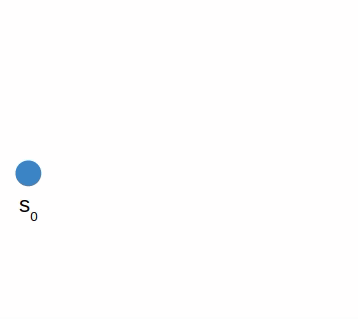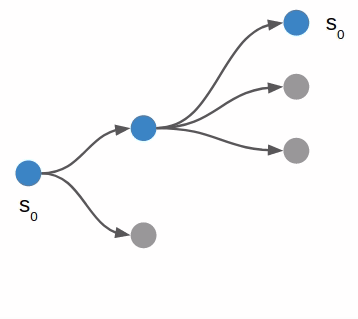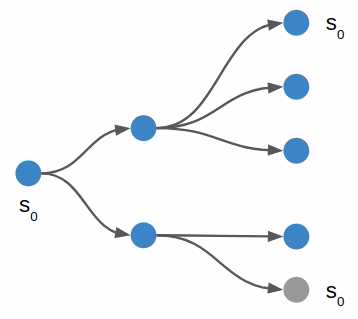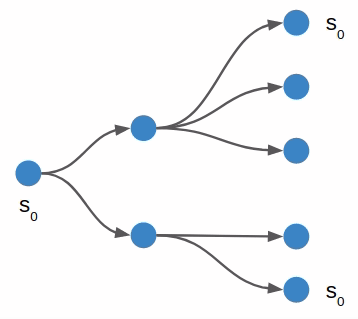Hard copies of Algorithms for Decision Making (available in PDF form here for free) are shipping on August 16th! This book, the second one I have been fortunate to help write, was a large undertaking that spanned 4.5 years.
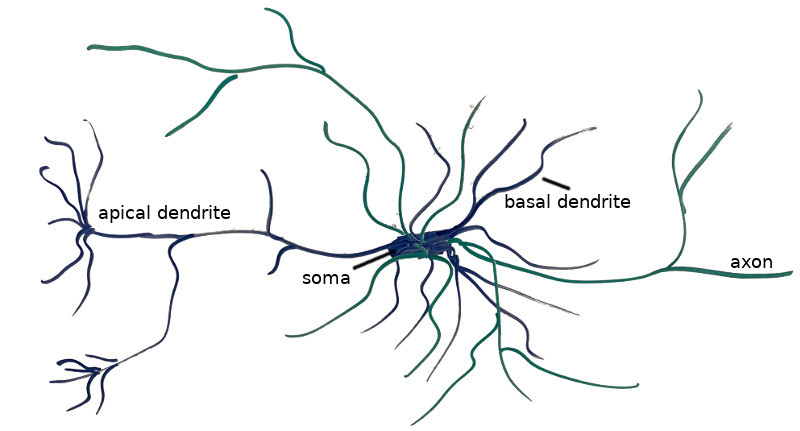
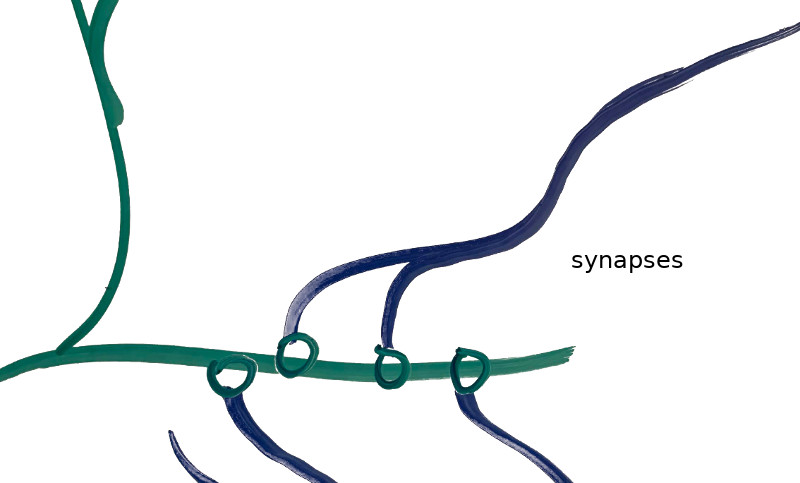
The book’s central focus is on the Markov Decision Process, or MDP. The MDP framework and its variants are simply general ways to frame decision making problems. For a problem to be represented as an MDP, you have to specify the problem’s states, its actions, how actions take you to successor states, and what rewards (or costs) you incur when doing so. Simple. The game 2048 can be formulated as an MDP, but so too can the problem of balancing investment portfolios.
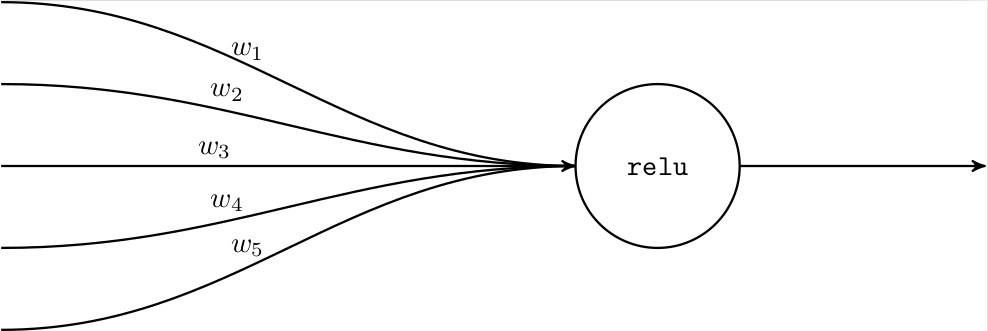
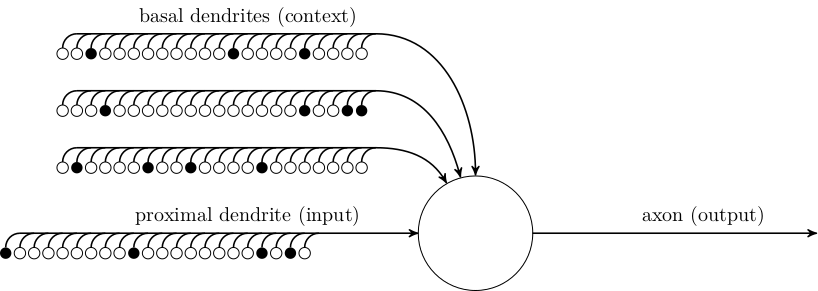
Without going into too much detail (there’s an entire book, after all), the core insight of the MDP framework is that problems can be solved with dynamic programming according to the Bellman equation. All sorts of techniques stem from this, from optimal solvers for small discrete problems to fancy reinforcement learning techniques for large deep neural network policies.
The book has the following progression:
Starts with the basics of probability and utility, and introduces Bayesian networks and how to train them. (This is because BNs were used by Mykel for ACAS-X, and are a great way to represent transition models).
MDPs, including all sorts of fancy things including policy gradient optimization and actor-critic methods.
Model uncertainty, where we do not know the transition and reward functions ahead of time. There is some great content on imitation learning here too.
POMDPs, which extend MDPs to domains where we don’t observe the full state.
Multiagent systems, which involve problems with multiple decision-making agents. Think a bunch of robots jointly solving a problem together.
How Alg4DM is Different
Alg4DM took about 4.5 years between first commits to hard-copy. There were 3,417 commits to our git repository along with 826 filed issues. The printed book is 700 pages, with 225 color figures. In comparison, Alg4Opt is 500 pages, which makes the new book 40% longer.
While sheer size is a significant factor, there were other contributing complexities that made this book more challenging to write. I am proud to say that we still define the entire book in a LaTeX document and do all of figure generation and typesetting ourselves. We continued to use the Tufte LaTeX template. We typeset the book ourselves with LaTeX (as opposed to the publisher doing the typesetting), control our own lexing and styles, and have a suite of tests. We just had to overcome some additional hurdles to do so.
Interconnected Concepts (and Code)
Alg4DM crucially differs in how interconnected the material is. The chapters build on one another, with code from later chapters using or expanding on code from earlier chapters. These dependencies vastly increased the complexity of the work. We had to find unified representations that worked across the entire book, and any changes in one place could propagate to many others.
For example, the rollout method has an MDP version that accepts states and a POMDP method that accepts beliefs. Many POMDP methods call the state version, and thus depend on previous chapters.
Textbook-wide Codebase
When writing Alg4Opt, every chapter can be compiled alone, with standalone code. This made development pretty easy. We didn’t have any central shared code and could simply rely on pythontex blocks to execute Julia code for us:
A jlcode block that executes Julia code and produces a plot in the first book.
For Alg4DM, we needed later chapters to use the code from earlier chapters. As such, we needed a new tactic.
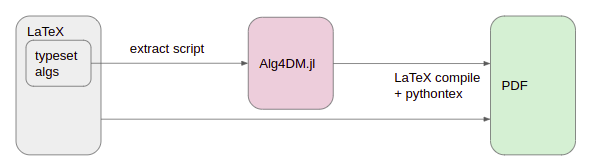
The approach we settled on was to construct a Julia package that would contain all of our code. This package would include both utility methods like plotting functions and example problem formulations, but also all of the code presented in the textbook. Algorithm blocks like the one below would be automatically detected and their contents exported into our package:
Blocks like the one above existed in Alg4Opt and resulted in typeset code, but that code never actually ran. We usually had extra copies of every algorithm that were used to _actually_ run and produce our figures. By scraping the book for our code, we could ensure that the code that was typeset was the code that we were actually using to generate our figures and run our tests. Furthermore, we could still compile chapters individually, as each chapter could just load the Julia package.
The end result looked basically like this:
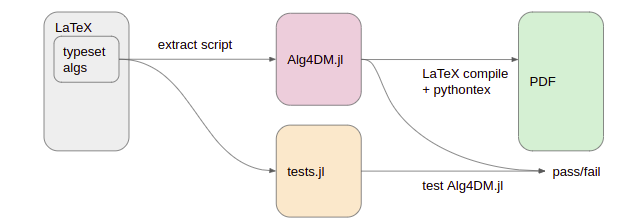
Furthermore, we improved our test setup by writing tests directly inside the .tex files alongside everything else. These test blocks would also be parsed out during extraction, and could then be used to test our code:
Pretty simple, and it solved a lot of problems.
Now, it wasn’t without its trade-offs. First, whenever I was working on the book, I would have to remember to first run the extraction script to make sure that I had the latest and greatest. This added overhead, and forgetting to do it caused me some hours of pain.
Second, our base support code was stored in a different repository than the LaTeX for the book. This meant that another author could update the base code and I would have to remember to check out the latest Julia package to get those updates. Again, a pain point. Now that I know how to have Julia packages that aren’t stored in the standard Julia location, we can actually move our Julia package into the main book repo and avoid this issue.
Third, loading one large central package significantly increased book, and individual chapter, compile time. For Alg4Opt, each chapter only included the packages and code it needed. For Alg4DM, every chapter includes the entire support package, which has some hefty dependencies (such as Flux.jl). While we could do more work to split out the biggest dependencies, this fundamental increase in size would definitely still be noticeable. (Yes, package precompilation helps, but only so much).
Overall, I think our solution ended up being sufficient, but there are some improvements we could make moving forward.
Bigger, Fancier Problems
Many of the example problems and implementations behind the figures in Alg4Opt were relatively simple. They were mostly all 2D optimization problems, which are very quick to run. We could compile the book quickly and regenerate the figures every time without much hassle.
In Alg4DM that was no longer the case. Training an agent policy to solve a POMDP problem takes time, even for something as simple as the mountain-car problem. Compiling the book from scratch, including recompilation of all figures from the original Julia code, would take a very, very long time. As such, there are multiple cases where we had to save the .tex code produced for a particular figure, comment out the code that generated it, and include that instead:
An example of how a figure is loaded from its intermediary .tex file rather than being regenerated from source code every time.
This change was pretty seamless and easy to execute. It did not disrupt our workflow much. Furthermore, because we were still producing the PDF from .tex input, the figure would still be recompiled with the latest colors and formatting. The primary incurred overhead was remembering when to regenerate a figure because something underneath changed, such as the algorithm, something it calls, or the problem definition it was run on.
Breaking it Down in ways it hasn’t been Broken Down Before
The content covered in the optimization book was more intuitive for me, in many ways. While there certainly was some synthesis / repackaging of ideas, the amount of ground that had to be covered with respect to the new book was far greater.
The decision making book covers a large span of academic literature. We’ve got Bayesian networks, deep learning, traditional MDPs and POMDPs, imitation learning, reinforcement learning, multiagent planning, Markov games, and more. We needed consistent nomenclature that didn’t have overlapping concepts, while staying as true as possible to the literature. (For example, we spent a long time deciding what the symbol for a conditional plan would be. That issue took over a year to resolve.)
Furthermore, as with the first book, the 2nd book tries to cover the principle components of the algorithmic ideas. That is, we break down the little nuggets of progress. An algorithm like SARSOP has a lot of ideas inside of it, and we break those apart rather than presenting the SARSOP algorithm as a whole. Similarly, 1D optimization is often solved with Brent’s method, but you won’t find Brent’s method in our first book. You will, however, find the bisection, secant, and inverse quadratic interpolation methods – all methods that are used inside of Brent’s method.
Perhaps the greatest contribution this text makes is how we cover policy gradient optimization. We tease many of the concepts apart and present them individually in a way I haven’t seen before. The restricted gradient update naturally evolves into the natural gradient update, which evolves into a trust region update, etc. That chapter, and the actor-critic chapter thereafter, where the hardest ones for me to write, but I am quite happy with the result.
Conclusion
And that’s it! The new book is something I worked very hard on and it came out great. Mykel and Kyle worked very hard on it to, we got a ton of feedback from all sorts of helpful individuals, and we had great support from MIT Press and their editors.
I’ve been really fortunate to have been able to write this book with Mykel and Kyle. Decision-making is Mykel’s specialty, and Kyle has a lot of valuable multiagent knowledge (and is extremely detail-oriented and perceptive). I learned a lot doing the course of Alg4DM’s development, and I hope that its readers can learn a lot as well.
I spent a good while translating portions of the YASS Pascal code into Julia. I wanted to see how a larger, more sophisticated Sokoban solver works.
YASS (Yet Another Sokoban Solver), by Brian Damgaard, touts the use of a packing order calculation. I spent many hours trying to figure out what this was, and in the end boiled down the fundamental idea: it is a macro search where, instead of using individual box moves, the actions consist of either pushing a box all the way to a goal tile, or pushing a box as far away from its current position as possible with the hope that that frees up space for other boxes. That’s it.
Sokoban solvers typically reason about individual pushes. Above we show the legal pushes for the current game state.
The macro actions available from the start state. These actions allow us to push a box to a goal (as shown with the right box) or to two possible farthest-away tiles.
The devil, of course, is in the details. YASS has a lot of additional bells and whistles, such as using deadlock sets and a special phase in which a box comes from a relatively small area of the board. This post merely looks at the core idea.
A Coarser Problem Representation
As mentioned above, most Sokoban solvers reason about pushes. This is already a coarser problem representation than basic Sokoban, where the actions are individual player moves. The coarser representation significantly reduces the size of the search tree. The player can move in four directions, so by collapsing ten moves that lead to a box push we can nicely remove O(4^10) possible states in our search tree.
Generally speaking, reasoning with a coarser problem representation lets us tackle larger problems. The larger, “chunkier” actions let us get more done with less consideration. The trade-off is that we give up fine-tune adjustments. When it comes to player moves vs. box pushes this is often well worth it. For the macro moves in packing order calculations, that is less true. (More on that later).
A notional image showing search with a high-fidelity representation (blue, ex: player moves) versus search with a coarse representation (magenta, ex: push moves).
If we solve a problem in a coarser representation, we need to be able to transform it back into the finer representation:
We need to be able to transform from macro actions back to our finer representation.
Transforming box pushes back into player moves is easy, as we simply find the shortest path for the player to the appropriate side of the box, and then tack on the additional step to push the box. In this case, we have a well-defined way to find the (locally) optimal sequence of player moves in order to complete the push.
The macro actions taken in the pure version of the packing order calculation I implemented work the same way. We simply calculate the push distance between tiles and find the shortest push path to the destination tile. As such, packing order macro actions are converted to pushes, which in turn can be converted to player moves.
Packing Order Search
Search problems are defined by their states, actions, and goalsand sometimes reward. Our coarser problem for packing order search is:
States – the same as Sokoban, augmented with an additional state for each box. For each box, we keep track of whether it is:
unmoved
temporarily parked
permanently parked
Actions:
An unmoved box can either be temporarily parked or pushed all the way to a goal, assuming the destination is reachable only by pushing that box.
A temporarily parked box can be pushed all the way to a goal, assuming the destination is reachable only by pushing that box. (It cannot be temporarily re-parked.)
YASS computes up to two candidate temporary parking tiles for each box:
the farthest tile in Manhattan distance from the box’s current position
the farthest tile in push distance from the box’s current position
Goals – the same as Sokoban. All boxes on goals.
Several things are immediately apparent. First, we can bound the size of our search tree. Every box can be moved at most twice. As such, if we have b boxes, then we can have at most 2^b macro actions. This in turn makes it obvious that not every problem can be solved with this search method. The search method, as is, is incomplete. Many Sokoban problems require moving a single box multiple times before bringing it to a goal. We could counteract that by allowing multiple re-parks, but we quickly grow our search tree if we do so.
The number of actions in a particular state is fairly large. A single box can be pushed to every goal it can reach, and can be parked on up to two possible candidate tiles. Since the number of goals is the same as the number of boxes, this means we have up to (2+b)^b actions in a single state. (Typically far less than that). As such, our tree is potentially quite fanned out. (In comparison, solving for box pushes has at most 4b actions in a single state).
Here we see how the two lower-right boxes each only have one stashing location, but the upper-left box can be pushed to any goal or stashed next to the goals. (Note that we do not stash boxes in tiles from which they cannot be retrieved.)
We can apply pretty much any of the basic search algorithms from my previous post to this coarser problem representation. I just went with a basic depth-first search.
Below we can see a solution for a basic 3-box problem, along with its backed-out higher-fidelity versions:
Macro ActionsBox PushesPlayer Moves
While illustrative and a neat experience, this basic depth-first packing order search is not particularly great at solving Sokoban problems. It does, however, nicely illustrate the idea of translating between problem representations.
Reverse Packing Order Search
The packing order calculation done by YASS performs its search in reverse. That is, rather than starting with the initial board state and trying to push boxes to goals, it starts with all boxes on goals and tries to pull them to their starting states.
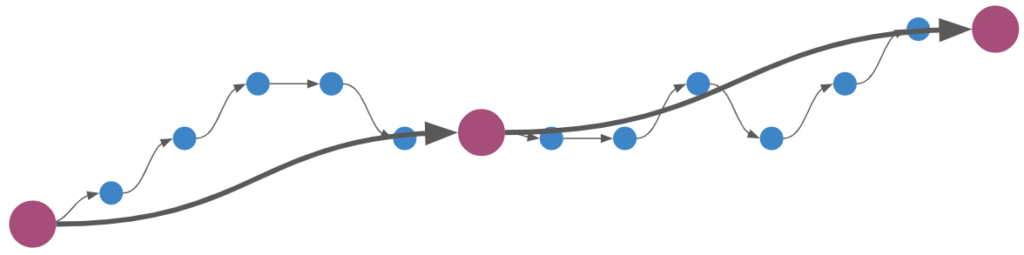
Reverse search and its various forms (ex: bidirectional search), are motivated by the fact that searching in the forward direction alone may not be as easy as the reverse direction. One common example is a continuous-space path finding problem in which the search has to find a way through a directional bottleneck:
A search from the start to the goal would likely have trouble to finding its way through the narrow opening, whereas a search from the goal to the start can be nicely funneled out.
The motivation for a reverse search in Sokoban is similar. However, rather than having to thread the needle through directional bottlenecks, Sokoban search has to avoid deadlock states. Reverse search is motivated by the idea that it is easier to get yourself into a deadlock state by pushing boxes than it is to get yourself into deadlock states by pulling boxes. This technique is presented in this paper by Frank Takes. Note that deadlocks are still possible – they just occur less frequently. That being said, 2×2 deadlocks won’t occur, the box cannot be pulled up against a wall or in a corner, etc.
The starting state in a reverse search is a goal state – all boxes on goals. Note that we do not know where the player should start – they would end up next to one of the boxes. As such, we have to consider all player-reachable regions surrounding the goals. Below we show the initial state for a problem and three possible reverse search start states:
Original Start StateReverse Start State 1Reverse Start State 2Reverse Start State 3
My simple solver simply tries each possible start state until it finds a solution (or fails after exhausting all possibilities).
Reverse packing order search does perform betterAs measured by how many puzzles it can solve in 10s each on a test set than packing order search. It still suffers from incompleteness, and would need to be fleshed out with more bells and whistles to be useful (deadlock analysis, goal room packing, etc.). That being said, we can solve some problems that are too big for my previous version of A*, such as Sasquatch 49. We solve it in 0.002s.
Macro Actions (Pulls)
The push solution backed out from the macro-pull solution.
The player-move solution.
So there you have it, a simple solver that can handle an 8-box problem. Granted, it cannot solve most 8-box problems, but we have blazed a bit of a trail forward.
The main takeaway here is that one of the best ways to scale to larger problems is to reason with a coarser problem representation. We don’t plan every footstep when deciding to walk to the kitchen. Similarly, we reason about overall street routes when planning to drive somewhere, rather than thinking about every lane change (usually). Multi-level planning can be incredibly powerful – we just have to be careful to be able to back out feasible solutions, and not miss important details.
Let’s work through how one might (in a broad sense) write a controller for guiding rockets under propulsive control for a pinpoint landing. Such a “planetary soft landing” is central to landing exploratory rovers and some modern rockets. It is also quite an interesting optimization problem, one that starts off seemingly hairy but turns out to be completely doable. There is something incredible about landing rockets, and there is something awesome and inspiring about the way this math problem lets us do just that.
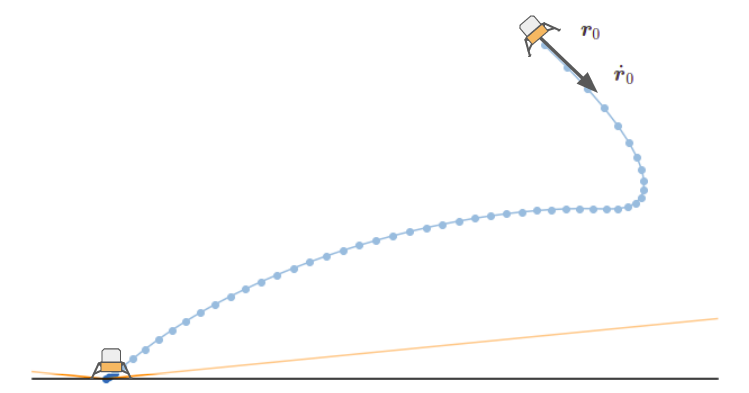
We have a rocket. Our rocket is falling fast, and we wish to have it stop nice and gently on the surface of our planet. We will get it to stop gently by having the rocket use its thruster (or thrusters) to both slow itself down and navigate to a desired landing location.
As such, our problem is to find a thrust control profile \(\boldsymbol{T}_c\) to produce a trajectory from an initial position \(\boldsymbol{r}_0\) and initial velocity \(\dot{\boldsymbol{r}}_0\) to a final position at the landing pad with zero final velocity. As multiple trajectories may be feasible, we’ll choose the one that minimizes our fuel use.
We model the rocket as a point-mass. This is done both because it is a lot easier, but also because rockets are pretty stable and we want to maintain a vertical orientation, and any attitude control that we would need has much faster-acting dynamics that we could control separately.
Dynamics
Our state at a given point in time is given by both the physical state \(\boldsymbol{x} = [\boldsymbol{r}, \dot{\boldsymbol{r}}]\) consisting of the position and the velocity, and the rocket’s mass \(m\). I am going to do the derivation in 2D, but it is trivial to extend all of this to the 3D case.
for input vectors \([\boldsymbol{r}, \dot{\boldsymbol{r}}]\).
Our mass dynamics are \(\dot{m} = -\alpha \|\boldsymbol{T}_c(t)\|\), where the mass simply decreases in proportion to the thrust. Here \(\alpha\) is the constant thrust-specific fuel consumption that determines our rate of mass loss per unit of thrust.
Let us assume that we specify the time until landingThe paper covers methods for finding the minimum-time trajectory as well. I talk about that a bit at the end of this post., such that \(t\) runs from zero to \(t_f\).
Adding Constraints
We can take these dynamics and construct an optimization problem that finds a thrust control profile that brings us from our initial state to our final state with the minimum amount of fuel use. There are, however, a few additional constraints that we need to add.
First, we do not want our rocket to go below ground. The way this was handled in the paper was by adding a simple glide-slope constraint that prevents the rocket’s position from ever leaving a cone above the landing location. This ensure that we remain a safe distance above the ground. In 2D this is:
\[r_y(t) \geq \tan(\gamma_\text{gs}) r_x(t) \quad \text{for all } t\]
where \(r_x(t)\) and \(r_y(t)\) are our horizontal and vertical positions at time \(t\), and \(\gamma_\text{gs} \in [0,\pi/2]\) is a glide slope angle.
Next, we need to ensure that we do not use more fuel than what we have available. Let \(m_\text{wet}\) be our wet mass (initial rocket mass, consisting of the rocket plus all fuel), and \(m_\text{dry}\) be our dry mass (just the mass of the rocket – no fuel). Then we need our mass to remain above \(m_\text{dry}\).
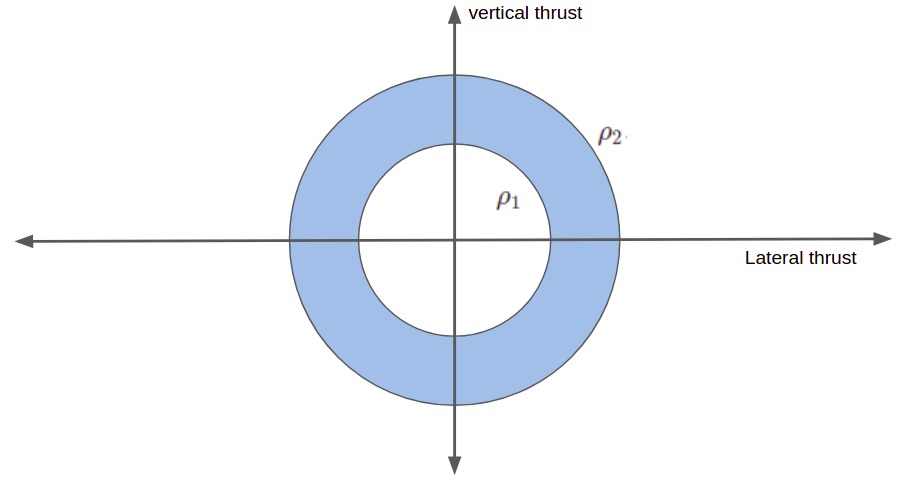
Finally, we have some constraints with respect to our feasible thrust. First off, we cannot produce more thrust than our engine provides: \(\|\boldsymbol{T}_c\| \leq \rho_2\). Secondarily, we also cannot produce less thrust than a certain minimum: \(0 < \rho_1 \leq \|\boldsymbol{T}_c\|\). This lowerbound is caused by many rocket engines being physically unable to reduce thrust to zero without going out. Unfortunately, it is a non-convex constraint, and we will have to work around it later.
The thrust magnitude constraints are nonconvex, because we can draw a line between two feasible points and get a non-feasible point.
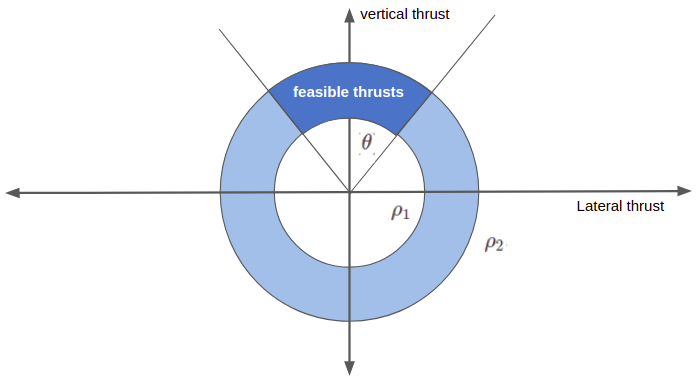
The last thrust constraint has to do with how far we can actuate our rocket engines. We are keeping our rocket vertically aligned during landing, and often have a limited ability to gimbal the engine. We introduce a thrust-pointing constraint that limits our deviation from vertical to within an angle \(\theta\):
The basic problem formulation above is difficult to solve because it is nonconvex. Finding a way to make it convex would make it far easier to solve.
Our issues are the nonconvex thrust bounds and the division by mass in our dynamics.
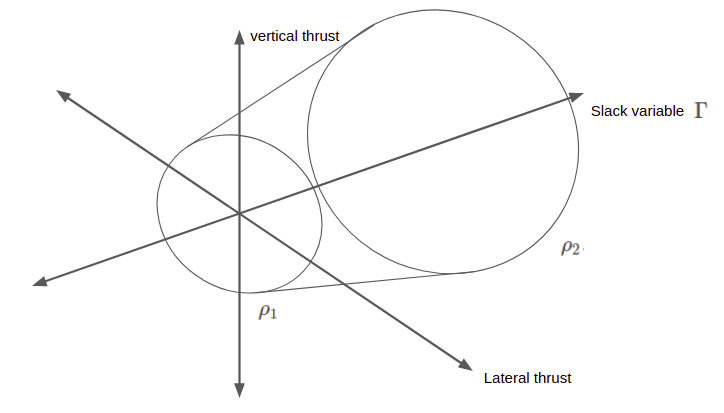
To get around the thrust bounds, we introduce an additional slack variable, \(\Gamma(t)\). We use this slack variable in our thrust bounds constraint and mass dynamics, and constrain our actual thrust magnitude to lie below \(\Gamma\):
\[\dot{m}(t) = -\alpha \Gamma\]
\[\|\boldsymbol{T}\|_c(t) \leq \Gamma(t)\]
\[0 < \rho_1 \leq \Gamma(t) \leq \rho_2\]
\[ \boldsymbol{T}_{c,y}(t) \geq \cos(\theta) \Gamma(t) \]
Introducing the slack variable has formed a convex feasible region. Note that, suddenly, thrusts that were previously illegal are now legal (those with small magnitude). However, the problem definition guarantees that our optimal solution will lie on the surface of this truncated cone. All such points satisfy the thrust bounds. I think this is one of the coolest parts of the whole derivation.
On the one hand, we have introduced a new time-varying quantity, and have thus increased the complexity of our problem. However, by introducing this quantity, we have made our constraints convex. This trade-off will be well worth it.
We can get around the nonconvex division by mass with a change of variables:
It can be shown that if there is a feasible solution to the first problem, then that solution also defines a feasible solution to this new problem. Furthermore, this solution is an optimal solution of the new problem. (This is related to the fact that \(\boldsymbol{u}\) is not minimized – we only care about minimizing \(\boldsymbol{\sigma}\), but for physical feasibility we end up needing \(\boldsymbol{u} = \boldsymbol{\sigma}\)).
Discretization in Time
The final problem transformation involves moving from a continuous formulation to a discrete formulation, such that we can actually implement a numerical algorithm. We discretize time into \(n\) equal-width periods such that \(n \Delta t = t_f\):
\[t^{(k)} = k \Delta t, \qquad k = 0, \ldots, n\]
Our thrust profile is a continuous function of time. We construct it as a combination of \(n+1\) basis functions, \(\phi_{0:n}\):
where the \(\boldsymbol{p}^{(k)} \in \mathbb{R}^3\) are mixing weights that we will optimize. Note that we did not have to have as many basis functions as discrete points – it just makes the math easier. Various basis functions can be used, but the paper uses the sawtooth:The sawtooth form makes for a continuous thrust profile. When I first tackled this problem as part of a class project, Bryant and I used a piecewise-constant basis function. That was simpler, but the control trajectory is discontinuous.
Our system state is \([\boldsymbol{r}(t)^\top, \dot{\boldsymbol{r}}(t)^\top, z(t)]^\top\) with the continuous-time system dynamics:We have a linear system. The 'c' subscripts are for 'continuous'.
In order to discretize, we would like to have a linear equation to get our state at every discrete time point. We know that the solution to the ODE \(\dot{x} = a x + b u\) is:
We then substitute in our basis function formulation:Note that only two components contribute to a given discrete time interval.
\[ \begin{split} \mathtt{x}^{(k+1)} &= \left[e^{\boldsymbol{A_c}\Delta t}\right] \mathtt{x}^{(k)} + \int_0^{\Delta t} e^{\boldsymbol{A_c}(\Delta t-\tau)} \left(\boldsymbol{B}_c \left( \boldsymbol{p}^{(k)} \phi^{(k)}(t) + \boldsymbol{p}^{(k+1)} \phi^{(k+1)}(t) \right) + \mathtt{g}\right) \> d\tau \\ & = \left[e^{\boldsymbol{A_c}\Delta t}\right] \mathtt{x}^{(k)} + \int_0^{\Delta t} e^{\boldsymbol{A_c}(\Delta t-\tau)} \left(\boldsymbol{B}_c \left( \left( 1- \frac{\tau}{\Delta t}\right) \boldsymbol{p}^{(k)} + \left( \frac{\tau}{\Delta t}\right) \boldsymbol{p}^{(k+1)} \right) + \mathtt{g}\right) \> d\tau \\ & = \left[e^{\boldsymbol{A_c}\Delta t}\right] \mathtt{x}^{(k)} + \left[\int_0^{\Delta t} e^{\boldsymbol{A_c}(\Delta t-\tau)} \boldsymbol{B}_c\right] \left( \boldsymbol{p}^{(k)} + \mathtt{g} \right) + \left[\int_0^{\Delta t} e^{\boldsymbol{A_c}(\Delta t-\tau)} \boldsymbol{B}_c \frac{\tau}{\Delta t}\right] \left( \boldsymbol{p}^{(k+1)} – \boldsymbol{p}^{(k)} \right) \\ &= \boldsymbol{A}_d \texttt{x}^{(k)} + \boldsymbol{B}_{d1} \left( \boldsymbol{p}^{(k)} + \mathtt{g} \right) + \boldsymbol{B}_{d2} \left( \boldsymbol{p}^{(k+1)} – \boldsymbol{p}^{(k)} \right) \end{split} \]
Our discrete update equation is thus also linear.I personally find this part of the derivation very satisfying. We go from a continuous ODE to nice discrete update steps. The math works out quite nicely. This analysis is super useful - linear systems like the one we are working with here show up all the time. We can compute our matrices once using numerical methods for integration. We can apply our relation recursively to get our state at any discrete time point. All of these updates are linear:
We can pull all of this together and construct a discrete-time optimization problem. We optimize the vector \(\boldsymbol{\eta}\), which simply contains all of the \(\boldsymbol{p}\) vectors:
This final formulation is a finite-dimensional second-order cone program (SOCP). It can be solved by standard convex solvers to get a globally-optimal solution.
Note that we only apply our constraints at the discrete time points. This tends to be sufficient, due to the linear nature of our dynamics.
Coding it Up
I coded this problem up usingI actually did all of this in Julia first, via Convex.jl, but struggled to get the solver to produce results (both in a reasonable amount of time, and often at all). I ended up translating everything to Python and it worked remarkably well.cvxpy. My python notebook is available here.
Update: I originally did the implementation in Julia, but found odd behavior with the Convex.jl solvers I was using. I tried both SCS (the default recommended solver for Convex.jl) and COSMO. Neither of these solvers worked for the propulsive landing problem. Both solvers had the same behavior – they would find a solution that satisfied the terminal conditions, but would fail to satisfy the other constraints. Giving it more iterations would cause it to slowly make progress on the other constraints, but eventually it would give up and decide the problem is infeasible.
Prof. Kochenderfer noticed that Julia didn’t work for me, and recommended that I try ECOS. I swapped that in and it just worked. My Julia notebook is available here.
import cvxpy as cp
import numpy as np
import scipy
We define our parameters, which I adapted from the paper:
m_wet =2000.0# rocket wet mass [kg]
m_dry =300.0# rocket dry mass [kg]
thrust_max =24000.0# maximum thrust
ρ1=0.2 * thrust_max # lower bound on thrust
ρ2=0.8 * thrust_max # upper bound on thrust
α =5e-4# rocket specific impulse [s]
θ = np.deg2rad(30)# max thrust angle deviation from vertical [rad]
γ = np.deg2rad(15)# no-fly bounds angle [rad]
g =3.71# (martian) gravity [m/s2]
tf =52.0# duration of the simulation [s]
n_pts =50# number of discretization points# initial state (x,y,x_dot,y_dot,z)
x0 = np.array([600.0,1200.0,50.0, -95.0, np.log(m_wet)])
We then compute some derived parameters:
t = np.linspace(0.0, tf, n_pts)# time vector [s]
N =len(t) - 2# number of control nodes
dt = t[1] - t[0]
We compute \(\boldsymbol{A}_c\) and \(\boldsymbol{A}_d\):
Ac = np.vstack((
np.hstack((np.zeros((2,2)), np.eye(2), np.zeros((2,1)))),
np.hstack((np.zeros((2,2)), np.zeros((2,2)), np.zeros((2,1)))),
np.zeros((1,5))))
Ad = scipy.linalg.expm(Ac * dt)
We compute \(\boldsymbol{B}_c\), \(\boldsymbol{B}_{d1}\), and \(\boldsymbol{B}_{d2}\):
We can extract our solution (thrust profile and trajectory) as follows:
η_eval = η.value
xk = np.zeros((len(x0),len(t)))for(i,k)inenumerate(range(0,N)):
xk[:,i]= get_xk(Ad, Bd1, Bd2, η_eval, x0, g3, k)
xs = xk[0,:]
ys = xk[1,:]
us = xk[2,:]
vs = xk[3,:]
zs = xk[4,:]
mass = np.exp(zs)
u1 = η_eval[0::3]
u2 = η_eval[1::3]
σ = η_eval[2::3]
Tx = u1 * mass
Ty = u2 * mass
Γ = σ * mass
thrust_mag =[np.hypot(Tyi, Txi)for(Txi, Tyi)inzip(Tx, Ty)]
thrust_ang =[np.arctan2(Txi, Tyi)for(Txi, Tyi)inzip(Tx, Ty)]
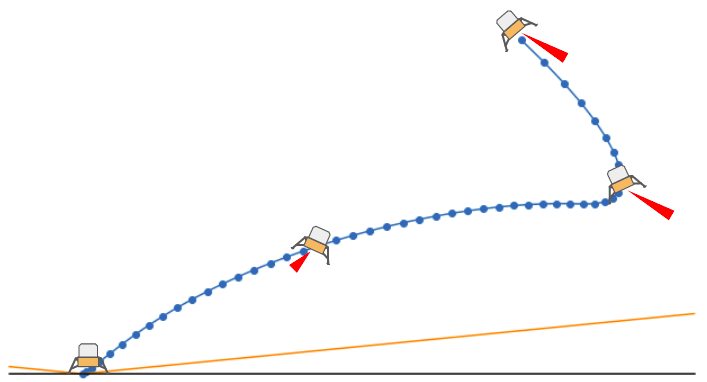
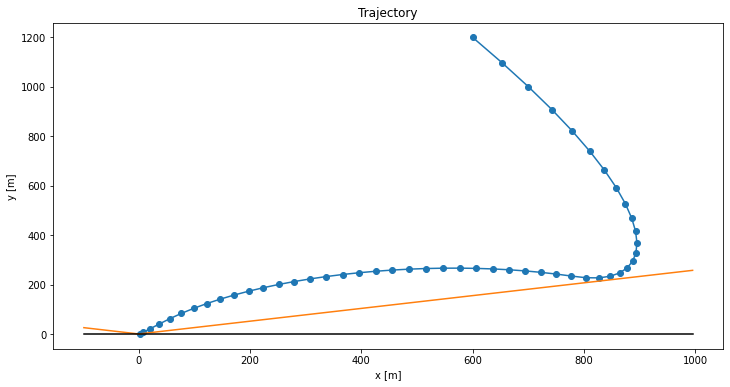
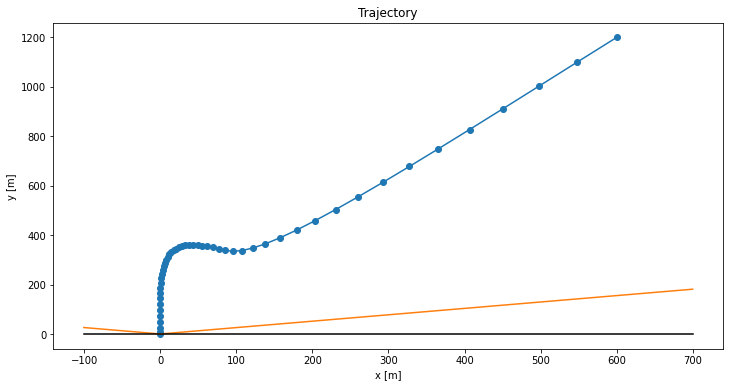
The plots end up looking pretty great. Here is the landing trajectory we get for the code above:
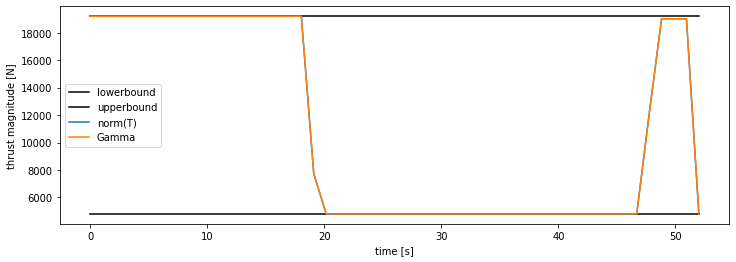
The blue line shows the rocket’s position over time, the orange line shows the no-fly boundary, and the black line shows the ground (\(y = 0\)). The rocket has to slow down so as to avoid the no-fly zone (orange), and then nicely swoops in for the final touchdown. Here is the thrust profile:
Our thrust magnitude matches our slack variable \(\Gamma\), as expected for optimal trajectories. We also see how the solution “rides the rails”, hitting both the upper and lower bounds. This is very common for optimal control problems – we use all of the control authority available to us.
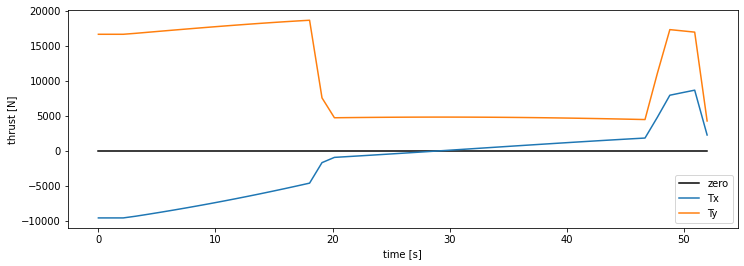
The two thrust components look like this:
We see that \(T_y\) stays positive, as it should. However, \(T_x\) starts off negative to move the rocket left, and then counters in order to stick the landing.
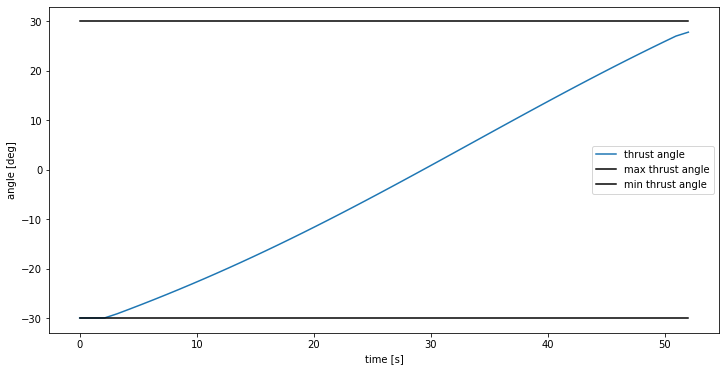
Our thrust angle stays within bounds:
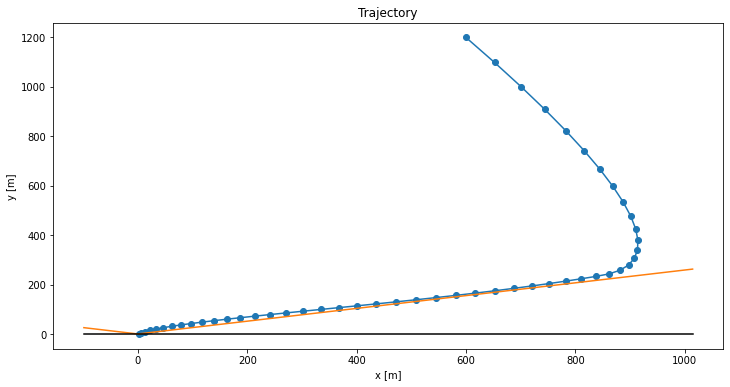
We can of course play around with our parameters and initial conditions to get different trajectories. Here is what happens if we flip the initial horizontal velocity:
Here is what happens if we increase the minimum thrust to \(\rho_1 = 0.3 T_\text{max}\):
How to Avoid Specifying the Trajectory Duration
One remaining issue with the convex formulation above is that we have to specify our trajectory duration, \(t_f\). This, and \(n\), determine \(\Delta t\) and our terminal condition, both of which are pretty central to the problem.
We might be interested, for example, in finding the minimum-time landing trajectory. Typically, the longer the trajectory, the more fuel that is used, so being able to reduce \(t_f\) automatically can have big benefits.
Once we have a procedure to compute the fuel optimal trajectory for a given time-of-flight, \(t_f\), we use the Golden search algorithm to determine the time-of-flight with the least fuel need, \(t^*_f\). This line search algorithm is motivated by the observation that the minimum fuel is a unimodal function of time with a global minimum
Behcet Acikmese, Lars Blackmore, Daniel P. Scharf, and Aron Wolf
I would be surprised if there were a way to optimize for \(t_f\) alongside the trajectory, but there very well could be a better approach!
The Curious Case of the Missing Constraint
As a final note, I wanted to mention that there are some additional constraints in some versions of the paper. Notably, this paper includes these constraints in its “Problem 3”:
After thinking about it, I don’t think the constraints are needed. They are enforcing that our mass lies between an upper and lower bound. The upperbound is the mass we would have if we had minimum thrust for the entire trajectory, whereas the lowerbound is the mass we would have if we had maximum thrust for the entire trajectory. The fact that we constrain our thrusts (and constrain our final mass) mean that we don’t really need these constraints.
Conclusion
I find this problem fascinating. We go through a lot of math, so much that it can be overwhelming, but it all works out in the end. Every step ends up being understandable and justifiable. I then love seeing the final trajectories play out, and get the immediate feedback in the trajectory as we adjust the initial conditions and constraints.
My last few blog posts covered methods for getting push-optimal solutions to simple Sokoban puzzles. Traditional Sokoban, however, operates on player moves. Solvers often reason about pushes to simplify decision-making. Unfortunately, push-optimal solutions are not necessarily move-optimal. For example, this solution is push-optimal but has some very clear inefficiencies when we render out the player moves required to travel between boxes:
Push-Optimal (but not move-optimal) solution for a subset of Sokoban 01
Rendering the same push-optimal solution above with its player moves clearly shows how inefficient it is
Directly solving for move-optimal solutions from scratch is difficult. Rather than doing that, it is common to optimize a given solution to try to find another solution with a smaller player move count. Thus, Sokoban solvers typically find push-optimal solutions, or more commonly some valid solution, and Sokoban optimizers work with an existing solution to try and improve it.
There are many approaches for optimizing solutions. In this post, I’ll just cover some very basic approaches to improve my push-optimal solutions from the previous posts.
Solution Evaluation
Every optimization problem needs an objective function. Here, we are trying to find solutions with fewer player moves. As such, our objective function takes in a potential push sequence solution and evaluates both its validity (whether it is, in fact, a solution), and the number of player moves. The number of player moves is the number of box pushes plus the number of moves to walk to the appropriate location for each push.
All of the strategies I use here simply shuffle the pushes around. I do not change the pushes. As we’ll see, this basic assumption works pretty well for the problems at hand.
We thus have a simple constrained optimization problem – to minimize the number of player moves by permuting the pushes in a provided push-optimal solution subject to the constraint that we maintain solution integrity. We can easily evaluate a given push sequence for validity by playing the game through with that push sequence, which we have to do anyway to calculate the number of player moves.
Strategy 1: Consider all Neighboring Box Pairs
The simplest optimization strategy is to try permuting neighboring push pairs. We consider neighboring pairs because they are temporally close, and thus more likely to be a valid switch. Two pushes that are spread out a lot in time are likely to not be switchable – other pushes are more likely to have to happen in-between.
This strategy is extremely simple. Just iterate over all pushes, and if two neighboring pushes are for two different boxes, try swapping the push order and then evaluating the new push sequence to see if it solves the problem with a smaller move count. If it does, keep the new solution.
For example, if our push sequence, in terms of box pushes, is AAABBCCBAD, we would evaluate AABABCCBAD first, and it does not lead to an improvement, consider AAABCBCBAD next, etc.
Strategy 2: Consider all Neighboring Same-Box Sequences
The strategy above is decent for fine-tuning the final solution. However, by itself it is often unable to make big improvements.
Move-optimal solutions are often achieved by grouping pushes for the same box together. This intuitively leads to the player not having to trek to other boxes between pushes – they are already right next to the box they need to push next. We thus can do quite well by considering moving chunks of pushes for the same box around rather than moving around a single box push at a time.
This approach scans through our pushes, and every time we change which box we are pushing, considers moving forward all push sequences of all other next boxes to before the current sequence of box pushes. For example, if our push sequence is AAABBCCBAD, we would consider BBAAACCBAD, CCAAABBBAD, and DAAABBCCBA, greedily keeping the first one that improves our objective.
Strategy 3: Group Same-Box Push Sequences
The third basic strategy that I implemented moves box sub-sequences in addition to full box sequences in an effort to consolidate same-box push sequences. For each push, if the next push is not for the same box, we find the next push sequence for this box and try to move the largest possible sub-sequence for that box to immediately after our current push – i.e., chaining pushes.
For example, if our push sequence is AAABBCCBAD, we would consider AAAABBCCBD, and if that did not lead to an improvement, would consider AAABBBCCAD.
Similarly, if our push sequence is AAABBAAA, we would consider AAAAAABB, then AAAAABBA, and finally AAAABBAA in an effort to find the largest sub-sequence we could consolidate.
Putting it All Together
None of these heuristics are particularly sophisticated or fancy. However, together we get some nice improvements. We can see the improvement on the full Sokoban 01 problem:
Full Push-Optimal Solution for Sokoban 01: 97 box pushes and 636 player moves
After re-ordering the pushes we have 260 only player moves
The following output shows how the algorithm progressed:
So there you have a quick-and-dirty way to get some nicer solutions out of our push-optimal solutions. Other approaches will of course be needed once we have solutions that aren’t push-optimal, which we’ll get once we move onto problems that are too difficult to solve optimally. There we’ll have to do more than just permute the pushes around, but actually try changing our push sequence and refining our solution more generally.
In my previous post, I covered some basic Sokoban search algorithms and some learnings from my digging into YASS (Yet Another Sokoban Solver). I covered the problem representation but glossed over how we determine the pushes available to us in a given board state. In this post, I cover how we calculate that and then conduct into a bunch of little efficiency investigations.
A push-optimal solution to a Sokoban puzzle
Set of Actions
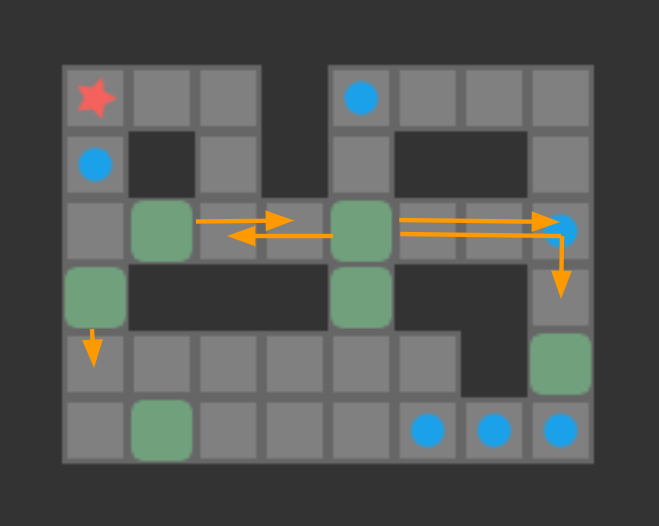
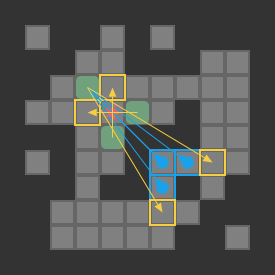
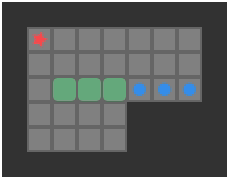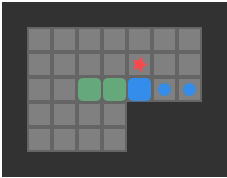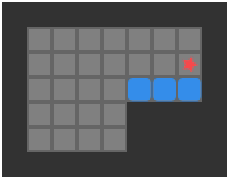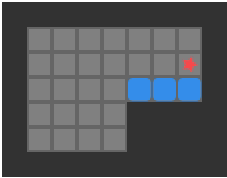
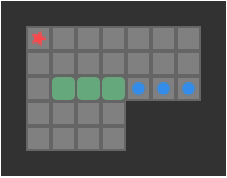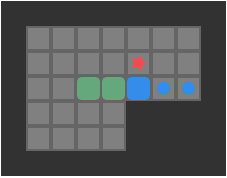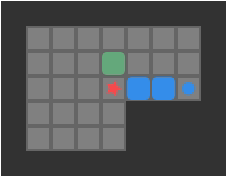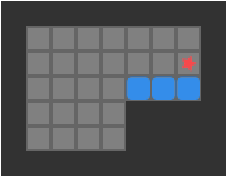
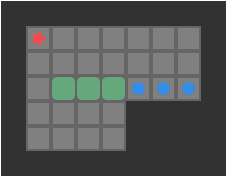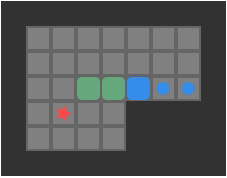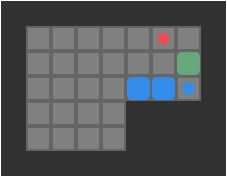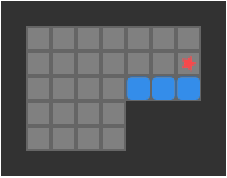
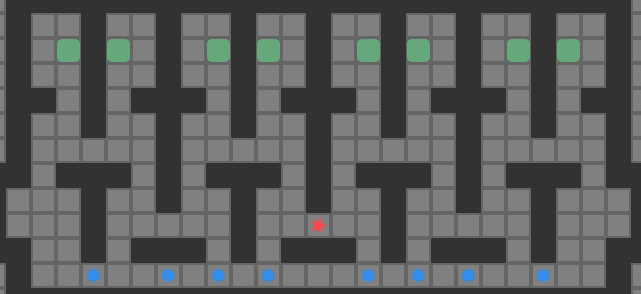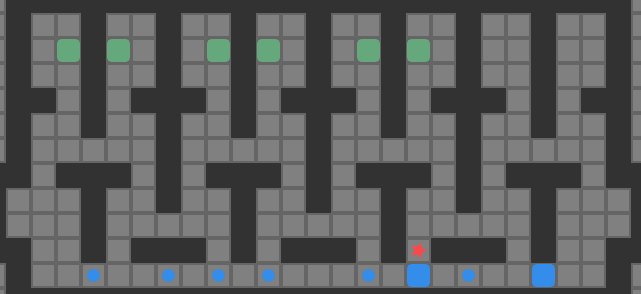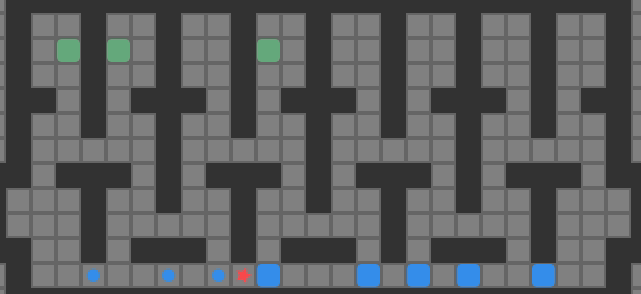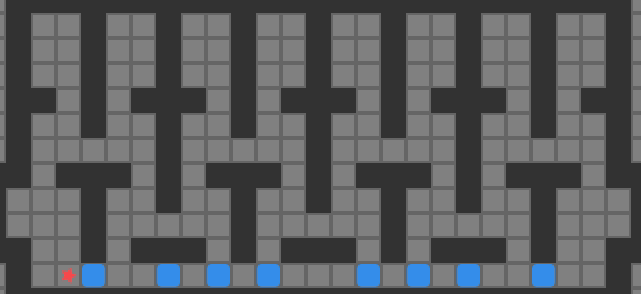
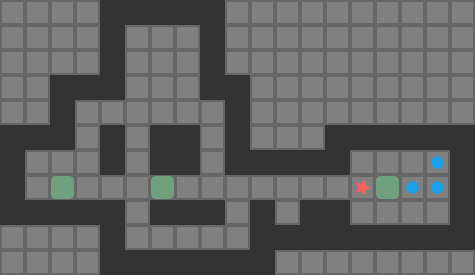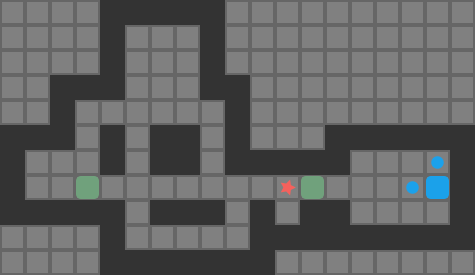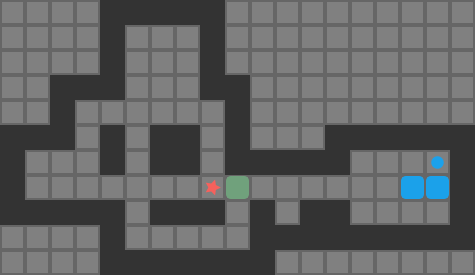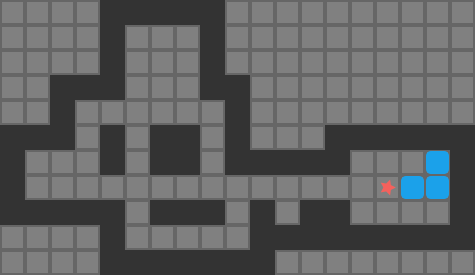
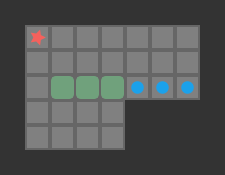
We are trying to find push-optimal solutions to Sokoban problems. That is, we are trying to get every box on a box in the fewest number of pushes possible. As such, the actions available to us each round are the set of pushes that our player can conduct from their present position:
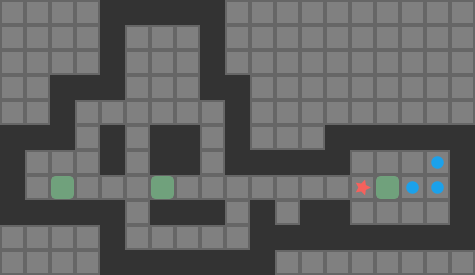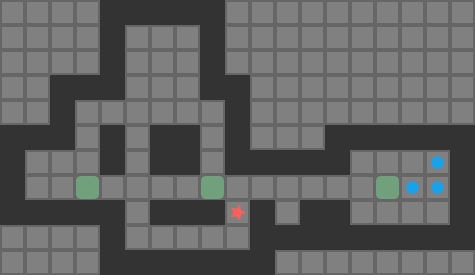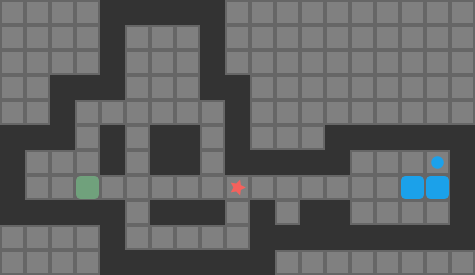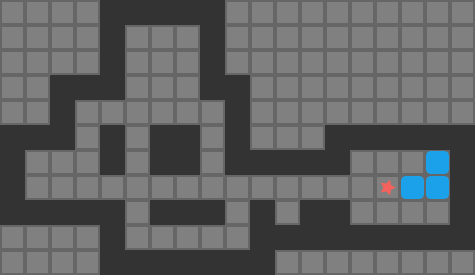
The set of pushes the player (red star) can conduct from their present position
Our Sokoban solver will need to calculate the set of available pushes in every state. As such, we end up calculating the pushes a lot, and the more efficient we are at it, the faster we can conduct our search.
A push is valid if:
our player can reach a tile adjacent to the block from their current position
the tile opposite the player, on the other side of the block, is free
As such, player reachability is crucial to the push calculation.
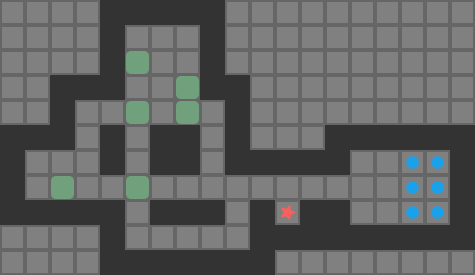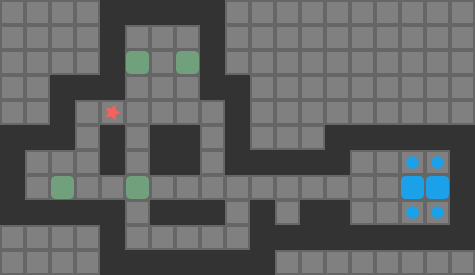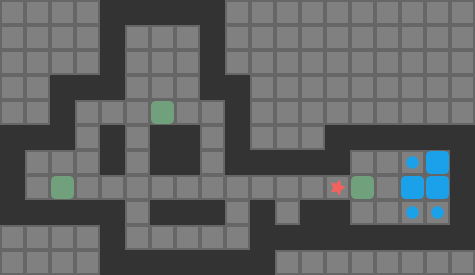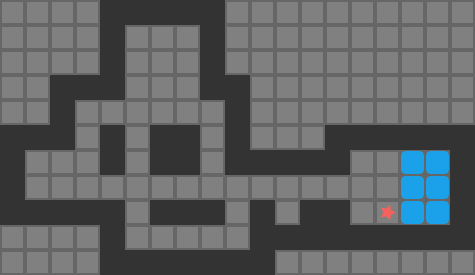
Reachablity for the same game state as the previous image. Red tiles are player-reachable, and green tiles are reachable boxes.
Above we see the tiles reachable from the player’s position (red) and the boxes adjacent to player-reachable tiles. This view is effectively the output of our reachability calculation.
Efficient Reach Calculations
The set of reachable tiles can be found with a simple flood-fill starting from the player’s starting location. We don’t care about the shortest distance, just reachability, so this can be achieved with either a breadth-first or a depth-first traversal:
Naive Reach Calculation
Let’s look at a naive Julia implementation using depth-first traversal:
This code is somewhat inefficient, most notably in that it allocates sets for both reachable_tiles and reachable_boxes, which change in size during its execution. (We also compute the minimum reachable tile, for use in state hashing, as explained in the previous post.) Let’s evaluate its runtime on this large puzzle:
A large test puzzle based on Sasquatch 49. All tiles are initially reachable
Using @btime from BenchmarkTools.jl, we get 15.101 μs (28 allocations: 9.72 KiB). Honestly, 15 microseconds is actually quite good – much better than I expected from a naive implementation. That being said, let’s see if we can do better.
YASS Reach Calculation with Preallocated Memory
I spent a fair amount of time investigating YASS, which was written in Pascal. The Pascal code was structured differently than most of the code bases I’ve worked with. The working memory is declared and allocated at the top of the file in a global space, and is then used throughout. This preallocation makes it incredibly efficient. (As an aside, it was quite difficult to tell where variables were defined, since the naming conventions didn’t make it clear what was declared locally and what was global, and Pascal scoping really threw me into a loop). I feel that a lot of modern programming gets away with assuming we have a lot of memory, and is totally fine with paying the performance cost. However, in tight inner loops like this reach calculation, which might run many hundreds of thousands of times, we care enough about performance to pay special attention.
The Julia performance tips specifically call out paying attention to memory allocations. The previous code allocated 9.72 KiB. Let’s try to knock that down.
We’ll start by defining a struct that holds our preallocated memory. Rather than keeping lists or sets of player-reachable tiles and boxes, we’ll instead store a single flat array of tiles the same length as the board. This representation lets us just flag a given tile as a player-reachable tile or a player-reachable box:
mutable struct ReachableTiles
# The minimum (top-left) reachable tile. Used as a normalized player position
min_reachable_tile::TileIndex
# Incremented by 2 in each reach calculation# The player-reachable tiles have the value 'calc_counter'# Tiles with neighboring boxes have the value 'calc_counter' + 1# Non-floor tiles are set to typemax(UInt32)
calc_counter::UInt32
tiles::Vector{UInt32}end
This data structure lets us store everything we care about, and does not require clearing between calls (only once we get to wraparound). We just increment a counter and overwrite our memory with every call.
The reachability calculation from before can now be modified to update our ReachableTiles struct:
function calc_reachable_tiles!(
reach::ReachableTiles,
game::Game,
board::Board,
□_start::TileIndex,
stack::Vector{TileIndex})::Int# The calc counter wraps around when the upper bound is reachedif reach.calc_counter ≥ typemax(UInt32) - 2
clear!(reach, board)end
reach.calc_counter += 2
reach.min_reachable_tile = □_start
reach.tiles[□_start] = reach.calc_counter
n_reachable_tiles = 1# depth-first search uses a stackstack[1] = □_start
stack_hi = 1# index of most recently pushed item# stack contains items as long as stack_hi > 0while stack_hi >0# pop stack
□ = stack[stack_hi]
stack_hi -= 1# Examine tile neighborsfor dir in DIRECTIONS
▩ = □ + game.step_fore[dir]if reach.tiles[▩]< reach.calc_counter# An unvisited floor tile, possibly with a box# (non-floors are typemax ReachabilityCount)if(board[▩]& BOX) == 0# not a box
n_reachable_tiles += 1# push the square to the stack
stack_hi += 1stack[stack_hi] = ▩
reach.tiles[▩] = reach.calc_counter
reach.min_reachable_tile = min(▩, reach.min_reachable_tile)else# a box
reach.tiles[▩] = reach.calc_counter + 1endendendend
reach.calculated = truereturn n_reachable_tiles
end
This time, @btime gives us 2.490 μs (2 allocations: 224 bytes), which is about 6x faster and a massive reduction in allocations.
I was particularly pleased by the use of the stack memory passed into this method. Our depth-first traversal has to keep track of tiles that need to be expanded. The code uses a simple vector to store the stack, with just a single index variable stack_hi that points to the most recently pushed tile. We know that we will never have more items in the stack than tiles on our board, so stack can simply be the same length as our board. When we push, we increment stack_hi and place our item there. When we pop, we grab our item from stack[stack_hi] and then decrement. I loved the elegance of this when I discovered it. Nothing magic or anything, just satisfyingly clean and simple.
Avoiding Base.iterate
After memory allocations, the other thing common culprit of inefficient Julia code is a variable with an uncertain / wavering type. At the end of the day, everything ends up as assembly code that has to crunch real bytes in the CPU, so any variable that can be multiple things necessarily has to be treated in multiple ways, resulting in less efficient code.
Julia provides a @code_warntype macro that lets one look at a method to see if anything has a changing type. I ran it on the implementation above and was surprised to see an internal variable with a union type, @_9::Union{Nothing, Tuple{UInt8, UInt8}}.
It turns out that for dir in DIRECTIONS is calling Base.iterate, which returns either a tuple of the first item and initial state or nothing if empty. I was naively thinking that because DIRECTIONS was just 0x00:0x03 that this would be handled more efficiently. Anyways, I was able to avoid this call by using a while loop:
dir = DIR_UP
while dir <= DIR_RIGHT
...
dir += 0x01
end
That change drops us down to 1.989 μs (2 allocations: 224 bytes), which is now about 7.5x faster than the original code. Not bad!
Graph-Based Board Representation
Finally, I wanted to try out a different board representation. The code about stores the board, a 2d grid, as a flat array. To move left we decrement our index, to move right we increment our index, and to move up or down we change by our row length.
I looked into changing the board to only store the non-wall tiles and represent it as a graph. That is, have a flat list of floor tiles and for every tile and every direction, store the index of its neighbor in that direction, or zero otherwise:
struct BoardGraph
# List of tile values, one for each node
tiles::Tiles
# Index of the tile neighbor for each tile.# A value of 0 means that edge is invalid.
neighbors::Matrix{TileIndex}# tile index × directionend
This form has the advantage of a smaller memory footprint. By dropping the wall tiles we can use about half the space. Traversal between tiles should be about as expensive as before.
The reach calculation looks more or less identical. As we’d expect, the performance is close to the same too: 2.314 μs (4 allocations: 256 bytes). There is some slight inefficiency, perhaps because memory lookup is not as predictable, but I don’t really know for sure. Evenly structured grid data is a nice thing!
Pushes
Once we’ve done our reachable tiles calculation, we need to use it to compute our pushes. The naive way is to just iterate over our boxes and append to a vector of pushes:
function get_pushes(game::Game, s::State, reach::ReachableTiles)
pushes = Push[]for(box_number, □)in enumerate(s.boxes)if is_reachable_box(□, reach)# Get a move for each direction we can get at it from,# provided that the opposing side is clear.for dir in DIRECTIONS
□_dest = □ + game.step_fore[dir]# Destination tile
□_player = □ - game.step_fore[dir]# Side of the player# If we can reach the player's pos and the destination is clear.if is_reachable(□_player, reach)&&((s.board[□_dest]&(FLOOR+BOX)) == FLOOR)push!(pushes, Push(box_number, dir))endendendendreturn pushes
end
We can of course modify this to use preallocated memory. In this case, we pass in a vector pushes. The most pushes we could have is four times the number of boxes. We allocate that much and have the method return the actual number of boxes:
function get_pushes!(pushes::Vector{Push}, game::Game, s::State, reach::ReachableTiles)::Int
n_pushes = 0for(box_number, □)in enumerate(s.boxes)if is_reachable_box(□, reach)# Get a move for each direction we can get at it from,# provided that the opposing side is clear.for dir in DIRECTIONS
□_dest = □ + game.step_fore[dir]# Destination tile
□_player = □ - game.step_fore[dir]# Side of the player# If we can reach the player's pos and the destination is clear.if is_reachable(□_player, reach)&&((s.board[□_dest]&(FLOOR+BOX)) == FLOOR)
n_pushes += 1
pushes[n_pushes] = Push(box_number, dir)endendendendreturn n_pushes
end
Easy! This lets us write solver code that looks like this:
An alternative is to do something similar to Base.iterate and generate the next push given the previous push:
"""
Given a push, produces the next valid push, with pushes ordered
by box_index and then by direction.
The first valid push can be obtained by passing in a box index of 1 and direction 0x00.
If there no valid next push, a push with box index 0 is returned.
"""function get_next_push!(
game::Game,
s::State,
reach::ReachableTiles,
push::Push = Push(1, 0))
box_index = push.box_index
dir = push.dirwhile box_index ≤ length(s.boxes)
□ = s.boxes[box_index]if is_reachable_box(□, reach)# Get a move for each direction we can get at it from,# provided that the opposing side is clear.while dir < N_DIRS
dir += one(Direction)
□_dest = game.board_start.neighbors[□, dir]
□_player = game.board_start.neighbors[□, OPPOSITE_DIRECTION[dir]]# If we can reach the player's pos and the destination is clear.if □_dest >0&&
□_player >0&&
is_reachable(□_player, reach)&&
not_set(s.tiles[□_dest], BOX)return Push(box_index, dir)endendend# Reset
dir = 0x00
box_index += one(BoxIndex)end# No next pushreturn Push(0, 0)end
We can then use it as follows, without the need to preallocate a list of pushes:
Both this code and the preallocated pushes approach are a little annoying, in a similar what that changing for dir in DIRECTIONS to a while loop is annoying. They uses up more lines than necessary and thus makes the code harder to read. That being said, these approaches are more efficient. Here are solve times using A* with all three methods on Sasquatch 02:
naive: 17.200 μs
Preallocated pushes: 16.480 μs
iterator: 15.049 μs
Conclusion
This post thoroughly covered how to compute the player-reachable tiles and player-reachable boxes for a given Sokoban board. Furthermore, we used this reachability to compute the valid pushes. We need the pushes in every state, so we end up computing both many times during a solver run.
I am surprised to say that my biggest takeaway is actually that premature optimization is the root of all evil. I had started this Sokoban project keen on figuring out how YASS could solve large Sokoban problems as effectively as possible. I spent a lot of time learning about its memory representations and using efficient preallocated memory implementations for the Julia solver.
I would never have guessed that the difference between a naive implementation and an optimized implementation for the reach calculation would merely yield a 7.5x improvement. Furthermore, I would never have thought that the naive implementation for getting the pushes would be basically the same as using a preallocated vector. There are improvements, yes, but it really goes to show that these improvements are really only worth it if you really measure your code and really need that speed boost. The sunk development time and the added code complexity is simply not worth it for a lot of everyday uses.
So far, the search algorithm used has had a far bigger impact on solver performance than memory allocation / code efficiencies. In some ways that makes me happy, as algorithms represent “how we go about something” and the memory allocation / efficiencies are more along the lines of implementation details.
As always, programmers need to use good judgement, and should look at objective data.
Sokoban – the basic block-pushing puzzle – has been on my mind off and on for several years now. Readers of my old blog know that I was working on a block-pushing video game for a short while back in 2012. John Blow, creator of The Witness, later announced that his next new game would draw a lot from Sokoban (In 2017? I don’t remember exactly). Back in 2018, when we were wrapping up Algorithms for Optimization and I started thinking about Algorithms for Decision Making, I had looked up some of the literature on Sokoban and learned about it more earnestly.
Mystic Dave pushing a block
At that time I stumbled upon Solving Sokoban by Timo Virkkala, a great Master’s Thesis that covers the basics of the game and the basics used by many solvers. The thesis serves as a great background for search in general, that is, whenever one wants to find the best sequence of deterministic transitions to some goal state. While search problems are not front and center in Algorithms for Decision Making, I did end up writing an appendix chapter on them, and looking back on it see how well comparatively the thesis covers the space.
I started work at Volley Automation in January of 2021, a startup working on fully automated parking garages. I am responsible for the scheduler, which is the centralized planner that orchestrates all garage operations. While the solo pushing of blocks in Sokoban is not quite the same as simultaneously moving multiple robots under trays and having them lift them up, the problems are fairly related. This renewed my interest in Sokoban, and I spent a fair amount of free time looking into solvers.
Early in my investigation, I downloaded an implementation of YASS (Yet Another Sokoban Solver), a 27538-line Pascal program principally written by Brian Damgaard, which I found via the Sokoban wiki. I had heard that this solver could solve the “XSokoban #50” level in under a second, and had found the wiki overview and the code, so felt it was a good place to dive in. After trying to translate the Pascal code into Julia directly, I both determined that the languages are sufficiently different that this was not really possible (Pascal, for example, has a construct similar to a C union, which Julia does not have), and that it also ultimately wasn’t what I wanted to get out of the exercise. I did learn a lot about Pascal and about efficient Sokoban solving from the code base, and ended up translating the overall gist of many algorithms in order to learn how Goal room packing works.
Before I fleshed out YASS’s goal room packing algorithm, I needed a good baseline and a way to verify that my Sokoban game code was correct. As such, I naturally started by writing some of the very basic search algorithms from my search appendix chapter. This post will cover these search algorithms and concretely show how they progressively improve on each other Sokoban problems of increasing complexity. It was really stark to see how the additions in each new algorithm causes order-of-magnitude changes in solver capability. As always, code is here.
Sokoban Basics
Sokoban is a search problem where a player is on a grid and needs to push some number of boxes to an equal number of goal tiles. The player can move north, south, east, or west, provided that they do not run into a wall or box tile. A player may push a box by moving into its space, provided that the box can move into the next space over. A simple 2-box Sokoban game and solution are shown below:
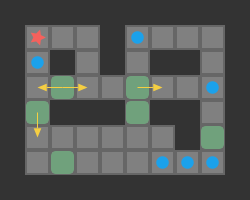
The red star indicates the player position, boxes are green when not on goals, and blue when on goals. The dark tiles are walls.
While the action space is technically the set of legal north/south/east/west player moves, it is more efficient to reason about push moves instead. That is, search algorithms will consider the pushes available from the player’s current position. This simplification yields massive speedups without losing much in terms of practicality. If a push is chosen, we can back out the minimum number of player moves to achieve the push by simply using a shortest-path solver.
Player move vs. box push problem formulations. Reasoning with a coarser representation has big performance implications.
A push-optimal solution may not be player move optimal – for example it may alternate between pushing two different boxes that the player has to traverse between – but it is nevertheless well worth reasoning about push moves. Here is the push-move solution for the same simple 2-box problem:
Sokoban is made tricky by the fact that there are deadlocks. We cannot push a box that ends up in a corner, for example. It is not always obvious when one has reached a state from which deadlock is inevitable. A big concern in most Sokoban solvers is figuring out how to efficiently disregard such parts of the search tree.
Problem Representation
A search problem is defined by a state space, an action space, a transition function, and a reward function. Sokoban falls into the category of shortest path problems, which are search problems that simply penalize each step and yield zero reward once a destination state is reached. As such, we are searching for the smallest number of steps to reach a goal state.
The board here has both static and dynamic elements. The presents of walls or goals, for example, does not change as the player moves. This unchanging information, including some precomputed values, are stored in a Game struct:
struct Game
board_height::Int32
board_width::Int32
board::Board # The original board used for solving, # (which has some precomputation / modification in the tile bit fields)# Is of length (Width+2)*(Height+2); the extra 2 is for a wall-filled border
start_player_tile::TileIndex
goals::Vector{TileIndex}# The goal tiles do not change# □ + step_fore[dir] gives the tile one step in the given direction from □
step_fore::SVector{N_DIRS, TileIndex}# □ + step_left[dir] is the same as □ + step_fore[rot_left(dir)]
step_left::SVector{N_DIRS, TileIndex}# □ + step_right[dir] is the same as □ + step_fore[rot_right(dir)]
step_right::SVector{N_DIRS, TileIndex}end
where TileIndex is just an Int32 index into a flat Board array of tiles. That is,
const TileIndex = Int32# The index of a tile on the board - i.e. a position on the boardconst TileValue = UInt32 # The contents of a board squareconst Board = Vector{TileValue}# Of length (Width+2)*(Height+2)
The 2D board is thus represented as a 1D array of tiles. Each tile is a bit field whose flags can be set to indicate various properties. The basic ones, as you’d expect, are:
I represented the dynamic state, what we affect as we take our actions, as follows:
mutable struct State
player::TileIndex
boxes::Vector{TileIndex}
board::Board
end
You’ll notice that our dynamic state thus contains all wall and goal locations. This might seem wasteful but ends up being quite useful.
An action is a push:
struct Push
box_number::BoxNumber
dir::Direction
end
where BoxNumber refers to a unique index for every box assigned at the start. We can use this index to access a specific box in a state’s boxes field.
Taking an action is as simple as:
function move!(s::State, game::Game, a::Push)
□ = s.boxes[a.box_number]# where box starts
▩ = □ + game.step_fore[a.dir]# where box ends up
s.board[s.player]&= ~PLAYER # Clear the player
s.board[□]&= ~BOX # Clear the box
s.player = □ # Player ends up where the box is.
s.boxes[a.box_number] = ▩
s.board[s.player]|= PLAYER # Add the player
s.board[▩]|= BOX # Add the boxreturn s
end
Yeah, Julia supports unicode 🙂
Note that this method updates the state rather than producing a new state. It would certainly be possible to make it functional, but then we wouldn’t want to carry around our full board representation. YASS didn’t do this, and I didn’t want to either. That being said, in order to remain efficient we need a way to undo an action. This will let us efficiently backtrack when navigating up and down a search tree.
function unmove!(s::State, game::Game, a::Push)
□ = s.boxes[a.box_number]# where box starts
▩ = □ - game.step_fore[a.dir]# where box ends up
s.board[s.player]&= ~PLAYER # Clear the player
s.board[□]&= ~BOX # Clear the box
s.player = ▩ - game.step_fore[a.dir]# Player ends up behind the box.
s.boxes[a.box_number] = ▩
s.board[s.player]|= PLAYER # Add the player
s.board[▩]|= BOX # Add the boxreturn s
end
Finally, we need a way to know when we have reached a goal state. This is when every box is on a goal:
function is_solved(game::Game, s::State)for □ in s.boxesif(game.board[□]& GOAL) == 0returnfalseendendreturntrueend
The hardest part is computing the set of legal pushes. It isn’t all that hard, but involves a search from the current player position, and I will leave that for a future blog post. Just note that I use a reach struct for that, which will show up in subsequent code blocks.
Depth First Search
I started with depth first search, which is a very basic search algorithm that simply tries all combinations of moves up to a certain depth:
Depth-first traversal of the search tree. Note that we can visit the same state multiple times
In the book we call this algorithm forward search. The algorithm is fairly straightforward:
struct DepthFirstSearch
d_max::Intstack::Vector{TileIndex}# Memory used for reachability calcsend
mutable struct DepthFirstSearchData
solved::Bool
pushes::Vector{Push}# of length d_max
sol_depth::Int# number of pushes in the solutionendfunction solve_helper(
dfs::DepthFirstSearch,
data::DepthFirstSearchData,
game::Game,
s::State,
reach::ReachableTiles,
d::Int)if is_solved(game, s)
data.solved = true
data.sol_depth = d
returntrueendif d ≥ dfs.d_max# We exceeded our max depthreturnfalseend
calc_reachable_tiles!(reach, game, s.board, s.player, dfs.stack)forpushin get_pushes(game, s, reach)
move!(s, game, push)if solve_helper(dfs, data, game, s, reach, d+1)
data.pushes[d+1] = pushreturntrueend
unmove!(s, game, push)end# Failed to find a solutionreturnfalseendfunction solve(dfs::DepthFirstSearch, game::Game, s::State, reach::ReachableTiles)
t_start = time()
data = DepthFirstSearchData(false, Array{Push}(undef, dfs.d_max), 0)
solve_helper(dfs, data, game, s, reach, 0)return data
end
You’ll notice that I broke the implementation apart into a DepthFirstSearch struct, which contains the solver parameters and memory used while solving, a DepthFirstSearchData struct, which contains the data used while running the search and is returned with the solution, and a recursive solve_helper method that conducts the search. I use this approach for all subsequent methods. (Note that I am simplifying the code a bit too – my original code tracks some additional statistics in DepthFirstSearchData, such as the number of pushes evaluated.)
Depth first search is able to solve the simple problem shown above, and does so fairly quickly:
While this is good, the 2-box problem is well, rather easy. It struggles with a slightly harder problem:
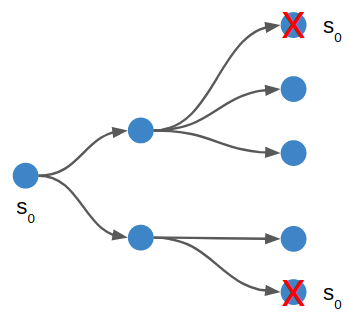
Furthermore, depth first search does not necessarily return a solution with a minimum number of steps. It is perfectly happy to return as soon as a solution is found.
Notice that I do not cover breadth-first search. Unlike depth-first search, breadth-first search is guaranteed to find the shortest path. Why don’t we use that? Doesn’t breadth-first search have the same space complexity as depth-first search, since it is the same algorithm but with a queue instead of a stack?
I am glad you asked. It turns out that DFS and BFS do indeed have the same complexity, assuming that we store the full state in both the stack and the queue. You will notice that this implementation of DFS does not store the full state. Instead, we apply a small state delta (via move!) to advance our state, and then undo the move when we backtrack (via unmove!). This approach is more efficient, especially if the deltas are small and the overall state is large.
Iterative Deepening Depth First Search
We can address the optimality issue by using iterative deepening. This is simply the act of running depth first search multiple times, each time increasing its maximum depth. We know that depth first search will find a solution if d_max is sufficiently large, and so the first run that finds a solution is guaranteed to be a minimum-push solution.
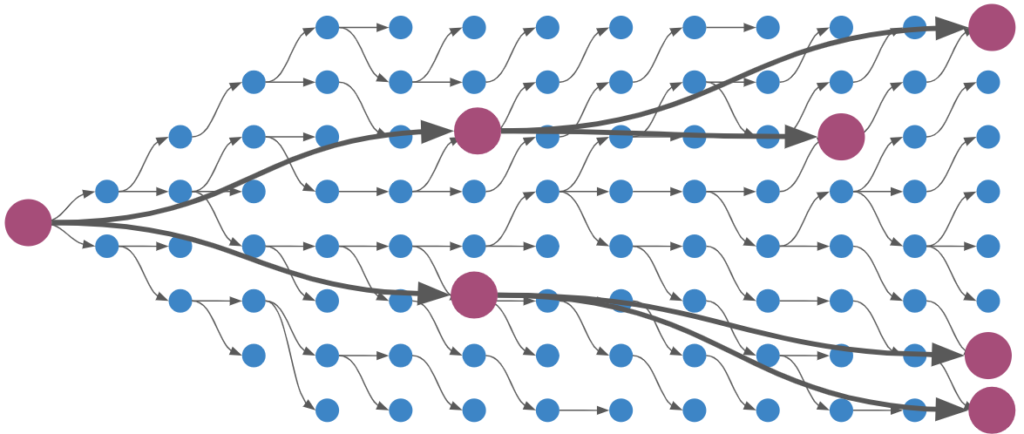
Depth-first search will return the first solution it finds. Here we show a solution (violet) at a deeper depth, when a shorter solution may still exist in an unexplored branch.
Notice that we evaluated more pushes by doing so, because we exhaustively search all 1-step search trees, all 2-step search trees, all 3-step search trees, …., all 7-step search trees before starting the 8-step search that found a solution. Now, the size of the search tree grows exponentially in depth, so this isn’t a huge cost hit, but nevertheless that explains the larger number for n_pushes_evaled.
Unfortunately, iterative deepening depth first search also chokes on the 3-box problem.
Zobrist Depth First Search
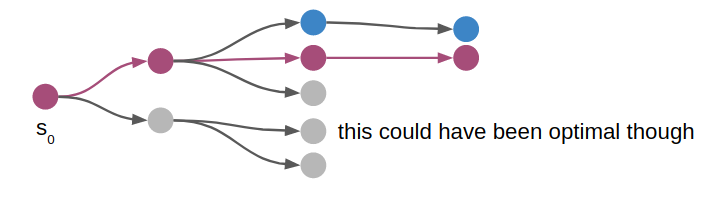
In order to tackle the 3-box problem, we need to avoid exhaustive searches. That is, depth first search will happily push a box left and then re-visit the previous state by pushing the box right again. We can save a lot of effort by not revising board states during a search.
We can save a lot of computational effort by not re-visiting states
The basic idea here is to use a transposition table to remember which states we have visited. We could simply store every state in that table, and only consider new states in the search if they aren’t already in our table.
Now, recall that our State struct is potentially rather large, and we are mutating it rather than producing a new one with every push. Storing all of those states in a table could quickly become prohibitively expensive. (Debatable, but this is certainly true for very large Sokoban problems).
One alternative to storing the full state is to store a hash value instead. The hash value, commonly a UInt64, takes up far less space. If a candidate state’s hash value is already in our transposition table, then we can be fairly confident that we have already visited it. (We cannot be perfectly confident, of course, because it is possible to get a hash collision, but we can be fairly confident nonetheless. If we’re very worried, we can increase the size of our hash to 128 bits or something).
So to implement depth first search with a transposition table, we need a hash function. I learned a neat method from the YASS entry on the Sokoban wiki about how they do exactly this. First, we observe that the dynamic state that needs to be hashed is the player position and the box positions. Next, we observe that we don’t really care about the player position per-se, but rather which reachable region of the board the player is in. Consider the following game:
The player’s reachable space is:
As far as we are concerned, all of the highlighted tiles have the same legal pushes, so all states are equivalent when conducting a search.
We have to compute the player-reachable tiles anyhow when determining which pushes are legal. As such, we can “normalize” the player position in any state by just using the reachable tile with minimum index in board. If the box positions and this minimum player-reachable tile index match for two states, then we can consider them equivalent.
Finally, we need a way to hash the box positions. This is where Zobrist hashing comes in. This is a hashing technique that is commonly used in games like Sokoban and Chess because we can keep track of the hash by updating it with each move (and un-move), rather than having to recompute it every time from scratch. It works by associating a random unique UInt64 for every tile on the board, and we xor together all of the hash components that correspond to tiles with boxes on them:
function calculate_zobrist_hash(boxes::Vector{TileIndex}, hash_components::Vector{UInt64})::UInt64
result = zero(UInt64)for □ in boxes
result ⊻= hash_components[□]endreturn result
end
We can modify Game to store our Zobrist hash components.
The biggest win is that xor’s inverse is another xor. As such, we can modify State to include our current Zobrist hash, and we can modify move and unmove to simply apply and undo the xor:
function move!(s::State, game::Game, a::Push)
□ = s.boxes[a.box_number]
▩ = □ + game.step_fore[a.dir]
s.board[s.player]&= ~PLAYER
s.board[□]&= ~BOX
s.zhash ⊻= game.hash_components[□]# Undo the box's hash component
s.player = □
s.boxes[a.box_number] = ▩
s.board[s.player]|= PLAYER
s.board[▩]|= BOX
s.zhash ⊻= game.hash_components[▩]# Add the box's hash componentreturn s
end
Easy! Our algorithm is thus:
struct ZobristDFS
d_max::Intstack::Vector{TileIndex}# (player normalized pos, box zhash) → d_min
transposition_table::Dict{Tuple{TileIndex, UInt64},Int}end
mutable struct ZobristDFSData
solved::Bool
pushes::Vector{Push}# of length d_max
sol_depth::Int# number of pushes in the solutionendfunction solve_helper(
dfs::ZobristDFS,
data::ZobristDFSData,
game::Game,
s::State,
reach::ReachableTiles,
d::Int)if is_solved(game, s)
data.solved = true
data.sol_depth = d
returntrueendif d ≥ dfs.d_max# We exceeded our max depthreturnfalseend
calc_reachable_tiles!(reach, game, s.board, s.player, dfs.stack)# Set the position to the normalized location
s.player = reach.min_reachable_tile# Exit early if we have seen this state before at this shallow of a depth
ztup = (s.player, s.zhash)
d_seen = get(dfs.transposition_table, ztup, typemax(Int))if d_seen ≤ d
# Skip!
data.n_pushes_skipped += 1returnfalseend# Store this state hash in our transposition table
dfs.transposition_table[ztup] = d
forpushin get_pushes(game, s, reach)
data.n_pushes_evaled += 1
move!(s, game, push)if solve_helper(dfs, data, game, s, reach, d+1)
data.pushes[d+1] = pushreturntrueend
unmove!(s, game, push)end# Failed to find a solutionreturnfalseendfunction solve(dfs::ZobristDFS, game::Game, s::State, reach::ReachableTiles)
empty!(dfs.transposition_table)# Ensure we always start with an empty transposition table
data = ZobristDFSData(false, Array{Push}(undef, dfs.d_max), 0)
solve_helper(dfs, data, game, s, reach, 0)return data
end
This algorithm performs better on the 2-box problem:
Note how it evaluated 235522 pushes and did not find an optimal solution. We can combine the Zobrist hashing approach with iterative deepening to get an optimal solution:
A push-optimal solution for the 3-box problem. Notice that this is not player-move optimal.
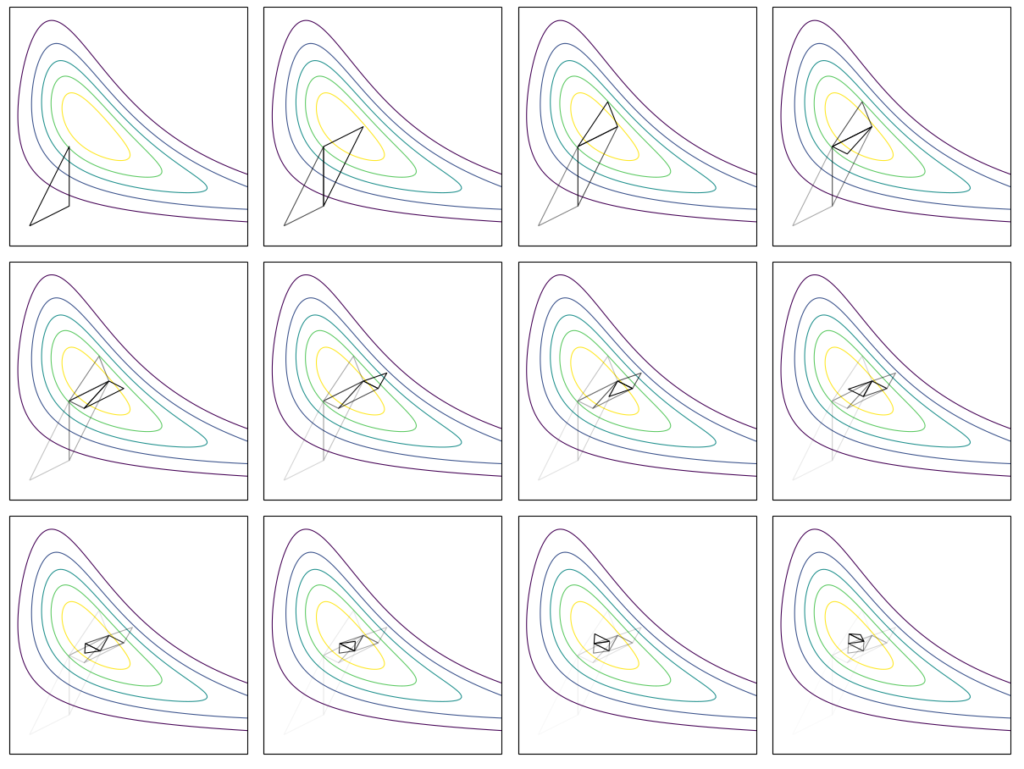
A* (Best First Search)
For our next improvement, we are going to try to guide our search in the right direction. The previous methods are happy to try all possible ways to push a box, without any intelligence having it tend to push boxes toward a goal, for instance. We can often save a lot of computation by trying things that naively get us closer to our goal.
Where depth-first search expands our frontier in a depth-first order, A* (or best-first search), will expand our frontier in a best-first order. Doesn’t that sound good?
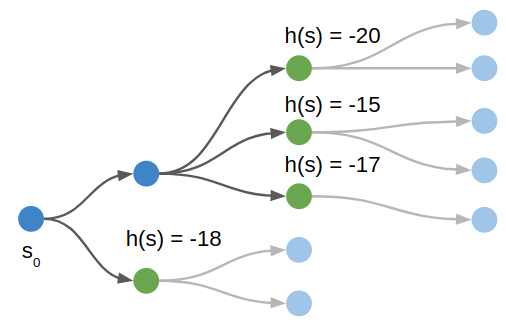
A* can expand any node in the frontier, and selects the node that it predicts has the best chance of efficiently reaching the goal
A*, pronounced “A Star”, is a best first search algorithm. It orders its actions according to how good the pushes are, where “goodness” is evaluated by a heuristic function. We are trying to minimize the number of pushes, and as long as this heuristic function gives as a lower bound on the true minimum number of pushes, A* will eventually find an optimal solution.
A* uses a heuristic function (plus the cost to reach a node) to evaluate each node in the frontier. It expands the node with the highest predicted reward (i.e., lowest cost).
As with Zobrist depth first search, A* also uses state hashes to know which states have been visited. Unlike Zobrist depth first search, A* maintains a priority queue over which state to try next. This presents a problem, because we don’t store states, but rather apply pushes in order to get from one state to another. Once again, YASS provided a nifty way to do something, this time to efficiently switch from states in one part of the search tree to another.
We will store a search tree for our visited states, but instead of each node storing the full state, we will instead store the push leading to the position. We can get from one state to another by traversing backwards to the states’ common ancestor and then traversing forwards to the destination state. I find the setup to be rather clever:
const PositionIndex = UInt32
mutable struct Position
pred::PositionIndex # predecessor index in positions arraypush::Push # the push leading to this position
push_depth::Int32# search depth
lowerbound::Int32# heuristic cost-to-go
on_path::Bool# whether this move is on the active search pathend
function set_position!(
s::State,
game::Game,
positions::Vector{Position},
dest_pos_index::PositionIndex,
curr_pos_index::PositionIndex,
)# Backtrack from the destination state until we find a common ancestor,# as indicated by `on_path`. We reverse the `pred` pointers as we go# so we can find our way back.
pos_index = dest_pos_index
next_pos_index = zero(PositionIndex)while(pos_index != 0)&&(!positions[pos_index].on_path)
temp = positions[pos_index].pred
positions[pos_index].pred = next_pos_index
next_pos_index = pos_index
pos_index = temp
end# Backtrack from the source state until we reach the common ancestor.while(curr_pos_index != pos_index)&&(curr_pos_index != 0)
positions[curr_pos_index].on_path = false
unmove!(s, game, positions[curr_pos_index].push)
curr_pos_index = positions[curr_pos_index].predend# Traverse up the tree to the destination state, reversing the pointers again.while next_pos_index != 0
move!(s, game, positions[next_pos_index].push)
positions[next_pos_index].on_path = true
temp = positions[next_pos_index].pred
positions[next_pos_index].pred = curr_pos_index
curr_pos_index = next_pos_index
next_pos_index = temp
endreturn s
end
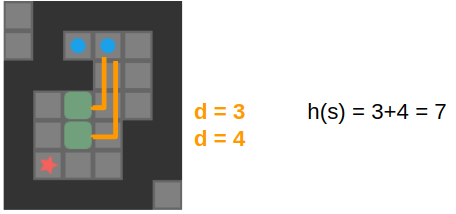
Our heuristic lower bound can take on many forms. One of the simplest is the sum of the distance of each box to the nearest goal, ignoring walls. This is definitely a lower bound, as we cannot possibly hope to require fewer pushes than that. Better lower bounds certainly exist – for example this lower bound does not take into account that each box must go to a different goal.
The lower bound we use is only slightly more fancy – we precompute the minimum number of pushes for each tile to the nearest goal ignoring other boxes, but not ignoring the walls. This allows us to recognize basic deadlock states where a box cannot possibly be moved to a goal, and it gives us a better lower bound when walls separate us from our goals.
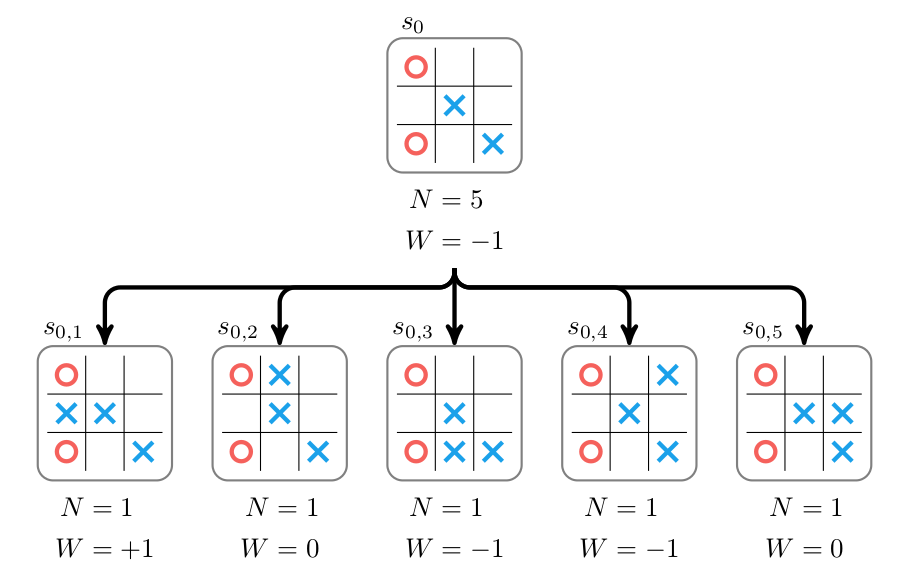
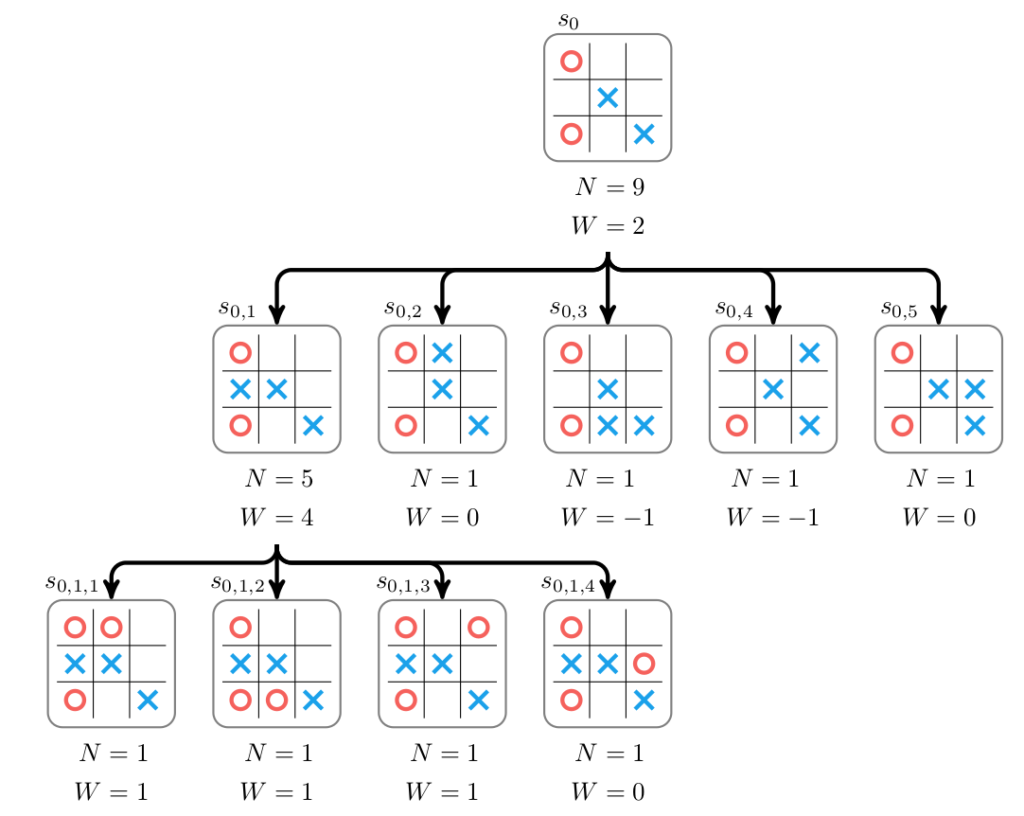
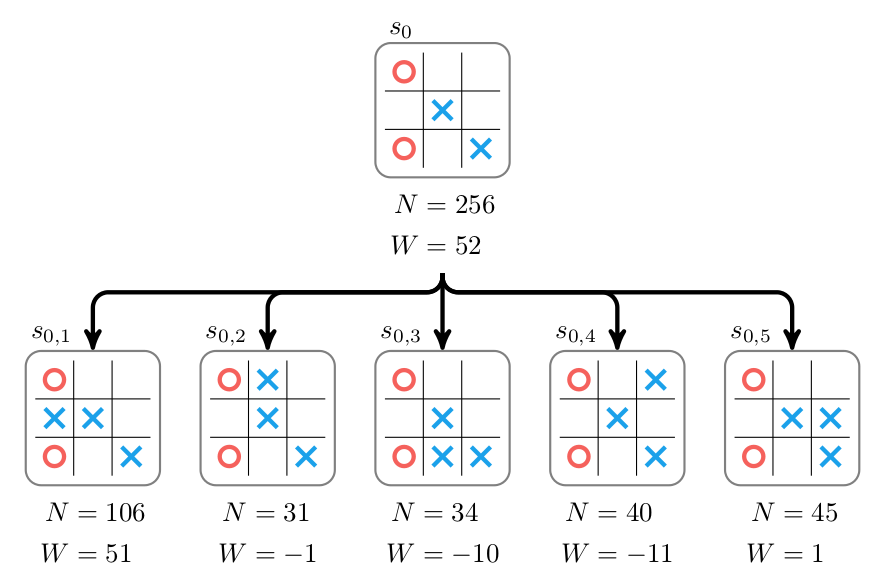
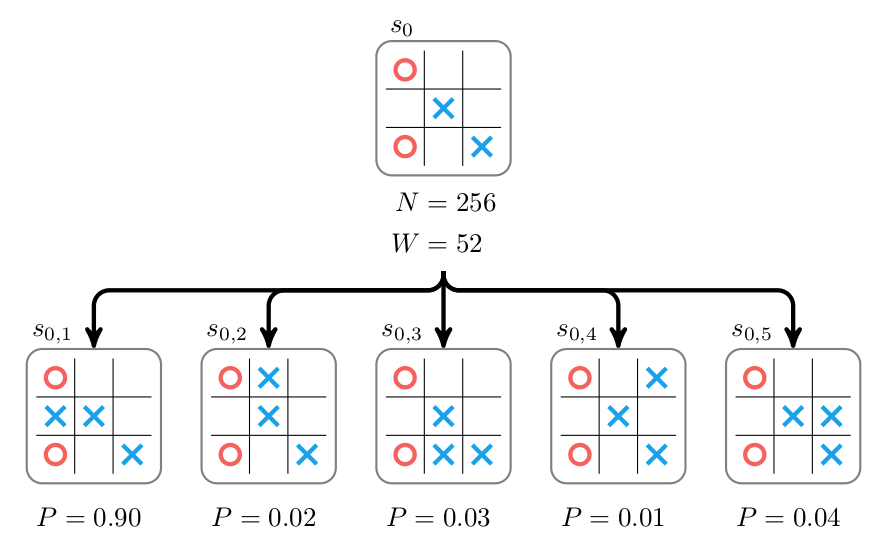
Our cost lowerbound is the sum of the push distance of each box to the closest goal
The A* implementation is a little more involved than the previous algorithms, but its not too bad:
struct AStar
d_max::Int
n_positions::Intend
mutable struct AStarData
solved::Bool
max_depth::Int# max depth reached during search
pushes::Vector{Push}# of length d_max
sol_depth::Int# number of pushes in the solutionendfunction solve(solver::AStar, game::Game, s::State)
d_max, n_positions = solver.d_max, solver.n_positions# Allocate memory and recalculate some things
data = AStarData(false, Array{Push}(undef, d_max), 0)
reach = ReachableTiles(length(game.board))
clear!(reach, game.board)stack = Array{TileIndex}(undef, length(game.board))
pushes = Array{Push}(undef, 4*length(s.boxes))
queue_big = Array{Tuple{TileIndex, TileIndex, Int32}}(undef, length(s.board)* N_DIRS)
distances_by_direction = Array{Int32}(undef, length(s.board), N_DIRS)
dist_to_nearest_goal = zeros(Int32, length(s.board))
calc_push_dist_to_nearest_goal_for_all_squares!(dist_to_nearest_goal, game, s, reach, stack, queue_big, distances_by_direction)# Calculate reachability and set player min pos
calc_reachable_tiles!(reach, game, s.board, s.player, stack)
move_player!(s, reach.min_reachable_tile)# Compute the lower bound
simple_lower_bound = calculate_simple_lower_bound(s, dist_to_nearest_goal)# Allocate a bunch of positions
positions = Array{Position}(undef, n_positions)for i in1:length(positions)
positions[i] = Position(
zero(PositionIndex),
Push(0,0),
zero(Int32),
zero(Int32),
false)end# Index of the first free position# NOTE: For now we don't re-use positions
free_index = one(PositionIndex)# A priority queue used to order the states that we want to process,# in order by total cost (push_depth + lowerbound cost-to-go)
to_process = PriorityQueue{PositionIndex, Int32}()# A dictionary that maps (player pos, zhash) to position index,# representing the set of processed states
closed_set = Dict{Tuple{TileIndex, UInt64}, PositionIndex}()# Store an infeasible state in the first index# We point to this position any time we get an infeasible state
infeasible_state_index = free_index
positions[infeasible_state_index].lowerbound = typemax(Int32)
positions[infeasible_state_index].push_depth = zero(Int32)
free_index += one(PositionIndex)# Enqueue the root state
current_pos_index = zero(PositionIndex)
enqueue!(to_process, current_pos_index, simple_lower_bound)
closed_set[(s.player, s.zhash)] = current_pos_index
done = falsewhile!done&&!isempty(to_process)
pos_index = dequeue!(to_process)
set_position!(s, game, positions, pos_index, current_pos_index, data)
current_pos_index = pos_index
push_depth = pos_index >0? positions[pos_index].push_depth : zero(Int32)
calc_reachable_tiles!(reach, game, s.board, s.player, stack)# Iterate over pushes
n_pushes = get_pushes!(pushes, game, s, reach)for push_index in1:n_pushes
push = pushes[push_index]
move!(s, game, push)
calc_reachable_tiles!(reach, game, s.board, s.player, stack)
move_player!(s, reach.min_reachable_tile)# If we have not seen this state before so early, and it isn't an infeasible state
new_pos_index = get(closed_set, (s.player, s.zhash), zero(PositionIndex))if new_pos_index == 0|| push_depth+1< positions[new_pos_index].push_depth
lowerbound = calculate_simple_lower_bound(s, dist_to_nearest_goal)# Check to see if we are doneif lowerbound == 0# We are done!done = true# Back out the solution
data.solved = true
data.sol_depth = push_depth + 1
data.pushes[data.sol_depth] = push
pred = pos_index
while pred >0
pos = positions[pred]
data.pushes[pos.push_depth] = pos.push
pred = pos.predendbreakend# Enqueue and add to closed set if the lower bound indicates feasibilityif lowerbound != typemax(Int32)# Add the position
pos′ = positions[free_index]
pos′.pred = pos_index
pos′.push = push
pos′.push_depth = push_depth + 1
pos′.lowerbound = lowerbound
to_process[free_index] = pos′.push_depth + pos′.lowerbound
closed_set[(s.player, s.zhash)] = free_index
free_index += one(PositionIndex)else# Store infeasible state with a typemax index
data.n_infeasible_states += 1
closed_set[(s.player, s.zhash)] = infeasible_state_index
endelse
data.n_pushes_skipped += 1end
unmove!(s, game, push)endendreturn data
end
Notice that unlike the other algorithms, this one allocates a large set of positions for its search tree. If we use more positions than we’ve allocated, the algorithm fails. This added memory complexity is typically worth it though, as we’ll see.
It found an optimal solution by only evaluating 1,660 pushes, where iterative deepening Zobrist DFS evaluated 174,333. That is a massive win!
A* is able to solve the following 4-box puzzle to depth 38 by only evaluating 5,218 pushes, where iterative deepening Zobrist DFS evaluates 1,324,615:
A push-optimal solution for “Chaos”, a level by YASGen and Brian Damgaard
It turns out that A* can handle a few trickier puzzles:
Sasquatch 01
Sasquatch 02
However, it too fails as things get harder.
Conclusion
There you have it – four basic algorithms that progressively expand our capabilities at automatically solving Sokoban problems. Depth first search conducts a very basic exhaustive search to a maximum depth, iterative deepening allows us to find optimal solutions by progressively increasing our maximum depth, Zobrist hashing allows for an efficient means of managing a transposition table for Sokoban games, and A* with search tree traversal lets us expand the most promising moves.
The YASS codebase had plenty of more gems in it. For example, the author recognized that the lower bound + push depth we use in A* can only increase. As such, if we move a box toward a goal, our overall estimated cost stays the same. But, every state we move from is by definition a minimum-cost state, so the new state is also then minimum cost as well. We can thus save some computation by just continuing to expand from that new state. See, for example, the discussion in “Combining depth-first search with the open-list in A*“.
I’d like to cover the reachability calculation code in a future blog post. I thought it was a really good example of simple and efficient code design, and how the data structures we use influence how other code around it ends up being architected.
Thanks for reading!
Special thanks to Oscar Lindberg for corrective feedback on this post.
I recently became interested in the Thousand Brain Theory of Intelligence, a theory proposed by Jeff Hawkins and the Numenta team about how the human brain works. In short, the theory postulates that the human neocortex is made up of on the order of a million cortical columns, each of which is a sort of neural network with an identical architecture. These cortical columns learn to represent objects / concepts and track their respective locations and scales by taking in representations of transforms and producing representations of transforms that other cortical columns can use.
This post is not about the Thousand Brain Theory, but instead about the sub-architectures used by Numenta to model the cortical columns. Numenta was founded back in 2005, so a fair bit of time has passed since the theory was first introduced. I read through some of their papers while trying to learn about the theory, and ended up going back to “Why Neurons have Thousands of Synapses, a Theory of Sequence Memory in the Neocortex” by Hawkins et al. from 2016 before I found a comprehensive overview of the so-called hierarchical temporal memory units that are used in part to model the cortical columns.
In a nutshell, the hierarchical temporary memory units provide a means of having a local method for learning and allows individual neurons to become very good at recognizing a wide variety of patterns. Hierarchical temporal memory is supposedly good at robust sequence recognition and better models how real neurons work.
Real Neurons
The image above shows my crude drawing of a pyramidal cell, a type of cell found in the prefrontal cortex. The Thousand Brains Theory needs a way to model these cells. The thick blob in the center is the cell soma, or main body of the cell. The rest are connective structures that allow the neuron to link with other neurons. The dendrites (blue) are the cell’s inputs, and receive signals from other cells and thereby trigger the cell to fire or prepare to fire. The axons (green) are the cell’s outputs, and propagate the charge produced by a firing cell to the dendrites of other neurons. Dendrites and axons connect to one another via synapses (shown below). One neuron may have several thousand synapses.
Real neurons are thus tremendously more complicated than is typically modeled in a traditional deep neural network. Each neuron has many dendrites, and each dendrite has many potential synaptic connections. A real neuron “learns” by developing synaptic connections. “Good” connections can be reinforced and made stronger, whereas “bad” connections can be diminished and eventually pruned altogether.
Each dendrite is its own little pattern matcher, and can respond to different input stimuli. Furthermore, different dendrites are responsible for different behavior. Proximal dendrites carry input information from outside of the layer of cells, and if they trigger, they cause the entire neuron to fire. Basal dendrites are connected to other cells in the same layer, and if they trigger, they predispose it to firing, causing it to fire faster than it normally would, thus preventing other neurons in the same region from also firing. (Apical dendrites are not modeled this this paper, but are thought to be like basal dendrites but carry feedback information from higher layers back down.)
Neurons in Traditional Deep Learning
It is interesting to see how much simpler a neuron is in traditional deep learning. There, a single neuron merely consists of an activation function, such as ReLU or sigmoid, and acts on a linear combination of inputs:
A neuron in a traditional deep neural network
Mathematically, given a real input vector \(x\), the neuron produces a real output \(\texttt{relu}(x^\top w)\). Representing a neuron in memory only requires storing the weights.
This representation is rather simplified, and abstracts away much of the structure of the neuron into a nice little mathematical expression. While the traditional neural network / deep learning representation is nice and compact (and differentiable), the hierarchical temporal model introduced by Hawkins et al. models these pyramidal neurons with much greater fidelity.
In particular, the HTM paper claims that real neurons are far more sophisticated, capable of learning to recognize a multitude of different patterns. The paper seeks a model for sequence learning that produces neural models that excel at online learning, high-order prediction, multiple simultaneous predictions, continual learning, all while being robust to noise and not require much tuning. That’s quite a tall order!
Neurons in the HTM Model
HTM neurons are more complicated. In this model, each cell has \(1\) proximal dendrite that provides input from outside of the cell’s layer, and \(B\) basal dendrites that provide contextual information from other neurons in the same layer. Each dendrite has some number of synapses that connect it to the axons of other neurons. The figure above shows 22 synapses on each dendrite, will filled circles showing whether the connected axon is firing or not.
In the HTM model, a dendrite activates when a sufficient number of its synapses are active. That is, if at least \(\theta\) connected neurons that it has synaptic connections with fire. If we represent the a dendrite’s input as a bit-vector \(\vec d\), then the dendrite activates if \(\|\vec d\|_1 \geq \theta \).
An HTM cell can be in three states. It is normally inactive. If its proximal dendrite activates, then the cell becomes active and fires, producing an output on its axon. If a basal dendrite activates, then the cell becomes predictive, and if it becomes active in the next time-step, it will fire faster than its neighbors and prevent them from firing. We reward basal dendrites that cause the cell to become predictive before activation, and we punish dendrites that don’t. In this way, learning (for basal dendrites at least) is entirely local.
A dendrite can “learn” by changing its synaptic connections. In a real cell, a synapse can be reinforced by growing thicker / closer to its axon. A more established synapse is more permanent and harder to remove. In the HTM model, we maintain a set of \(K\) potential synapses per neuron. Each potential synapse has a scalar “permanence” value \(0 \leq p \leq 1\) that represents its state of growth. A value close to 0 means the synapse is unformed; a value larger than a connection threshold (\(p \geq \alpha\)) means the synapse is established and activation of the neighbor cell will contribute to firing of the dendrite, and a value close to 1 means the synapse is well established.
At least three observations can be made at this point. First, notice that we only care about the binary firing state of neurons: whether they are active or not. We have thus already deviated from the traditional continuous representations used in deep learning.
Secondly, the thresholded firing of behavior of dendrites is similar to a traditional activation function (especially a sharp sigmoid) in the sense that below a threshold, the dendrite does nothing, and above the threshold it fires. The paper claims that this behavior adds robustness to noise. If \(\theta = 10\) and we have connections to 12 active neurons for a certain repeated input, but one of the 12 fails to fire, then we’ll still trigger.
Thirdly, representing a single HTM neuron requires more computation and memory. In particular, representing the basal dendrites requires \(B K\) permanence values, and each neuron has three possible states, and we need to keep track of what the previous state was in order to trigger learning.
Layers and Mini-Columns
The cells in the HTM model are arranged in layers. The paper only concerns itself with a single layer at a time. Each layer consists of \(N\) mini-columns of neurons, each with \(M\) neurons. Each neuron has one proximal dendrite, whose input comes from outside of the layer. All neurons in a mini-column share the same proximal dendrite input:
Each neuron has \(B\) basal dendrites that have up to \(K\) synapses to other cells in the same layer. A single basal dendrite for a single cell is shown below. (Note that, technically speaking, the basal dendrite is not directly connected to the soma of the other cells, but has synapses that connect it to the axon of each connected cell.)
The proximal dendrites are responsible for getting the neuron to become active. The neurons in each mini-column share the same proximal dendrite input. If a proximal dendrite becomes active, it can cause all neurons in that mini-column to become active. This is called a burst activation:
The basal dendrites are responsible for predicting whether the neuron will become active. If a basal dendrite becomes active, due to enough of its connected cells being active, it will cause the cell to enter the predictive state:
inhibit them and prevent then from firing. In the HTM model, if there is a proximal activation, any predictive cells become active first. We only get a burst activation if no cells are predictive. Thus, when inputs are predicted (ie learned), we get sparse activation:
As such, the learned synaptic connections in the basal dendrites are what allow the neuron to predict activation patterns. Initially, inputs will not be predicted, and burst activations will trigger entire mini-columns. This increases the chance that basal dendrites will activate, which will increase the number of predictions. Accurate predictions will be reinforced, and will lessen the number of overall activations. Over time, a trained network will have very few burst activations, perhaps only when shifting between two different types of input stream contexts.
Learning
The learning rule is rather simple. A predicted activation is reinforced by increasing the strength of synaptic connections in any basal dendrite that causes the predictive state. We decrease all permanence values in that dendrite by a small value \(p^-\) and increase all permanence values of active synapses by a larger, but still small value \(p^+\). This increases the chance that a similar input pattern will also be correctly predicted in the future.
In an unpredicted activation, (i.e. during a burst activation), we reinforce the dendrite in the mini-column that was closest to activating, thereby encouraging it to predict the activation in the future. We reinforce that dendrite with the same procedure as with predicted activations.
We also punish predictions that were not followed by activations. All permanences in dendrites that causes the predictive state are decreased by a small value slightly smaller than \(p^-\). (I used \(p^-/2\).)
Constant Input
We can see this learning in action, first on a constant input stream. I implemented the HTM logic and presented a simply layer with a constant input stream with some random fluctuations. This experiment used:
M = 3 # number of cells per minicolumn N = 5 # number of minicolumns B = 2 # number of basal dendrites per cell K = 4 # number of potential synapses per cell α = 0.5 # permanence threshold for whether a synapse is connected θ = 2 # basal dendrite activation threshold p⁻ = 0.01 # negative reinforcement delta p⁺ = 0.05 # positive reinforcement delta
A single training epoch in this very simple experiment consists of a single input. The Julia source code for this, and the subsequent experiment, is available here.
As we expect, the layer to starts off with many burst activations, and gradually has no burst activations as training progresses:
If we look at the number of cells in each state, we see that initially we get a lot of active and predictive cells due to the many burst activations, but then gradually settle into a stable smaller number of each type:
We can also look at total network permanence over time. We see an initial increase in permanence as we develop new synaptic connections in order to predict our burst activations. Then, as we being to correctly predict and activations become sparser, we shrink our synapses and lose permanence:
Sparsity and Multiple Simultaneous Predictions
The authors stress the importance of sparsity to how hierarchical temporal memory operates. The paper states:
We want a neuron to detect when a particular pattern occurs in the 200K cells [of its layer]. If a section of the neuron’s dendrite forms new synapses to just 10 of the 2,000 active cells, and the threshold for generating an NMDA spike is 10, then the dendrite will detect the target pattern when all 10 synapses receive activation at the same time. Note that the dendrite could falsely detect many other patterns that share the same 10 active cells. However, if the patterns are sparse, the chance that the 10 synapses would become active for a different random pattern is small. In this example it is only 9.8 x 10-21.
In short, sparsity lets us more accurately identify specific predictions. If sequences are composed of input tokens, having a sparse activation corresponding to each input token lets us better disambiguate them.
The other advantage of sparse activations is that we can make multiple predictions simultaneously. If the layer gets an ambiguous input that can cause two different possible subsequent inputs, the layer can simply cause both predictions to occur. Input sparsity means that these multiple simultaneous predictions can be present at the same time without a great chance of running into one another or aliasing with other predictions.
Note that this sparsity does come at the cost of requiring more space (as in memory allocation), something that the paper does not venture much into.
Sequence Learning
As a final experiment, I trained a layer to recognize sequences. I tried to reproduce the exact same experimental setup as the paper, but that was allocating about 1.6Gb per layer, which was way more than I wanted to deal with. (The permanences alone require \(4 B M N K\) bytes if we use float32’s, and at \(B = 128\), \(M = 32\), \(N = 2048\), and \(K = 40\) that’s 1,342,177,280 bytes, or about 1.3 Gb). This experiment used:
M = 8 # number of cells per minicolumn N = 256 # number of minicolumns B = 4 # number of basal dendrites per cell K = 40 # number of potential synapses per dendrite α = 0.5f0 # permanence threshold for whether a synapse is being used θ = 2 # basal dendrite activation threshold p⁻ = 0.01 # negative reinforcement delta p⁺ = 0.05 # positive reinforcement delta
I trained on 6-input sequences. I generated 20 random sparse inputs / tokens (4 activations each), and then generated 10 random 6-token sequences. Each training epoch presented each sequence once, in a random order.
Below we can see how the number of burst activations decreases over time. Note that it doesn’t go to zero – burst activations are common transitions between sequences.
The paper presented prediction accuracy. I am not certain what they meant by this – perhaps the percentage of times that a neuron entered a predictive state prior to an activation, or the number of activations for which at least a single neuron was predictive. I chose to consider the “prediction” of the neural network to be a softmax distribution over tokens. I had the probability of the next token bitvector \(\vec t\) be proportional to \(\texttt{exp}(\beta (\vec \pi \cdot \vec t))\) for \(\beta = 2\). Here \(\vec \pi\) is the bitvector of predicted columns, i.e. \(\pi_i\) is true if mini-column \(i\) has at least one cell in a predictive state. Anyways, I felt like this measure of prediction accuracy (i.e. mean likelihood) more closely tracked what the layer was doing and how well it was performing. We can see this metric over time below:
Here we see that the layer is able to predict sequences fairly well, hovering at about 50% accuracy for tokens that are not the first token (we transition to a random 6-token sequence, so its basically impossible to do well there), and about 40% accuracy across all tokens. I’d say this is pretty good, and demonstrates the proof of concept of the theory in practice.
Conclusion
Overall, hierarchical temporal memory is a neat way to train models to recognize sequences. Personally, I am worried about how much space the model takes up, but aside from that the model is fairly clean and I was able to get up and running very quickly.
he paper did not compare against any other substantial sequence learners (merely a dumb baseline). I’d love for a good comparison to something like a recurrent neural network to be done.
I noticed that the HTM only trains dendrites that become predictive (or chooses dendrites in the case of a burst activation). This requires the mini-column of the parent neuron to be activated in order to be trained. If a certain column is never activated, the dendrites for that neuron will not be trained. Similarly, if some dendrite is not really used, there is a very low chance it will ever be used in the future. I find this to be a big waste of space and an opportunity for improvement. We are, in a sense, building a random network in initialization and hoping that some of the connections work out, and ignoring the rest. This random forest approach only gets us so far.
I had a lot of fun digging into this and noodling around with it. I am very excited about the prospect of human-level cognition, and maybe something HTM-like will get us there some day.
My coauthor and I have finished a textbook! That’s right, a full-length, fully-featured academic textbook. Algorithms for Optimization has its own page on the MIT Press website and comes out February of 2019. And its available for free!
We started working on it a little over two years ago, in the fall of 2016. Now it is nearing the end of the fall of 2018 and it is becoming a reality.
What does it take to write a textbook? That’s a good question; one that I certainly did not know the answer to going in, and one for which I now need several hours of recollection and introspection to tease out the appropriate response. This blog post is my answer to that question. I hope that it is useful to you, whether it helps understand the scope of the work involved, brings up aspects that hadn’t been considered, or points out tools that might help you with your own book.
What We Made
Our book, Algorithms for Optimization, is a full-length college-level academic textbook based based on material from Prof. Kochenderfer’s Engineering Design Optimization course at Stanford. Prof. Kochenderfer and I authored the book together.
The book provides an introduction to optimization with a focus on practical algorithms. There are many optimization books that cover specific disciplines (such as structural optimization), or specific techniques (such as convex optimization). Our book’s twenty-one chapters span the optimization literature, covering the mathematical and algorithmic fundamentals of optimization. Algorithms for Optimization is probably best compared to the popular Numerical Recipes books, which cover a wide range of algorithms encountered in computer science. Like Numerical Recipes, we provide real code, are not discipline-specific, and are not domain-specific.
Algorithms for Optimization is filled with easy-to-understand Julia implementations of all algorithms. This is real code that actually runs. We run real code – these algorithms – to generate the many illustrations.
Did I mention illustrations? The book is filled with data-rich figures and side notes to explain concepts. In my option, these illustrations are fundamental in conveying understanding. Plus, they make the book look great.
This figure uses the method of small multiples to show how the Nelder Mead algorithm proceeds. The figure is generated from Julia code written directly in the LaTeX file and is executed via the pythontex package during compilation.
We made liberal use of the side margins to elaborate on concepts via side notes without interrupting flow. Figures can be placed in the margins, and all of our citations show up in the margins as well. This was inspired by Edward Tufte, the father of data visualization.
Everything was written in LaTeX with Bitbucket for source control. Everything is a text resource. That’s right. I’ll say it again. Everything is a text resource.
All figures are either defined in the LaTeX document directly using TikZ, or come from TikZ code that is generated during compile time from Julia code blocks defined in the LaTeX document. More on this later.
The Tufte style provided by the tufte-book class provides wide side margins for comments and figures. Image from the tufte-book documentation.
All in all, Algorithms for Optimization is unique in form and function. Our primary selling points are:
Easy-to-understand Julia implementations of all algorithms.
Data-rich illustrations and side notes to explain concepts without interrupting flow.
A chapter on multidisciplinary design optimization that deviates from the traditional academic treatment to greatly simplify the exposition.
Chapters on surrogate models and surrogate optimization methods.
A comprehensive overview of continuous numerical optimization with an undergraduate audience in mind.
Additional chapters on discrete and expression optimization.
Timeline
Prof. Kochenderfer and I started working on Algorithms for Optimization in the fall of 2016. I was his graduate student at the time and had just started my third year of grad school.
The timeline for Algorithms for Optimization. It only took us a little over two years! Copyediting takes a long time.
Prof. Kochenderfer had been teaching this class, AA222, called Multidisciplinary Design Optimization at the time. Prof. Kochenderfer had inherited it from another professor, and had shifted the focus of the class from MDO to a more general overview of engineering design optimization. The class was great. It got great reviews. Prof. Kochenderfer had taught it twice. The problem was, there was no textbook for it, because there weren’t really any textbooks that covered so many optimization techniques.
Prof. Kochenderfer had already written a textbook, Decision Making under Uncertainty, so he knew how to go about it. The problem was, as a professor, Prof. Kochenderfer was extremely pressed on time. He had the course notes, but little time to devote to turning them into a textbook. Enter Tim Wheeler.
As a grad student, I had more free time on my hands. Maybe not far more. (Those who know Prof. Kochenderfer’s schedule could easily argue that yes, grad students have far more free time than he does.), but more for sure. Furthermore, Prof. Kochenderfer was able to obtain some funding toward writing the textbook, which was a fantastic way to get the ball rolling.
A fortuitous happenstance helped get the book off the ground: I spent the fall of 2016 in Germany as part of a student exchange. This meant I was removed from my friends, family, and peers, so I had very little to do in the evenings. I started the book in earnest on my flight to Germany, and continued working on it for my entire time there, making first passthroughs of around 80% of the planned material.
I worked on the book in the evenings, trying to have finishing one chapter passthrough every week. Prof. Kochenderfer thoroughly reviewed and edited my passthroughs thereafter. It worked out really well. In a nutshell, I created vast quantities of content and he edited every detail micro- and macroscopically.
There are several steps involved that I had not expected, or at least had not considered. The prospectus is this document that has to be put together that proposes the book to the publisher. In it one lists the contents of the book, the target audience for the book, what it does differently than other textbooks, a huge list of textbooks like this textbook and why they don’t serve the same audience or function, etc. Thankfully Prof. Kochenderfer had done this before. We wrote the prospectus fairly early on, and attached our first polished chapter for review.
The publisher takes the prospectus and the sample chapter and typically sends it out to other professors and experts in the field for review. They may recommend the book for publishing. I learned that most professors care about textbooks insofar as they can be used in class. This makes sense – professors teach classes.
We ran into the interesting problem that our textbook doesn’t really cover anything novel from the perspective of experts in optimization. Experts in optimization are not our target audience. Our book was written to summarize a large body of existing work that emerged within a variety of different communities, not to present any novel research results. (Novel research is typically presented in journal articles and conference papers.) Some of the reviewers had tepid responses largely because the book did not go into the kind of depth of prior books dedicated to particular subareas. Thankfully the general consensus was that the topics we cover are uniquely broad within a single text. MIT Press had worked with Prof. Kochenderfer before, knew that his previous book was a huge success, and intuited that this book would be too, despite not having graduate students in optimization as its target audience.
We have used the book in AA 222 for two quarters now. Getting direct feedback from students has been an immense help. So does hearing all of the praise. Not every textbook author has access to such a captive audience. I consider us extremely lucky.
The copyediting phase of the textbook is far longer than I expected. The copyeditors we have worked with are incredibly thorough. I have a huge amount of respect for them. They find every. single. issue. Who knew that North American writers should use toward instead of towards? One should use 1 when referring to the quantity and one when referring to the pronoun. The rules for which and that are now forever ingrained in my muscle memory. Commas are complicated. Every figure, example, and algorithm had to be referenced in the text. I am very thankful for the reviewers.
The final book is over 500 pages. Each page represents many hours of effort. We have written and rewritten every sentence. We agonize over spacing. Every figure goes through so many tweaks and changes.
Our book will have taken about two and a half years from start to finish. Textbooks take a long time. To put this timeline into context, Sebastian Thrun told me Probabilistic Robotics took seven years. Prof. Kochenderfer and I had a fortuitous synergy in work ethic, division of labor, time availability, and grit.
Our Toolkit
What tools did we use to write the book? I have already mentioned some.
LaTeX
First and foremost, the book was written in LaTeX, a typesetting language that is the go-to tool for mathematical typesetting. Everything is written in text. The expression:
$$x^2$$
for instance, is written $x^2$. LaTeX documents are compiled to PDF.
LaTeX does a lot of work for us. Figures are numbered automatically. Figures are referenced from the text automatically. Layout is determined automatically. It works so well that we actually provide the final PDF to MIT Press rather than having them do any editing of the document themselves. From my understanding, this is very uncommon.
We use lualatex to compile our book. The primary reason is that it gives us access to some better fonts and font tools. We use the fontspec package. We are on the latest version of texlive.
Tufte Style
Our book uses the tufte-book style. This gives us access to a wide side margin in which we can place comments and figures. In-line comments (like this) interrupt the flow. Side margin comments allow us to provide additional information while minimizing interruptions. We can also include some more advanced commentary without overwhelming the reader.
Every citation in the book is placed in the side margin, so you can find the exact paper without having to flip to some other page in the book. Every figure has a caption and we reference every figure in the text.
Beyond the explicit style, we also follow the Tufte philosophical principles. The method of small multiples is used throughout the book to show how an algorithm progresses. This involves multiple charts with the same scale and axes allow one to quickly see the meaningful differences between them.
We use a consistent color scheme throughout the book. In fact, we try to be as consistent as possible throughout the book in every aspect – notation, typography, how we phrase things, etc.
Pythontex
We use juliaplots.sty to make it easy to integrate Julia code and plots in our book. It is extremely easy to use and install. It uses pythontex under the hood.
The pythontex package allows one to display, execute, and execute & display code in LaTeX. It was originally written for python but now supports quite a few languages. We use it for typesetting all Julia code blocks and for generating many of the figures in the book. All figures in the book are defined using text – either in TikZ or in julia code via pythontex that generates TikZ.
The Julia code blocks are juliaverbatim environments containing our code. When compiled, these blocks are typeset and syntax highlighting is applied. We created our own lexer and syntax highlighting theme using the pygments package.
The figures we generate using pythontex are jlcode environments with the structure:
If there is interest in diving deeper into how we structured this, with code examples and a minimum working example, let me know!
Custom Environments
Prof. Kochenderfer is a LaTeX wizard. He created several environments that we use throughout the book. Algorithms are in algorithm environments and examples are in example environments. Both have a light gray background and support automatic labeling with numbers based on the chapter. For example, the second algorithm environment in the fifth chapter is automatically labeled Alg 5.2. I believe the two environments are identical under the hood – we just count algorithms and examples differently.
We also have question and solution environments. These allow us to have finer control over where the questions and solutions are placed. When writing the chapters it is nice to be able to have the questions and solutions be placed immediately after one another at the end of the chapter. In the final version of the book all solutions are moved to a solutions section at the end. Again, question numbers are automatically generated by LaTeX.
Bitbucket
We use git for source control, and Bitbucket to host it. Everything is defined in text files, so we can easily commit, push, pull, etc. to and from our repository. Having a project with only two people allowed us to work almost exclusively in the master branch directly. In some cases I branched, such as when I overhauled the book to use Julia 1.0 rather than Julia 0.6.
We have a server that uses git hooks to listen for commits. Any time we push a change to master, the server updates its git repo and compiles the full book as well as each individual chapter into a PDF. We have our own password-protected website with URLs to these PDFs that we release to potential reviewers. Thus they always have access to the latest version of the book. We used the vc package and a bash script to automatically generate a footer on every page of the PDF containing the version number, so you always know what version you are looking at.
We used Bitbucket to track issues. This was extremely valuable. In early forms of the book we left comments and todo notes in the text. Once we started releasing chapters to students we didn’t feel that was appropriate. We thus filed issues for every little (and big) thing that we had to remember to do. Issues were resolved as appropriate and we managed to whittle down the list over time. We have had 560 issues and 2555 commits.
Code testing is done using Travis-CI, a continuous integration framework that is also triggered on every commit. Travis runs test scripts we wrote to test the code in our algorithm environments. We track code coverage with coveralls to build confidence that we have tested everything thoroughly.
Zendesk
We used Zendesk to help us track external issues. Anyone with feedback to give could send an email to comments@alg4opt.net. Zendesk would receive the email and put it into its own handy issue system. We could easily assign messages to each other, respond to the writer, complete them, and have hidden discussions within each message chain.
Based on our email exchanges we had around 187 reviewers that were not AA222 students.
Mental Considerations
Perhaps the most challenging aspect of writing a textbook has been the mental aspect. Those who write textbooks need to be in it for the long haul. Every sentence is going to be written and rewritten, considered from different angles, potentially misinterpreted by students or reviewers, and needs to stay consistent with respect to the style of the rest of the text. You can go down endless rabbit holes in terms of tweaking different aspects. There is an ever-expanding list of new chapters or sections that could be written, new problems and solutions that could be explored, and new ways to cover material.
On top of that, there are all of introductions and tasks that are not as fun to write, but someone has to write them. Oftentimes once one gets down to it is isn’t that bad, and in many cases illuminating. Nevertheless one needs grit to overcome these moments.
An issue I ran into was criticism. No-one likes being critiqued, and when writing a \num{500} page book there are plenty of chances for people to point out dumb mistakes, not so dumb mistakes, sections which are unclear, and sections you should consider including. Don’t get me wrong, almost all of the criticism we got was constructive. Taking criticism early on always caused a hit my ego, and learning to handle that better has helped me develop as a person.
Lastly, writing a textbook with a co-author requires working together with someone in an intense collaborative manner for a very long time. I find it hard to imagine a better co-author than Prof. Kochenderfer. His undying passion to complete the book, seemingly inexhaustible capacity for detail-oriented work, and on-point review of anything and everything I ever committed made this book successful. No corners were ever cut. No concept was ever explained out of order. We worked together incredibly well.
I highly, highly stress that if you do consider writing a book with a co-author, it is imperative that you find someone with whom you really click. Because you’ll be crafting your beautiful product together for a long time.
Conclusion
I am incredibly happy with how Algorithms for Optimization evolved into what it is today. It is an achievement for which I have immense pride. I hope that it is useful to someone, hopefully many someones, for that is the overall purpose of all this.
DeepMind’s AlphaGo made waves when it became the first AI to beat a top human Go player in March of 2016. This version of AlphaGo – AlphaGo Lee – used a large set of Go games from the best players in the world during its training process. A new paper was released a few days ago detailing a new neural net—AlphaGo Zero—that does not need humans to show it how to play Go. Not only does it outperform all previous Go players, human or machine, it does so after only three days of training time. This article will explain how and why it works.
Monte Carlo Tree Search
The go-to algorithm for writing bots to play discrete, deterministic games with perfect information is Monte Carlo tree search (MCTS). A bot playing a game like Go, chess, or checkers can figure out what move it should make by trying them all, then checking all possible responses by the opponent, all possible moves after that, etc. For a game like Go the number of moves to try grows really fast. Monte Carlo tree search will selectively try moves based on how good it thinks they are, thereby focusing its effort on moves that are most likely to happen.
More technically, the algorithm works as follows. The game-in-progress is in an initial state s0, and it is the bot’s turn to play. The bot can choose from a set of actionsA. Monte Carlo tree search begins with a tree consisting of a single node fors0. This node is expanded by trying every actiona∈A and constructing a corresponding child node for each action. Below we show this expansion for a game of tic-tac-toe:
The value of each new child node must then be determined. The game in the child node is rolled out by randomly taking moves from the child state until a win, loss, or tie is reached. Wins are scored at \(+1\), losses at \(-1\), and ties at \(0\).
The random rollout for the first child given above estimates a value of \(+1\). This value may not represent optimal play-it can vary based on how the rollout progresses. One can run rollouts unintelligently, drawing moves uniformly at random. One can often do better by following a better-though still typically random-strategy, or by estimating the value of the state directly. More on that later.
Above we show the expanded tree with approximate values for each child node. Note that we store two properties: the accumulated value \(W\) and the number of times rollouts have been run at or below that node, \(N\). We have only visited each node once.
The information from the child nodes is then propagated back up the tree by increasing the parent’s value and visit count. Its accumulated value is then set to the total accumulated value of its children:
Monte Carlo tree search continues for multiple iterations consisting of selecting a node, expanding it, and propagating back up the new information. Expansion and propagation have already been covered.
Monte Carlo tree search does not expand all leaf nodes, as that would be very expensive. Instead, the selection process chooses nodes that strike a balance between being lucrative-having high estimated values-and being relatively unexplored-having low visit counts.
A leaf node is selected by traversing down the tree from the root node, always choosing the child \(i\) with the highest upper confidence tree (UCT) score:
$$U_i = \frac{W_i}{N_i} + c \sqrt{\frac{\ln N_p}{N_i}}$$
where \(W_i\) is the accumulated value of the \(i\)th child, \(N_i\) is the visit count for the \(i\)th child, and \(N_p\) is the number of visit counts for the parent node. The parameter \(c \geq 0\) controls the tradeoff between choosing lucrative nodes (low \(c\)) and exploring nodes with low visit counts (high \(c\)). It is often set empirically.
The UCT score (\(U\)’s) for the tic-tac-toe tree with \(c=1\) are:
In this case we pick the first node, \(s_{0,1}\). (In the event of a tie one can either randomly break the tie or just pick the first of the bet nodes.) That node is expanded and the values are propagated back up:
Note that each accumulated value \(W\) reflects whether X’s won or lost. During selection, we keep track of whether it is X’s or O’s turn to move, and flip the sign of \(W\) whenever it is O’s turn.
We continue to run iterations of Monte Carlo tree search until we run out of time. The tree is gradually expanded and we (hopefully) explore the possible moves, identifying the best move to take. The bot then actually makes a move in the original, real game by picking the first child with the highest number of visits. For example, if the top of our tree looks like:
then the bot would choose the first action and proceed to \(s_{0,1}\).
Efficiency Through Expert Policies
Games like chess and Go have very large branching factors. In a given game state there are many possible actions to take, making it very difficult to adequately explore the future game states. As a result, there are an estimated \(10^{46}\) board states in chess, and Go played on a traditional \(19 \times 19\) board has around \(10^{170}\) states (Tic-tac-toe only has 5478 states).
Move evaluation with vanilla Monte Carlo tree search just isn’t efficient enough. We need a way to further focus our attention to worthwhile moves.
Suppose we have an expert policy \(\pi\) that, for a given state \(s\), tells us how likely an expert-level player is to make each possible action. For the tic-tac-toe example, this might look like:
where each \(P_i = \pi(a_i \mid s_0)\) is the probability of choosing the \(i\)th action \(a_i\) given the root state \(s_0\).
If the expert policy is really good then we can produce a strong bot by directly drawing our next action according to the probabilities produces by \(\pi\) , or better yet, by taking the move with the highest probability. Unfortunately, getting an expert policy is difficult, and verifying that one’s policy is optimal is difficult as well.
Fortunately, one can improve on a policy by using a modified form of Monte Carlo tree search. This version will also store the probability of each node according to the policy, and this probability is used to adjust the node’s score during selection. The probabilistic upper confidence tree score used by DeepMind is:
$$U_i = \frac{W_i}{N_i} + c P_i \sqrt{\frac{\ln N_p}{1 + N_i}}$$
As before, the score trades off between nodes that consistently produce high scores and nodes that are unexplored. Now, node exploration is guided by the expert policy, biasing exploration towards moves the expert policy considers likely. If the expert policy truly is good, then Monte Carlo tree search efficiently focuses on good evolutions of the game state. If the expert policy is poor, then Monte Carlo tree search may focus on bad evolutions of the game state. Either way, in the limit as the number of samples gets large, the value of a node is dominated by the win/loss ratio \(W_i / N_i\), as before.
Efficiency Through Value Approximation
A second form of efficiency can be achieved by avoiding expensive and potentially inaccurate random rollouts. One option is to use the expert policy from the previous section to guide the random rollout. If the policy is good, then the rollout should reflect more realistic, expert-level game progressions and thus more reliably estimate a state’s value.
A second option is to avoid rollouts altogether, and directly approximate the value of a state with a value approximator function \(\hat{W}(x)\). This function takes a state and directly computes a value in \([-1,1]\), without conducting rollouts. Clearly, if \(\hat{W}\) is a good approximation of the true value, but can be executed faster than a rollout, then execution time can be saved without sacrificing performance.
Value approximation can be used in tandem with an expert policy to speed up Monte Carlo tree search. A serious concern remains-how does one obtain an expert policy and a value function? Does an algorithm exist for training the expert policy and value function?
The Alpha Zero Neural Net
The Alpha Zero algorithm produces better and better expert policies and value functions over time by playing games against itself with accelerated Monte Carlo tree search. The expert policy \(\pi\) and the approximate value function \(\hat{W}\) are both represented by deep neural networks. In fact, to increase efficiency, Alpha Zero uses one neural network \(f\) that takes in the game state and produces both the probabilities over the next move and the approximate state value. (Technically, it takes in the previous eight game states and an indicator telling it whose turn it is.)
$$f(s) \rightarrow [\vec p, W]$$
Leaves in the search tree are expanded by evaluating them with the neural network. Each child is initialized with \(N = 0\), \(W = 0\), and with \(P\) corresponding to the prediction from the network. The value of the expanded node is set to the predicted value and this value is then backed up the tree.
Selection and backup are unchanged. Simply put, during backup a parent’s visit counts are incremented and its value is increased according to \(W\).
The search tree following another selection, expansion, and backup step is:
The core idea of the Alpha Zero algorithm is that the predictions of the neural network can be improved, and the play generated by Monte Carlo tree search can be used to provide the training data. The policy portion of the neural network is improved by training the predicted probabilities \(P\) for \(s_0\) to match the improved probability \(\vec \pi\) obtained from running Monte Carlo tree search on \(s_0\). After running Monte Carlo tree search, the improved policy prediction is
$$\pi_i = N_i^{1/\tau}$$
for a constant scalar \(\tau\). Values of \(\tau\) close to zero produce policies that choose the best move according to the Monte Carlo tree search evaluation.
The value portion of the neural network is improved by training the predicted value to match the eventual win/loss/tie result of the game, \(Z\). Their loss function is:
where \((W-Z)^2\) is the value loss, \( \vec \pi^\top \ln \vec p\) is the policy loss, and \(\lambda \|\vec \theta\|_2^2\) is an extra regularization term with parameter \(\lambda \geq 0\) and \(\vec \theta\) represents the parameters of the neural network.
Training is done entirely in self-play. One starts with a randomly initialized set of neural network parameters \(\vec \theta\) are then improved by using gradient descent (Or any of the more sophisticated accelerated descent methods-Alpha Zero used stochastic gradient descent with momentum and learning rate annealing.) on the loss function for a random selection of states played.
Closing Comments
And that’s it. The folks at DeepMind contributed a clean and stable learning algorithm that trains game-playing agents efficiently using only data from self-play. While the current Zero algorithm only works for discrete games, it will be interesting whether it will be extended to MDPs or their partially observable counterparts in the future.
It is interesting to see how quickly the field of AI is progressing. Those who claim we will be able to see the robot overlords coming in time should take heed – these AI’s will only be human-level for a brief instant before blasting past us into superhuman territories, never to look back.
I have been working with probability and machine learning lately, particularly with fitting distributions to datasets. Fitting data is something covered in conventional pre-college curriculum, but I have only ever done it when all of my data has been complete. More recently I ran into a problem.
One fundamental feature in autonomous driving is the distance to the car in front of you. This tends to be a real number, something hopefully a bit bigger than a few meters when travelling at high speeds and potentially quite large when traffic is low. If you have a set of sensors on your car, like radars or lidar, you can only pick up cars up to a certain distance away from yourself. What do you do if there is no car in front of you? Set the distance to infinity?
This is a good example of censored data, a feature where data must fall within a given range but you know when it does so. The other types are truncated and missing data. Data is truncated when the only data you have is within a certain range, and you do not know of the occurrences when it falls outside of that range. Missing Data occurs when you missed or corrupted a reading, or for some reason it is not available. A good example is the velocity of the car in front of you.
So how does one handle fitting distributions to such features?
The answer is a surprisingly straightforward application of Bayes’ theorem.
Consider first a toy problem:
Unstable particles are emitted from a source of decay at a distance \(x\), a real number that has an exponential probability distribution with characteristic length \(\lambda\). We observe \(N\) decays at locations \(x_1, x_2, \ldots, x_N\). What is \(\lambda\)?
“Information Theory, Inference, and Learning Algorithms” by David MacKay
Solving this for the case with perfect data provides us some insight.
Fully Observed Data
The probability distribution for a single sample point, given \(\lambda\), is:
$$P(x\mid \lambda) = \lambda e^{-\lambda x}$$
from the definition for the exponential probability distribution.
Applying Bayes’ theorem and assuming independence:
We can see that simply by conditioning on the data available and setting a prior we can determine the likelihood distribution for the value of \(\lambda\). From here we can do what we wish, such as picking the most likely value for \(\lambda\).
Truncated Data
Suppose, however, that the data is truncated. Suppose that we only get readings for particle decays between \(x_\min\) and \(x_\max\). Fitting in the same way is going to cause inconsistencies. Let us start again, following the same steps.
The probability distribution for a single sample point, potentially truncated, given \(\lambda\), is:
This is very similar, and was quite easy to determine.
Censored Data
Without going into detail, we can derive the model for censored data. Suppose \(x\) is censored to be less than \(x_\max\), which occurs if our particle detector has a finite length and particles that would have decayed after \(x_\max\) instead slam into the back and report as \(x_\max\):
where $Z(\lambda)$ is the probability of \(x\) being uncensored, $Z'(\lambda)$ is the probability of \(x\) being censored, and \(\delta\) is the Dirac distribution. Here, $Z(\lambda)$ is:
The final case is missing data. Here, you know when the data is missing but you have no information about where it was. This sort of data must be fitted using the original method using only the observed values.