Hard copies of Algorithms for Decision Making (available in PDF form here for free) are shipping on August 16th! This book, the second one I have been fortunate to help write, was a large undertaking that spanned 4.5 years.
Back when Algorithms for Optimization came out, I wrote a blog post that detailed aspects of the special nature of our development setup. This blog post, 4 years later, is a look at how those aspects have changed for the second book.
But first, what is Algorithms for Decision Making, and how is it different than Algorithms for Optimization?
What Alg4DM is About

Algorithms for Optimization covers the sort of decision making theory that one thinks of when considering modern artificial intelligence. Think Go AIs, aircraft collision avoidance, and using drones for wildfire suppression.
The book’s central focus is on the Markov Decision Process, or MDP. The MDP framework and its variants are simply general ways to frame decision making problems. For a problem to be represented as an MDP, you have to specify the problem’s states, its actions, how actions take you to successor states, and what rewards (or costs) you incur when doing so. Simple. The game 2048 can be formulated as an MDP, but so too can the problem of balancing investment portfolios.
Without going into too much detail (there’s an entire book, after all), the core insight of the MDP framework is that problems can be solved with dynamic programming according to the Bellman equation. All sorts of techniques stem from this, from optimal solvers for small discrete problems to fancy reinforcement learning techniques for large deep neural network policies.
The book has the following progression:
- Starts with the basics of probability and utility, and introduces Bayesian networks and how to train them. (This is because BNs were used by Mykel for ACAS-X, and are a great way to represent transition models).
- MDPs, including all sorts of fancy things including policy gradient optimization and actor-critic methods.
- Model uncertainty, where we do not know the transition and reward functions ahead of time. There is some great content on imitation learning here too.
- POMDPs, which extend MDPs to domains where we don’t observe the full state.
- Multiagent systems, which involve problems with multiple decision-making agents. Think a bunch of robots jointly solving a problem together.
How Alg4DM is Different
Alg4DM took about 4.5 years between first commits to hard-copy. There were 3,417 commits to our git repository along with 826 filed issues. The printed book is 700 pages, with 225 color figures. In comparison, Alg4Opt is 500 pages, which makes the new book 40% longer.
While sheer size is a significant factor, there were other contributing complexities that made this book more challenging to write. I am proud to say that we still define the entire book in a LaTeX document and do all of figure generation and typesetting ourselves. We continued to use the Tufte LaTeX template. We typeset the book ourselves with LaTeX (as opposed to the publisher doing the typesetting), control our own lexing and styles, and have a suite of tests. We just had to overcome some additional hurdles to do so.
Interconnected Concepts (and Code)
Alg4DM crucially differs in how interconnected the material is. The chapters build on one another, with code from later chapters using or expanding on code from earlier chapters. These dependencies vastly increased the complexity of the work. We had to find unified representations that worked across the entire book, and any changes in one place could propagate to many others.
For example, the rollout method has an MDP version that accepts states and a POMDP method that accepts beliefs. Many POMDP methods call the state version, and thus depend on previous chapters.
Textbook-wide Codebase
When writing Alg4Opt, every chapter can be compiled alone, with standalone code. This made development pretty easy. We didn’t have any central shared code and could simply rely on pythontex blocks to execute Julia code for us:

For Alg4DM, we needed later chapters to use the code from earlier chapters. As such, we needed a new tactic.
The approach we settled on was to construct a Julia package that would contain all of our code. This package would include both utility methods like plotting functions and example problem formulations, but also all of the code presented in the textbook. Algorithm blocks like the one below would be automatically detected and their contents exported into our package:
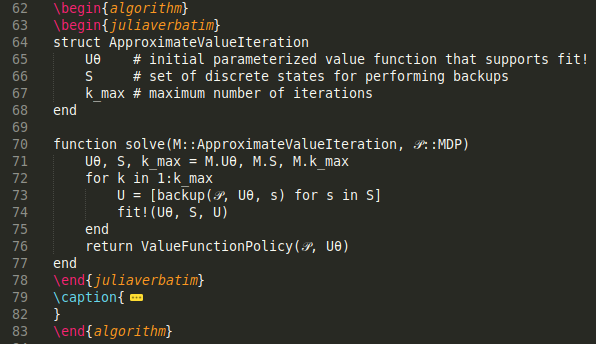
Blocks like the one above existed in Alg4Opt and resulted in typeset code, but that code never actually ran. We usually had extra copies of every algorithm that were used to _actually_ run and produce our figures. By scraping the book for our code, we could ensure that the code that was typeset was the code that we were actually using to generate our figures and run our tests. Furthermore, we could still compile chapters individually, as each chapter could just load the Julia package.
The end result looked basically like this:
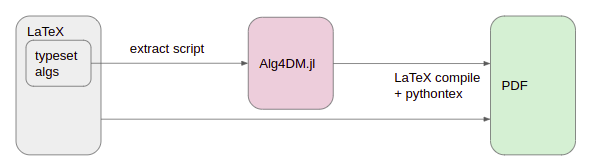
Furthermore, we improved our test setup by writing tests directly inside the .tex files alongside everything else. These test blocks would also be parsed out during extraction, and could then be used to test our code:
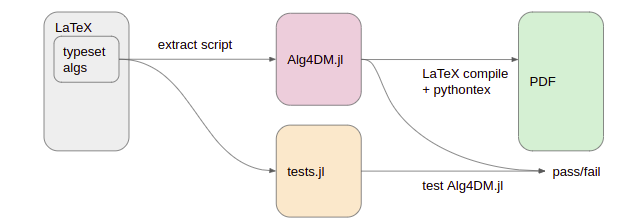
Pretty simple, and it solved a lot of problems.
Now, it wasn’t without its trade-offs. First, whenever I was working on the book, I would have to remember to first run the extraction script to make sure that I had the latest and greatest. This added overhead, and forgetting to do it caused me some hours of pain.
Second, our base support code was stored in a different repository than the LaTeX for the book. This meant that another author could update the base code and I would have to remember to check out the latest Julia package to get those updates. Again, a pain point. Now that I know how to have Julia packages that aren’t stored in the standard Julia location, we can actually move our Julia package into the main book repo and avoid this issue.
Third, loading one large central package significantly increased book, and individual chapter, compile time. For Alg4Opt, each chapter only included the packages and code it needed. For Alg4DM, every chapter includes the entire support package, which has some hefty dependencies (such as Flux.jl). While we could do more work to split out the biggest dependencies, this fundamental increase in size would definitely still be noticeable. (Yes, package precompilation helps, but only so much).
Overall, I think our solution ended up being sufficient, but there are some improvements we could make moving forward.
Bigger, Fancier Problems
Many of the example problems and implementations behind the figures in Alg4Opt were relatively simple. They were mostly all 2D optimization problems, which are very quick to run. We could compile the book quickly and regenerate the figures every time without much hassle.
In Alg4DM that was no longer the case. Training an agent policy to solve a POMDP problem takes time, even for something as simple as the mountain-car problem. Compiling the book from scratch, including recompilation of all figures from the original Julia code, would take a very, very long time. As such, there are multiple cases where we had to save the .tex code produced for a particular figure, comment out the code that generated it, and include that instead:
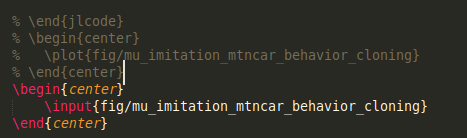
This change was pretty seamless and easy to execute. It did not disrupt our workflow much. Furthermore, because we were still producing the PDF from .tex input, the figure would still be recompiled with the latest colors and formatting. The primary incurred overhead was remembering when to regenerate a figure because something underneath changed, such as the algorithm, something it calls, or the problem definition it was run on.
Breaking it Down in ways it hasn’t been Broken Down Before
The content covered in the optimization book was more intuitive for me, in many ways. While there certainly was some synthesis / repackaging of ideas, the amount of ground that had to be covered with respect to the new book was far greater.
The decision making book covers a large span of academic literature. We’ve got Bayesian networks, deep learning, traditional MDPs and POMDPs, imitation learning, reinforcement learning, multiagent planning, Markov games, and more. We needed consistent nomenclature that didn’t have overlapping concepts, while staying as true as possible to the literature. (For example, we spent a long time deciding what the symbol for a conditional plan would be. That issue took over a year to resolve.)
Furthermore, as with the first book, the 2nd book tries to cover the principle components of the algorithmic ideas. That is, we break down the little nuggets of progress. An algorithm like SARSOP has a lot of ideas inside of it, and we break those apart rather than presenting the SARSOP algorithm as a whole. Similarly, 1D optimization is often solved with Brent’s method, but you won’t find Brent’s method in our first book. You will, however, find the bisection, secant, and inverse quadratic interpolation methods – all methods that are used inside of Brent’s method.
Perhaps the greatest contribution this text makes is how we cover policy gradient optimization. We tease many of the concepts apart and present them individually in a way I haven’t seen before. The restricted gradient update naturally evolves into the natural gradient update, which evolves into a trust region update, etc. That chapter, and the actor-critic chapter thereafter, where the hardest ones for me to write, but I am quite happy with the result.
Conclusion
And that’s it! The new book is something I worked very hard on and it came out great. Mykel and Kyle worked very hard on it to, we got a ton of feedback from all sorts of helpful individuals, and we had great support from MIT Press and their editors.
I’ve been really fortunate to have been able to write this book with Mykel and Kyle. Decision-making is Mykel’s specialty, and Kyle has a lot of valuable multiagent knowledge (and is extremely detail-oriented and perceptive). I learned a lot doing the course of Alg4DM’s development, and I hope that its readers can learn a lot as well.