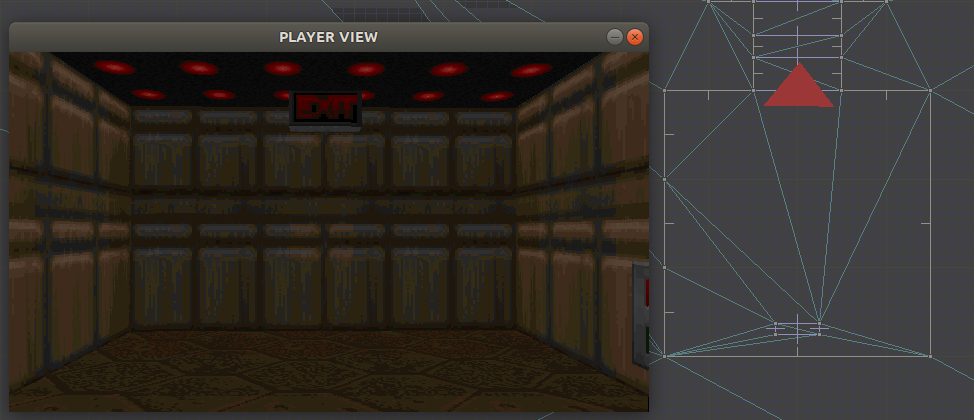
Notice that this naive augmentation introduced a few artifacts into the smoothed path, particularly near the start and end vertices. This stems from the fact that the map geometry in those location includes edges that are not actually constrained by walls on both sides. For example, the room in the bottom right has some extra triangles in order to be able to carve out that exit sign in the ceiling. It doesn’t actually hamper movement:
This can be fixed by using a navigation mesh that more accurately reflects player navigation. In this case, we’d remove the exit sign from the nav mesh and end up with an exit room where every edge has vertices that end at the walls.
Conclusion
This post covered a method for path planning applicable to basic robotics motion planning or for AI path planning in video games. It is a two-phase approach that separates the problem into broadly finding the homotopy of the shortest path (which side of a thing to pass on) and locally optimizing that path to find the best continuous path within the identified corridor. This method of breaking down the problem often shows up when tackling complicated problems – a discrete solver is often better at the big-picture and a local optimizer is often better for (often much-needed) local refinement.
There are many variations to the path planning problem. For example, path planning for a robot car may require restricting our path to allow for a certain turning radius, and path planning for an airplane may require planning in 3D and restricting our climb or descent rates. We may wish to minimize things other than the path distance, such as the amount of energy required, or find the shortest path that gets us there within a given energy budget. The real world is full of complexity, and having the necessary building blocks to construct your problem and the various tools at your disposal to solve them in the way that makes most sense for you makes all the difference.
This month continues our foray into the world of DOOM and C software renderers. In the last post, we moved from a blocky, axis-aligned world to general 2D geometry. In this post, not only will we manipulate the 3rd dimension, thereby reaching DOOM-geometry-parity, we will leverage our raycasting approach to unlock something the original DOOM couldn’t do.
Variable Floor and Ceiling Heights
In Wolfenstein 3D, the floors are always at z = 0 and the ceilings are always at z = 1. DOOM could adjust these floor and ceiling heights, and its players were thus able to ascend stairs, traverse next to chasms, and generally enjoy a much richer gaming environment.
This gif shows the basic z-manipulation I’m talking about:
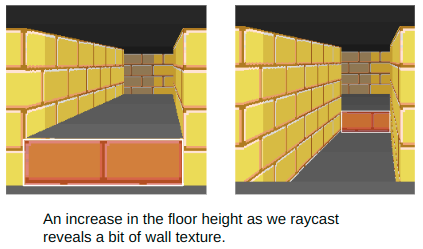
Here we’re adjusting the floor and ceiling height of our corridor. When we raise the floor, we need to render a wall texture between our floor and the raised corridor floor. When we lower the floor, we need to render a wall texture between the lowered floor and the normal floor on the other end.
Changing the ceiling height can also expose a bit of wall texture:
Our renderer has to be able to model these floor sections in order to keep track which of piece of floor has which floor and ceiling height, and we have to keep track of the textures to draw when they are exposed.
Like DOOM, I will denote regions of the map with a particular floor and ceiling height (and later, floor and ceiling textures) to be called a sector. Sectors will naturally be closed polygons in our top-down 2D map.
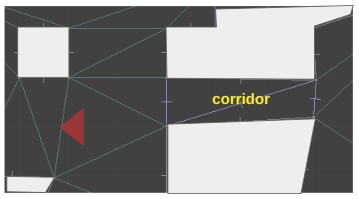
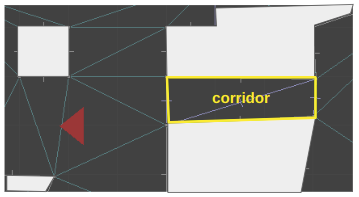
Here you can see a top-down view of the TOOM level editor, showing the same region as rendered above. The red triangle is the camera, which looks toward the right.
Here is the same shot, filled in a bit to make it easier to interpret:
As covered in the last post, the world is defined using a triangle mesh. Our corridor, for example, is comprised of two triangles. The sector for that corridor must be referenced by the lines along the corridor’s boundary:
The sector itself just stores the z heights right now. It doesn’t know which edges it corresponds to. Instead, we have the side geometry refer to the sector it should correspond to. This approach is again, very much like DOOM.
We are using a Doubly Connected Edge List (DCEL) to represent our triangle mesh. Edges in a DCEL are bi-directional . If we think of edges as right-handed, and an edge A->B as being on the right-hand side of AB, then we can just have every directed edge at the boundary of a sector keep track of which sector it helps enclose.
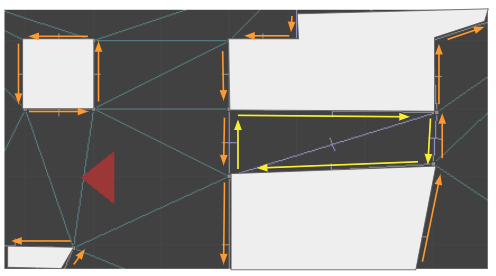
The sides that refer to the corridor are yellow, whereas the sides that refer to the primary sector are orange. When we raycast from the camera down the corridor, we can check for z changes when we traverse over edges where the sector changes. Here we see a raycast with two locations where the sector heights might change:
The data structures for this are pretty simple. A directed edge may have a SideInfo:
A SideInfo is simply a struct that contains a lower, middle, and upper texture, the index of the sector to refer to, and some flags. Right now, the only flag I use is one to determine whether a wall is passable, and if so, we can avoid rendering the middle texture.
The TextureInfo entry is pretty simple as well:
struct TextureInfo {
u16 texture_id; // Index in the texture atlas
i16 x_offset; // Texture x offset
i16 y_offset; // Texture y offset
};
With these data structures in-hand, rendering becomes a little more complicated. We continue to cast our ray out, as before. Now, however, we need to keep track of how much we’ve already drawn.
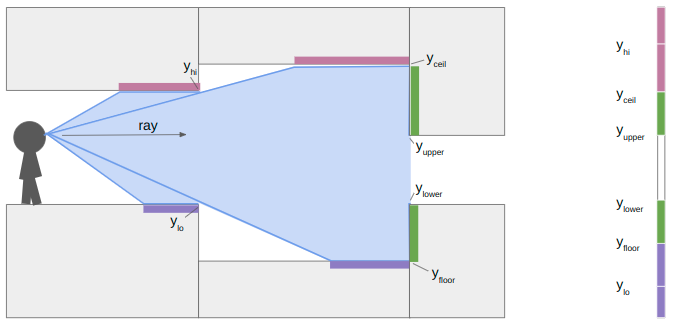
To illustrate, let’s look at a horizontal cross-section of geometry:
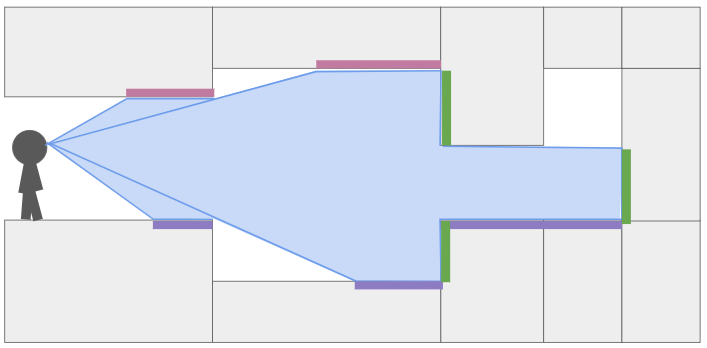
Here I have drawn the area swept out as we cast a single ray to the right, down a single pixel-column. The light purple boxes show all of the regions in our field-of-view where we need to render ceiling pixels, the dark purple boxes show where we need to render floor pixels, and the green boxes show where we need to render wall pixels.
When we start raycasting, we start having not drawn any pixels. The bounds on where we can draw contains the whole vertical pixel column, between zero and the number of pixels:
We start to traverse the mesh, and hit our first sector change:
At this point we calculate the y-location (i.e., location in the vertical pixel column) of the ends of the floor and ceiling. We render the floor and ceiling into our pixel column. We’re already pretty used to this trigonometry by now.
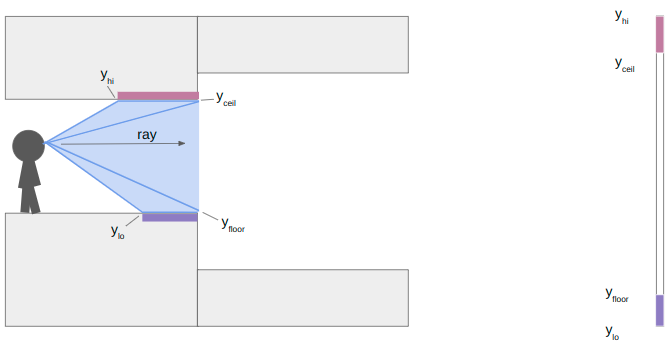
\[\gamma = \frac{\text{SCREEN_SIZE_Y}}{\text{y field of view}} \cdot \frac{\text{cam length}}{\text{ray length}}\]
The y yield of view is how many units up the camera views for every unit we raycast outward. I’m using about 0.84. The camera length is close to 1, and adjusts for the fact that our screen is flat and not curved, so rays travelling left or right of center have to have the length adjusted. Other than that, its just a function of the heights and how far our ray has traveled.
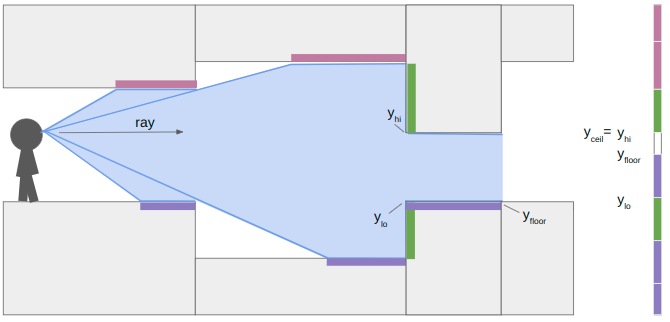
In this case, the next sector has an increase in the ceiling height and a decrease in the floor height. That means we do not have any local wall textures to render. We set \(y_\text{lo} = y_\text{floor}\) and \(y_\text{hi} = y_\text{ceil}\) and keep on raycasting:
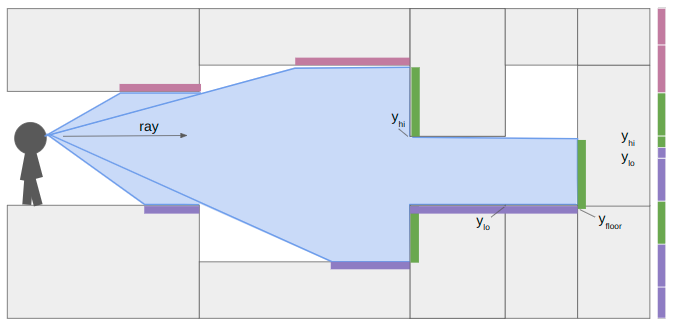
At the next sector transition, we once again compute \(y_\text{floor}\) and \(y_\text{ceil}\). This time, however, the ceiling drops and the floor rises, so we also have wall segments to render. We compute their pixel extents in the same way:
where \(z_\text{upper}\) and \(z_\text{lower}\) are the new sector ceiling and floor heights, respectively.
When we continue our raycast, we find that the next sector transition only increases the ceiling height. The new \(y_\text{floor}\) is greater than \(y_\text{lo}\), so we render the patch of floor. The new \(y_\text{ceil}\) is not any lower than our current \(y_\text{hi}\), due to the ceiling being parallel to our camera view, so we don’t need to render anything there.
We finally proceed and hit a closed sector. We render the last bit of floor and then render its center texture:
So that’s how the renderer works when you have variable z heights and upper, middle, and lower textures. Each raycast has to do more work to determine what to draw, and it keeps track of where it is within its y pixel bounds to make sure we don’t mistakenly draw something on top of what we’ve already rendered.
Rendering Textures
In this previous blog post, I covered sprites, and how they use the DOOM picture format. In short, sprites like monsters are stored in vertical pixel strips. Why? Because when we render the vertical portions of the world, we’re rendering convenient vertical sections of these sprites. The vertical orientation forms a right-triangle, which makes the math of figuring out which pixel to draw more efficient. DOOM uses the same format for wall textures (both upper and lower). I ended up doing the same thing.
So, wall textures are the same as sprites. What about horizontal textures? We’d like to draw textures on our ceilings and floors too:
(Yeah, these don’t fit thematically. I haven’t loaded my own floor and ceiling textures yet. These just come from DOOM.)
We can again leverage our previous work to figure out how to draw floor and ceiling textures. Unlike the vertically-oriented wall textures, these “flat” textures are most efficiently drawn horizontally across the screen. As such, in DOOM they are called flats.
Our render is most adept at rendering things vertically. It works on one pixel column at a time. So how do we hope to render anything horizontally?
Well, the raycasts start with the leftmost pixel column and then work their way to the right. I keep track of active spans, which are horizontal sections of the screen that need to eventually be rendered with a single flat at a single floor height. Whenever we need to start a new span, we close out the previous one and render it.
The gif above shows how the renderer produces a scene. We draw vertical sections as we raycast, but start/maintain horizontal spans that only get rendered (1) when another span in the same y-coordinate starts or (2) we are done raycasting.
Each active span contains all of the information needed to render it efficienctly, once it needs to be rendered:
struct ActiveSpanData {
// Location of ray_dir_lo's intersection with the ground.
common::Vec2f hit;
// Shift 'hit' by one pix column moved toward hi's intersection.
common::Vec2f step;
u16 sector_id;
u16 flat_id;
bool is_active;
// The camera x pixel index where this span starts.
int x_start;
// The most recent camera x pixel where this span currently ends.
int x_end;
};
We can do the computation work of calculating the hit and step values when we first create the span. We set x_start at that time, and initially set x_end to the same value. If we go to render the same sector in the same location in the next column, we increment x_end.
Colors and Light Levels
You may have noticed that these images get darker the further we’re looking. This is an intentional effect from DOOM that enhances the sense of depth.
This is easiest to see without the floor textures:
Conceptually, this is really simple. Render pixels darker when they are further away.
The light level of a pixel column drops off as the raycast distance increases. Or rather, the darkness level increases with the raycast distance.
Pixel values are written to the screen as RGB values. How does one take an RGB value and make it darker? Well, white is 0xFFFFFF and black is 0x000000, so the simplest way is to decrease each channel by some percentage. To do it “more correctly”, you can convert your RGB color into the Lab colorspace, reduce its lightness, and then convert it back. That is an expensive operation.
The original DOOM didn’t have access to RGB values. Or rather, it didn’t have access to all of them. According to the DOOM Black Book, PC video games of the 90s had 320×200 resolution with 1 byte per pixel drawn from a 256-color palette. This meant that programmers could set the 256 colors in the palette, and drawing a pixel to the screen effectively meant indexing into this palette by setting a 1-byte pixel index rather than a full RGB value.
So how does one change a pixel’s brightness?
The DOOM developers precomputed mappings from pixel values at full brightness to pixel values at reduced brightness. There were many such colormaps, 32 that were computed for all light levels from 100% brightness all the way down to 0%. There were even some additional colormaps, such as an inverted colormap used when the player becomes invulnerable:
All wall textures and flats store pixel indices rather than RGB values. These pixel indices pass through the chosen colormap and then index into the palette to get the RGB value. In the original DOOM system, indexing into the palette was done for you by the video card. I’ll be doing it myself here.
As a final note, there is one additional lighting effect that helps make the map more legible. Like the trick used in Wolfenstein, walls closer to being x-aligned are drawn 1 point brighter than normal, and walls closer to being y-aligned are drawn 1 point darker than normal. Furthermore, each sector has its own baseline light level. This lets the map creator make some areas naturally darker, and allows for some nice floor shadow effects:
DOOM Levels
Ah, that last image gave it away. The geometry changes and lighting changes now bring us more-or-less to parity with the original DOOM. We can load and traverse the original DOOM levels!
This rendering is done using the raycasting method, via our DCEL, rather than using DOOM’s BSP. This means we can totally avoid loading SEGS, SSECTORS, NODES, and the BLOCKMAP.
E1M1 loaded into the TOOM editor.
Work was required to be able to load the geometry into our DCEL correctly. Mainly in being able to properly flip mesh edges in order to be able to produce edges that match the map geometry, and then constrain them. I might cover that in a future post.
Portals
Okay, we’ve reached geometric parity with DOOM. Is there something this DCEL approach can do that DOOM cannot?
So how does that work?
When we raycast or when the player walks around, we traverse between faces in our triangle mesh. We can create a portal by linking two edges in the triangle mesh and adding the necessary logic such that, when traversed, we come out the linked edge instead.
Below we see the top-down view of the portal setup playing out. The red triangle shows the player camera and its approximate view cone.
The player movement for when we traverse a portal is:
// Suppose we are crossing the line segment AB from pos to pos_next,
// where pos_next now lies on AB.
Vec2f v_face = b - a;
// Calculate where along the segment we intersected.
f32 v_face_len = Norm(v_face);
f32 x_along_texture = v_face_len - Norm(pos_next - a);
// Update our quarter edge using the destination quarter edge
// stored in the side info.
camera_state->qe = mesh.Tor(side_info->qe_portal);
// The vector along the new face is
Vec2f c = mesh.GetVertex(side_info->qe_portal);
Vec2f d = mesh.GetVertex(mesh.Sym(side_info->qe_portal));
Vec2f cd = d - c;
cd = Normalize(cd);
// Our new position is:
camera_state->pos = c + x_along_texture * cd;
f32 angle_ab = std::atan2(v_face.y, v_face.x);
f32 angle_cd = std::atan2(cd.y, cd.x);
f32 angle_rot = CounterClockwiseAngleDistance(angle_ab, angle_cd) + M_PI;
f32 cos_rot = std::cos(angle_rot);
f32 sin_rot = std::sin(angle_rot);
// Now to get the new direction, we need to rotate out of the new face
dir = {cos_rot * dir.x - sin_rot * dir.y,
sin_rot * dir.x + cos_rot * dir.y};
// We also need to rotate our speed
vel = {cos_rot * vel.x - sin_rot * vel.y,
sin_rot * vel.x + cos_rot * vel.y};
Geometrically, we are figuring out the rotation angle between our portals (which could be precomputed) and then rotating our movement direction and speed when we traverse.
Note that the +pi term compensates for the fact that the destination portal side is oriented 180 degrees with respect to the source portal side.
When we raycast through portals, we have properly account for any height changes on the receiving sector. We want to view the other side as if we were the appropriate height:
There is a bit of extra bookkeeping we have to do with portals – namely that for flats to render correctly we have to update the camera position to the place it would be as if the portal did not exist and we were peering toward our destination:
We then have to recompute some of the vectors used to create spans. This is all because flats are rendered on a fixed grid, and we compute where we are in that grid based on the camera location. We have to fake the camera being in the proper location “behind” where the portal surface is. Please take a look at the source code for the nitty-gritty.
There is a lot of neat gamemap stuff that one can do with portals and the non-Euclidean geometry they unlock. Some of it is more blatant, like the first portal, and some of it can be quite subtle, like a hallways that is shorter or longer than expected.
Conclusion
This blog post covered adding variable z heights for floors and ceilings, which then required being able to render wall sections revealed at floor or ceiling height changes. We rendered those vertically, because that is most efficient. We then figured out a way to render horizontal textures too, which were most efficient to render in horizontal strips. We added some lighting effects. We then had everything we needed to represent the original DOOM level geometry. We concluded with an overview of portals – sides in our mesh that are linked together such that crossing one results in you exiting out the other.
I made the code for TOOM and TOOMED available in separate repos. TOOM is the “game”, written in pure C without graphics libraries. TOOMED is the TOOM Editor, written in C++. It basically doesn’t use graphics libraries either, but it does use Dear ImGui with an accelerated backend, as well as have more liberal data structures for easier manipulation of game data and assets.
That’s more or less it for TOOM, for now. There are a few things the renderer doesn’t support that DOOM has, such as animated nukage, pickups, or proper handling for partially-transparent walls. There obviously isn’t any gameplay. No shooting or doors or anything like that. Those things are neat, of course, but I feel like I already understand how they work, and it’d just be pretty tedious work for me to get TOOM running with all that. Maybe I’ll do it, but for now I’m thinking I’ll be turning to other interests. Thanks for reading!
A Note on Efficiency
One of the reasons that this TOOM project interested me in the first place was the promise that I might learn how to program something “for real” and really have to care about performance. I admire folks like Casey Muratori and Jonathan Blow who ardently advocate for efficient programming, and that software engineers should understand what goes on under modern abstractions.
I tried to keep TOOM running at over 30fps. I was able to track this using a profiling technique covered by Casey in his performance-aware programming class.
For a moderately-expensive scene in E1M1, TOOM clocks in at about 130fps:
As we can see, 99.74% of the time is spent rendering. That is to be expected, since that is where all the work is.
Here the frame dt is the 30Hz enforced by my monitor, because SDL is syncing to my monitor refresh rate. This is with a 640 x 320 window, which is double the resolution of the original DOOM. Yes, this is like 30 years after DOOM came out, but I am nevertheless quite happy with these results.
It takes about 4.6x as long for TOOMED to render the same scene, giving it a frame rate of about 28fps. That is not great.
Yes, TOOMED is doing a little more, in that it also renders the top-down GUI. However, that GUI stuff is pretty negligible. I believe the real culprit here more-or-less boils down to two things: memory layout and dictionary lookups.
In TOOM, everything is accessed directly in the binary save file. Entries are all nicely indexed and can be quickly accessed. In TOOMED, since we’re editing things, we store them in std::vectors and std::maps, which results in disparate structures spread out in different locations. In many cases it simply takes more effort for the CPU to get access to what it needs. Furthermore, dictionary lookups, while being O(1), are still doing more work than a simple array access. The delta here, 4.6x, is pretty substantial, and this is the sort of takeaway that I think serious gamedev folk mean when they say paying attention to your data structures and memory strategies matters.
As a final fun learning point, my raycast method was initially recursive. That is, every time we step our ray and transfer over a triangle edge, I’d recurse down in order to process the next triangle step. I figured that this would make it easier to later back-track and render things like monsters or item pickups. However, TOOMED was running _extremely_ slowly, around 70ms per frame. Changing from recursion to a loop cut that time in about half. Its the same amount of work, theoretically, only now we don’t have to make a bunch of copies every time we push to the stack.
I’ve continued tinkering with my little C software renderer covered in previous blog posts. So far we’ve rendered a blocky, textured environment reminiscent of Wolfenstein 3D:
You’ll notice from the window header that the project is called TOOM, as in, Tim DOOM. It isn’t Timenstein 3D, so we have some work to do.
In this blog post we’ll go off-grid and move to general 2D geometry.
Binary Space Partitioning
John Carmack’s great innovation in creating DOOM, the design change that made rendering general 2D geometry in a constrained computing environment possible, was the BSP tree. BSP trees make it efficient to walk over the surfaces in your world in a front-to-back order, based on the camera location.
Each node in the tree represents a splitting plane (or line, rather, as this is 2D) that subdivides the level. All faces below that node lie entirely on one or the other side of that dividing line. At the bottom of the tree you get leaf nodes, which each represent a single convex map region:
While the BSP tree is a genius addition, it does come with its disadvantages. The main one being its construction. For DOOM this meant running Node Builder after level design, a process that does a lot of iteration to find the best splitting planes for a well-balanced tree. Not only does this take a while, it also requires the level geometry to remain static. This means no 2D geometry changes. (DOOM’s doors all move vertically).
I kind of want to be able to support geometry changes. Plus, I kind of like the idea of figuring out something different. So, we’re going to take another approach.
Keep on Raycasting
In Wolfenstein Raycasting in C, we talked about how the software renderer casts rays out into the world for every pixel column in the screen:
This raycasting was fairly efficient because we limited our geometry to a regular grid:
Now, we’re going to do the exact same thing, except on a triangle mesh:
Moving to a triangle mesh has several consequences. On the plus side, it supports general 2D geometry, so we no longer have to constrain ourselves to a grid of blocks. We can fairly easily move vertices and mutate our environment. On the other hand, casting a ray through a set of triangles tends to be more computationally expensive, we have to develop and maintain a more complicated data structure, and we aren’t entirely free to mutate our environment – our triangles have to remain valid (right-handed).
It isn’t 1993 anymore, so I’m hoping that the performance hit from raycasting on a mesh isn’t too bad on a modern processor. I’ve already been tinkering with triangle meshes, so I’m eager to adapt what I learned there to this new application. I also think we can overcome the editing limitations.
Below is a GIF from TOOM. The left half of the image is rendered with the new triangle meshes. The right half of the image is rendered with the old blocky technique. (The new map was made to be identical to the old one, for now). The textures assigned to the walls aren’t the same just yet, so you can see a fairly clear division.
The debug view gives us a better sense of what is going on:
Raycasting through triangles is the same, conceptually, as raycasting through a grid. We keep casting through cells until we reach a solid cell. Now, instead of square cells with regular spacing, we have arbitrarily-sized, triangular cells.
Each raycast starts with a ray at the camera location \(\boldsymbol{p}\) heading in a direction \(\hat{\boldsymbol{d}}\). As we iterate \(\boldsymbol{p}\) will be shifted out into the world. In the first iteration, \(\boldsymbol{p}\) will be the camera location and can lie inside a triangle face. In future iterations, \(\boldsymbol{p}\) is lies on an edge that we crossed in the previous iteration.
We take the three bounding vertices \(\boldsymbol{a}\), \(\boldsymbol{b}\), and \(\boldsymbol{c}\) and intersect the line through \(\boldsymbol{p}\) with the direction \(\hat{\boldsymbol{d}}\) with AB, BC, and CA, representing each intersection point as \(\boldsymbol{p}’ = \boldsymbol{p} + t \hat{\boldsymbol{d}}\). We step forward to the edge that we hit first. That is, the edge for which \(t\) is smallest (but positive). We ignore any edge we are already on.
We start by computing \(\boldsymbol{q}\), a point far enough along \(\boldsymbol{d}\) that it should exit the triangle:
Before we calculate an intercept, we can disregard checking an edge EF if the triangle EFQ is not left-handed. This helps us avoid cases where an intersection will either never occur or lie behind our ray. For example, we can skip checking AB because ABQ is right-handed (counter-clockwise):
We should check BC, because the triangle BCQ is left-handed (clockwise):
We can now calculate the interection point’s \(t\)-value. For the edge BC, this is:
if (GetRightHandedness(b, c, q) < -eps) {
// We would cross BC
v2 v = c - b;
v2 w = p - b;
f32 t_bc = cross(v, w) / cross(q - p, v);
if (t_bc < t_min) {
t_min = t_bc;
qe_side = qe_bc;
v_face = v;
}
}
We just repeat this block three times, once for each edge. Each time we get an intersection, we keep it if it is earlier than any previous intersection. When we do, we also store the edge that we pass over (via its quarter edge in the DCEL).
Just like before, we propagate our point \(\boldsymbol{p}\) up to the new edge and then either iterate again if the new face is empty, or break out if the new face is solid.
We do have to make some minor modifications in how we access the face texture. With the grid we could safely assume that every wall was square, with a corresponding 64×64 pixel texture. Now walls can have arbitrary aspect ratios, so we have to do a tiny bit of math to index into the texture based on our intersection location along the edge:
One immediate advantage of using the DCEL is that we can leverage it for collision detection. In DOOM, collision detection is done via a blockmap, which is just a discrete 128×128 pixel grid. Each grid cell stores the lines in that block. An entity moving in a cell can just check for collision against all of the lines in the cell. The blockmap is constructed on level export, and again assumes static 2D geometry.
We don’t have to use a bockmap, because we have the DCEL. We can simply store the face that our player is in and check for collisions every time we move them. Our player movement code is the same as the player movement code in this previous blog post. Any time we would cross over a solid edge between two faces, we simply move up to the edge instead, and lose any velocity into the edge.
The current approach assumes the player is a single point. If we want, we can create a second collision mesh that uses inflated solid geometry to compensate for the player’s collision volume. We would have to keep that second mesh synchronized with any changes to the geometry mesh.
DCELs make pathing and shooting computations easy too. DCELs are primarily used in games for pathing (via Nav Meshes) and collision checking for a gunshot is just a raycast where we also care about intersections with enemies.
Game Map Representation
The biggest difference here was not so much the rendering code, but more the integration of the mesh data structure and how we represent the game map. With the Wolfenstein-style renderer we were able to represent the map using 2D arrays:
Each cell could thus be marked as solid or not depending on whether the cell’s entry in tiles is 0. Nonzero values corresponded to texture indices. Similar arrays were used for the floor and ceiling textures.
With the general 2D geometry, we no longer have a convenient text short-hand. The DCEL has a lot of pointers and is no fun to edit manually. We have to store all vertices, quarter edges, and the associations between them. We then optionally mark edges as being solid, and when we do, set edge texture information.
At this point the game map consists of two things:
a triangle mesh
optional side information
My representation for side information is pretty simple. It is just a structure with some flags, a texture id, texture x and y offsets, and the associated quarter edge:
// The information associated with one side of an edge between vertices in
// the map. If this represents the directed edge A->B, then it describes the
// edge viewed on the right side of A->B.
struct SideInfo {
u16 flags;
u16 texture_id;
i16 x_offset;
i16 y_offset;
QuarterEdgeIndex qe;
};
The map data is packed into the binary assets blob (similar to a DOOM WAD file) and loaded by the game at start.
Editing this game data is rather hard to do by hand, so I started working on an editor on the side. The editor is written in C++, and I allow myself the use of whatever libraries I want. I might go over that in more detail in a future post, but for now I just want to show how it can be used to adjust the map:
The gif here is fairly large. It may have to be viewed separately.
Having an editors gives us a place to put supporting code and lets us use more convenient data structures that aren’t streamlined for the C software renderer. The editor can then do the lifting required to export our game data into the form expected by the game.
Conclusion
The TOOM source code for this post is available here. I have been overwriting my assets file, and the new ones are no longer compatible, so unfortunately do not have a good assets file to share.
In this post we took our blocky Wolfenstein-style environment and moved to general 2D geometry. We didn’t follow DOOM and use a BSP, but instead stuck with raycasting and used a DCEL.
What we have now is much closer to DOOM, but still lacks a few things. Geometrically, we don’t have variable floor heights, which means we also don’t yet worry about wall surfaces between variable floor heights. We also aren’t animating doors or elevators, and we don’t have textures with transparency. We aren’t doing any lighting, other than manually setting some faces to be darker. DOOM really was groundbreaking.
We had a wonderful wedding, with loving friends and family members, many of which traveled pretty far to celebrate with us. It was a pretty small wedding, but it was a heartfelt one, and we put a lot of effort into things to make it the wedding we dreamed of. In this blog post I’ll cover some of the personal touches we were able to add.
TikZ Place Cards
Photo by @wendyandgeorgephoto
We had guests RSVP via a Google form, which asked them information like their name, which meal they wanted, and whether they had any food allergies. This produces a Google sheet, which I exported to CSV and loaded into a little Julia notebook. My notebook then typeset place cards for each guest, displaying their name, table assignment, meal choice, and any food allergies. This used TikZ via TikzPictures.jl, and inverted each image in order to get a fold-able card:
The script did some basic layout to produce paper sheets with multiple cards such that we could print them out with maximum effectiveness:
We had to address some corner cases, such as babies (which don’t have meals), guests with multiple allergies, and guests with long names.
We used the same approach to make a few other place cards for things like the desserts table:
Table Numbers
Each dining table had a number, and we needed a way to indicate which table was which. My partner had a fantastic idea, and made table signs with table numbers that included photos of us at that age. So, table 2 had photos of each of us at 2 years of age, table 3 had each of us at 3 years of age, etc:
Photo by @wendyandgeorgephoto
These were made in Keynote, and were printed out on photo paper and cut out by hand.
Succulent Centerpieces
We also wanted table centerpieces, but balked at the extreme price of floral arrangements. Again, my partner had a fantastic idea. She had been learning pottery, and decided that she would throw her own bowls, glaze and fire them, and then make succulent arrangements. She gradually worked on these bowls all year, learning to make bigger and better bowls as she progressed, and made some very beautiful works of art. Many of the succulents were clippings from my mom’s garden. The end result was amazing!
Photo by @wendyandgeorgephoto
Portable Piano
We wanted our best man to play the piano during the ceremony. The only problem was that we had to use a portable piano that wasn’t plugged into an electrical outlet.
Thankfully, we were able to use the best man’s electric keyboard, but said electric keyboard had to be modified to use a portable power source. After getting on YouTube, including watching a delightful video of a man playing music outdoors, we determined that building a battery was pretty straightforward. The piano takes 12v, so I ordered a 12v, 20 Ah battery.
The battery life in hours is its capacity (in amp-hours) divided by the current draw (in amps). The current draw is watts / volts, which for us is around 40 W / 12 v ~ 3.33 amps. Thus we expect the piano to last 20 Ah / 3.33 A ~ 6 hours. We figured that should be more than plenty.
I also ordered a charger, and a Yamaha piano wall wart. I cut the plug off of the wall wart and connected that, plus a fuse, to the battery:
(with lots of protective electric tape – don’t want to get shocked.)
We put the battery in the cardboard box it came in, spray painted it black, and 3d-printed a nice little cover:
We additionally 3d-printed a little wedge so that the battery could sit on the X-frame stand that supports the piano. Unfortunately, I forgot to get a photo of that.
And then there was the problem that the piano was initially dead after we borrowed it. After much troubleshooting, my partner’s internet investigations suggested that we replace one particular capacitor that was known to wear out on this brand of electric keyboard. So (with permission) we ordered it, took the piano apart, and replaced the capacitor.
Ring Box
We used the 3d printer for other things as well! My partner printed a wonderful ring box whose design she found:
Photo by @wendyandgeorgephoto
Our names are inlaid on the other side.
Homemade Desserts
You know what’s harder than making desserts for your own wedding? Transporting them to the wedding.
Enter – the Macaron Transport Vehicle (MTV). My partner is fantastic at baking macarons, and has spent something like 10 years perfecting the recipes. She baked the macarons, and also came up with the method for getting them to the venue.
Each MTV consisted of an Ikea cooler bag with a cooler-bag-bottom-sized ice pack. This could be loaded with trays of macarons, with 3d-printed spacers to allow for tray stacking. The macarons made it safe and sound, and cold!
Photo by @wendyandgeorgephoto
Making the macarons was a 3-day process. The fillings were made on Day 1, the shells on Day 2, and they were assembled on Day 3.
Wedding Favors
We wanted to have something for our guests to take home with them. We thought about giving out succulents, but figured those would be hard to travel with, and maybe guests wouldn’t want them. We figured that pretty much everyone likes chocolate.
There are services that let you make your own custom chocolate wrappers. We tried a sample or two and weren’t really blown away by the chocolate itself. So we decided to just buy chocolate bars that we liked and make our own basic sleeves:
These were made in Keynote, and were printed on heavier paper.
Funny story about the text on the back. I initially wrote something much longer, and my partner had the great idea to use ChatGPT to consolidate it a bit. It worked really well, with some minor manual adjustments.
We then tried asking it to add some chocolate puns. ChatGPT 3.5 was decidedly terrible at adding puns. It basically just inserted “choco” into the text in random places. Ah, well.
Website
Lastly, rather than use a wedding website service, I figured I had my own website already, and could just add to that. It was just a simple page based on the same HTML5 Up template that I use for my main website today. Per a friend’s suggestion, I used Leaflet and Open Street Maps to display the location of the venue and the hotel. This was also the page that guests could access the RSVP Google Form from.
Conclusion
We had a wonderful wedding, with wonderful guests and a lot of wholesome, positive energy. Things went incredibly smoothly, and the worst thing about it was how quickly it all flew by.
I think the little touches that we added made the wedding feel more personal.
I’m still on a Wolfenstein 3D kick, so this month we’re going to further extend the software render. We’re doing it in C and are manually setting individual pixels (no 3D lib). As before, I’m deriving this myself, so while we should end up with something similar to Wolfenstein 3D, things are probably not going to be a perfect match.
The last post left us with a textured blocky world. I felt like the next thing to do was to be able to populate that world.
Wolfenstein 3D (and DOOM) were before the time of 3d meshes. Enemies and set pieces (like barrels) were rendered as flat images. These billboard sprites always face the camera, since that simplifies the rendering math:
In Wolfenstein 3d, all wall textures are 64×64 images. They kept things simple and made all sprites 64×64 images as well. Unlike wall textures which were always solid, sprites have a bunch of fully transparent pixels. This was indicated using magenta.
Behold my fantastic programmer art:
We can load this image in like we do with our wall textures. Now we just have to figure out how to render it.
Render Math
Each entity has a position in 3D space. First we transform the object’s location in game space to a camera-relative space:
We’re just moving half the sprite width in either direction, then dividing by the screen’s width at the entity’s locationThe field of view is how far across the camera image is at a unit distance from the camera's origin. Scaling by the entity's distance from the camera gives us the screen's width where the entity is.. We have to flip about 0.5 because pixels go left to right in screen space, and then scale up by the number of pixels.
The image’s height is determined by the distance the entity is from the camera. The calculation is the same one we used for determining the height of walls. This gives us \(y_\text{lo}\) and \(y_\text{hi}\).
Now we can iterate from \(x_\text{lo}\) to \(x_\text{hi}\) in 1-pixel increments, rendering each column of pixels as we go between \(y_\text{lo}\) and \(y_\text{hi}\). For every \(x\)-increment of 1 pixel we move \(64 / (x_\text{hi} – x_\text{lo})\) pixels horizontally in the sprite image. Similarly, for every \(y\)-increment of 1 pixel we move \(64 / (y_\text{hi} – y_\text{lo})\) pixels vertically in the sprite image.
This gives us a billboard sprite in the correct location that scales as we move closer or farther away. Unfortunately, we’re rendering the magenta pixels and we’re drawing over walls that should be blocking our view.
We can trivially skip rendering magenta pixels with an if statement.
Fixing the wall occlusions also turns out to be pretty simple. We are rendering the entity after we render the walls. When we render the walls we have to calculate the raycast distance. We keep track of this distance for each pixel column, and only render a given entity pixel column when it is closer to the camera.
So there we have it – billboard sprites with occlusions. We first render the floors and ceilings, we then render the walls, and we then finally render all entity sprites.
DOOM Sprites
Unfortunately, my programmer art is pretty terrible. It works okay for the walls, ceilings, and floors, but it doesn’t work so well for entities.
I considered using Wolfenstein 3D sprites, but I don’t want to go with the Nazi theme. I decided to go with DOOM sprites since the assets are easily available (and have been used by modders for decades).
We have to do some work to load from the DOOM assets (stored in a WAD file). I was surprised to find that the WAD format is quite similar to the asset format I made up that I was already using. They both consist of a header, followed by a series of blobs, terminated with a table of contents. We can just load the whole thing into memory and then point to the data we need.
Wolfenstein 3D stored everything in 64×64 images. DOOM was a bigger project, with things of different sizes, and so went for a more compressed format (at the expense of added complexity). Sprites are stored as patches, which slice the image up by pixel column, and only specify continuous pixel column regions that should be drawn (ignoring transparent pixels).
We don’t have to waste any space on transparent columns:
Many columns simply consist of a single continuous range of pixels:
Some columns have several pixel intervals:
Each patch has a header defining its width and height, and its position relative to the entity’s origin. (If a monster has an arm stretched out to the left, we want to know to offset the image to the left a bit). This is followed by byte offsets to pixel data. One of the cool things here is that if two pixel columns happen to be the same, we don’t have to store them twice, but can just point to the same data.
Pixel columns are each a sequence of pixel intervals with a given offset from vertical, some number of pixels, and then the pixel values. We know we’ve reached the end when the vertical offset is 0xFF.
DOOM is restricted to a 256-color palette. The pixel data in each patch stores 1-byte indices into this palette. When rendering, we take the index and look up the appropriate color. (DOOM also has a colormap that it uses to darken things further from the camera, but I’m not doing that quite yet).
While DOOM does use billboard sprites, they also rendered each frame from 8 different viewing angles. We can determine which sprite to use for a given frame based on our viewing angle:
This gives us some nice visual continuity as we walk around the monster:
Conclusion
The code for this post is available here. The zip file contains my assets, but you’ll have to separately find the DOOM assets, since I didn’t think it’s okay to host them myself. Thank you DOOM team for making those available!
I ended up splitting my source code into multiple files, since the code was steadily growing and becoming less manageable. You’ll notice that I use fewer static functions and I pass in the objects that I use instead.
The code now generates a second window, in which I render a top-down debug view. I allow myself to use SDL_RenderDrawLine and SDL_RenderFillRect here. (They’d be pretty easy to implement myself, but whatever).
I’m not sure how far I’ll take this project. It certainly has been fun so far! Fully fleshed games are pretty involved, and as we’ve seen I am pretty limited when it comes to asset creation. I do have a neat idea that I want to try out with respect to more general 3D rendering and collision detection, and I kind of want to have some rudimentary monster fighting interactions. We’ll see.