When I was first learning about deep learning, brought up an issue with image classifiers and black swans. I would call this the black swan problem, but it turns out that has a related but different meaning, so let’s go with swan classifier generalization problem. It goes like this:
If you train a classifier to identify objects in images, and one of those categories is swans, that classifier will tend to be training exclusively or predominantly on white swans. At deployment it is likely to misclassify images of Australian black swans.
This isn’t all that surprising. Generalization in deep learning is hard.
What is surprising is:
Most humans familiar with swans would be able to recognize an Australian black swan as a swan.
In other words, humans are good at generalization and are able to do it better than many of our traditional deep learning tools, at least in comparison to ImageNet and other, older, deep image classifiers.
This post is an exploration into deep learning, classification, and generalization, and about why I think feature embeddings go a long way to building a better knowledge representation. None of this is particularly new or insightful – I just find it useful to work it out and tie it all together.
Grandmother Cells
A deep image classifier takes as input an image and produces as output a softmax distribution over a discrete set of categories:
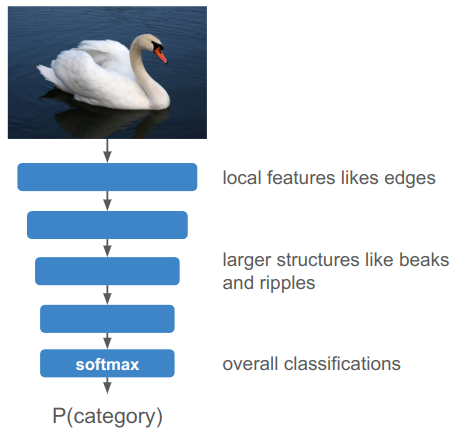
Conventional knowledge is that deeper levels reason about more sophisticated, higher-level features. Very early convolutional layers typically only have access to small neighborhoods of pixels, so learn local features like edge detections and textures. Deeper layers might piece together larger structures like a bird beak or ripples in a lake. Finally, all of this information is brought together to produce the final classification.
Under such an approach, you literally have one, single neuron at the end responsible for firing when it thinks the image has a swan. The more intensely its output value, the more confident the swan prediction.
There have historically been two opposing views on the relationship between brains and behavior — the localist view that specific brain regions are responsible for specific behaviors, and the holistic view that neural activity is spread out throughout the nervous system. A critic of the localist view might think it absurd that there is a single neuron somewhere in your head that fires over the concept of “Grandmother”.
A grandmother cell is just that — a neuron exclusively dedicated to one high-level but specific concept. (Funny enough, there was a lot of hubbub in 2005 about recordings that suggested that a single neuron had been found that triggers only for Jennifer Aniston.)
By and large, researchers do not believe that the best way to represent knowledge is through a 1:1 representation such as grandmother cells. As such, it may not come as a surprise when a traditional convolutional deep image classifier like ImageNet struggles to classify black swans.
Sparse Encodings
A traditional image classifier is structured to prefer sparse outputs. A confident prediction should produce a high value in the appropriate category and very low values elsewhere:

If the model is uncertain, it is forced to make the appropriate trade-off to assigning some probability mass to the other potential categories. That might mean assigning some likelihood to other black birds:
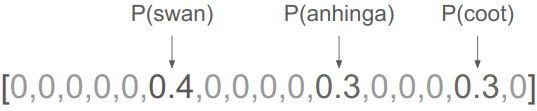
This sort of representation might be convenient for the output of a classifier, but it isn’t all that useful for reasoning. If I am trying to think about what it means for an object to be a swan, I don’t want to simply know it is a swan, I want to think about where I might find it (e.g. on a lake), what it might do (e.g. honk at me), and sure, what it looks like (e.g. tends to be white-feathered).
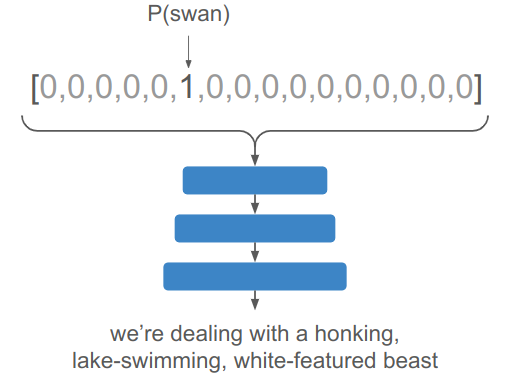
A reasoning network that receives the fact that there is a swan would thus have to unpack this discrete bit of knowledge into these myriad facts:
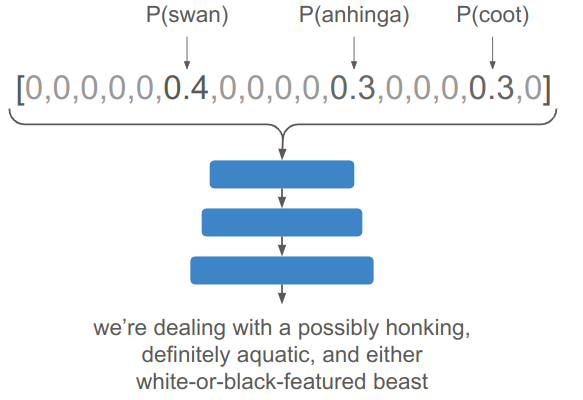
Worse yet, if you have an uncertain input, you have to unpack all contributors and figure out how to combine them:
Working directly with the discrete bit of knowledge is fragile. If \(P(\text{swan})\) is low, then the network just can’t associate the object to a swan. However, if we’re working with the distributed properties and associations of a swan, its a whole lot easier to get to swan if one property (color), is unusual.
The third thing going on here is that sparse representations don’t use the state space as efficiently. If my reasoning network receives a \(128-\) dimensional vector, and we’re working with one-hot encodings where everything but one dimension is zero, then we can only represent 128 different concepts. In contrast, if we’re willing to use the whole state space, we can represent more or less any number of concepts.
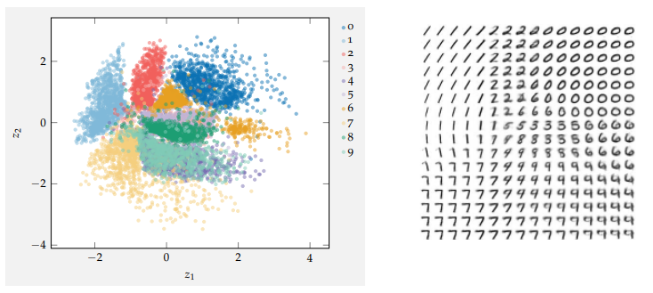
A 2D embedding for the MNIST digits. The left-side shows how digits are mapped to the embedding, and the right shows how samples from the space produce digit images. Images from Algorithms for Decision Making.
Discrete representations are thus hard to work with, fragile, and wasteful.
Transformer Embeddings
You might think that the transformer model suffers from this same problem of discrete reasoning, as they operate on sequences of one-hot tokens. However, these discrete tokens are immediately mapped to a rich embedding vector:
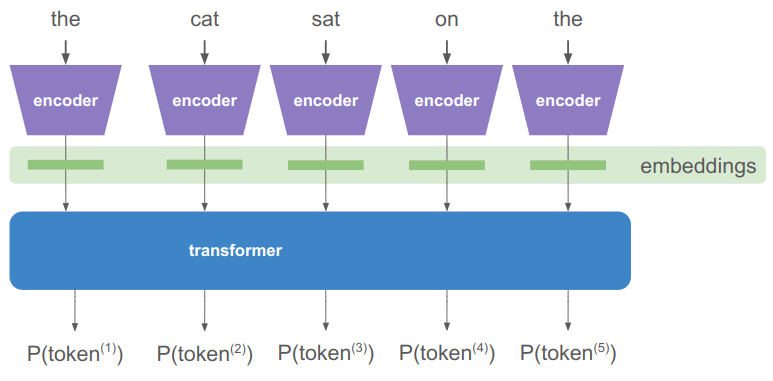
The encoder literally has a separate high-dimensional embedding vector for each discrete token. If we have a vocabulary of \(m\) unique tokens and an \(n\)-dimensional embedding space, then our embeddings are given by an \(n \times m\) matrix. Multiplying by the one-hot token extracts the embedding vector:
\[\boldsymbol{e}^{(i)} = \begin{bmatrix}\boldsymbol{e}^{(1)}, \boldsymbol{e}^{(2)}, \cdots \boldsymbol{e}^{(i)}, \cdots, \boldsymbol{e}^{(m)} \end{bmatrix} \begin{bmatrix}0 \\ 0 \\ \vdots \\ 1 \\ \vdots \\ 0\end{bmatrix}\]
Transformers learn what values to assign to these embedding vectors. As such, they can pack a lot of meaning into those \(n\) dimensions, far more than would be used if it was stuck operating on \(m\) discrete categories.
I talk about transformers in Transformers, How and Why They Work, but gloss over what these embedding vectors really give us. Transformer layers are best thought of as taking the input embedding vectors, which each point in some direction, and incrementally rotating them to point in other directions. (There’s a great video of this by 3Blue1Brown.)
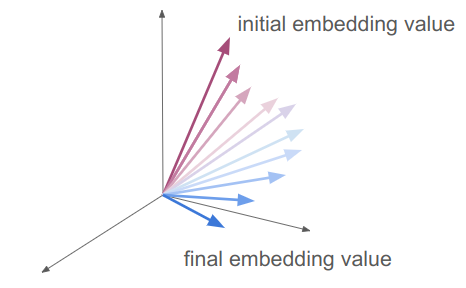
Keep in mind that these are actually very high-dimensional feature spaces.
The initial embedding value is the one the raw token is associated with. The final embedding value is the output of all of the transformer layers, right before a final set of affine layers to go from an \(n\)-dimensional embedding to an \(m\)-dimensional set of logits for the next token.
That means:
- the final embedding should have of the information for predicting the next token
- the initial embedding value have the superposition of all meanings the general token
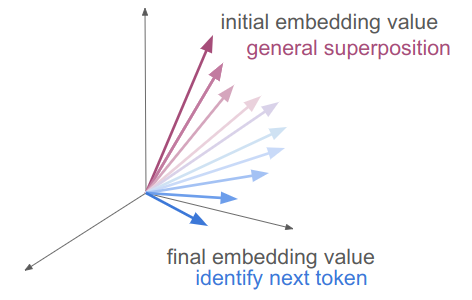
Those are two very different things – hence the need for all those transformer layers and incremental updates.
A final embedding that predicts the next word in “the cat sat on the” needs to capture all the things that a cat might sit on (e.g. laps, mats), as well as adjectives of places cats might sit (e.g. warm laps), and who knows what else people append to that sentence. There is no way that we could capture that superposition of meaning with only \(m\) discrete options.
Interestingly, an initial embedding value also needs to represent a superposition of concepts. The embedding for “mat” for example, might mean a nice place for a cat to sit in one context, but could also be a large concrete slab, or a thick wad of hair.
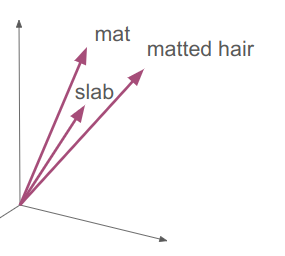
That means the initial embedding for “mat” should lie in a similar direction as those other concepts. At the very least, it would likely have subcomponents of its \(n\)-dimensional feature space that lie in similar directions. A part of “mat” and “slab” will align for the meaning they share, and likely a different part of “mat” and “matted hair” would align for the meaning those two words share.
This all shows how Transformers are able to assign juxtapositions of meanings using embedding vectors. It can do this in part because the continuous feature space allows for cramming a lot of meanings into the same number of dimensions, allows for smoothly interpolating between meanings, and because a single direction can be made up for sub-directions that have their own meanings. That is exactly what we’re looking for when we want to predict a black swan when we know we need a word for a feathered creature with a big beak on a lake that honks and happens to be colored black.
Why do Transformers learn all this? Because they have to in order to predict the next token accurately. Language is incredibly rich and carries all of these layered meanings.
More Holistic than Local?
One of the big takeaways for me is that knowledge representation using transformer-like dense embeddings is able to pack in and superimpose many concepts, and ends up being less fragile as a result. If enough of the concepts point to a swan, we can still deduce that we need a swan.
I am not a neuroscientist, but I find it highly likely that true grandmother neurons are quite rare. Instead, meaning is more likely to be found packed into subspaces represented by groups of neural firing patterns.
Similarly, I am reminded of writing software for robotics applications. If you’re writing code yourself, then you’re likely basing your reasoning on a comparatively small set of concepts. Take a sidewalk delivery robot for example. A reasonable programmer might try to enforce that the sidewalk delivery robot never cross a light on red. However, said reasonable programmer might get sad when they run into a case where an intersection is under construction and the light is red, but the path is open to pedestrians and delivery robots:
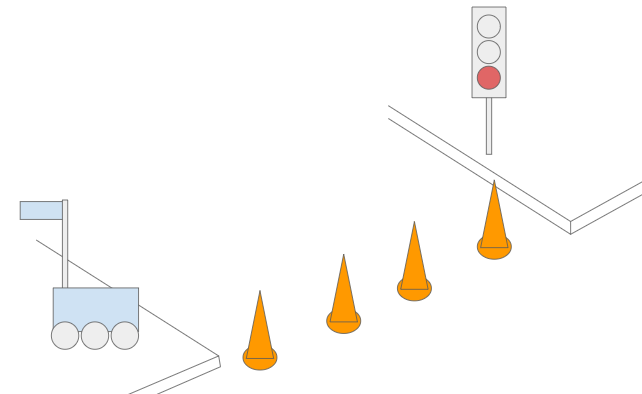
The world is a complicated place, and we quickly find that the number of cases our coded heuristics can handle is quite small. We can easily set ourselves up for failure if we code like grandmother cells. At the very least, code that makes declarative statements needs to be very careful to make declarative statements about what it really is judging — whether the contextual scene is appropriate for crossing or not rather than whether the light is red. As we’ve already learned – getting hung up on color is what motivated this blog post in the first place.
Can we rewrite robotics logic to use embedding vectors? Perhaps. Unfortunately, transformer embeddings are fairly inscrutable to anyone other than the transformer. Interpretable machine learning is still a nascent field.
I think transformers are incredible, but I also think some fundamental properties are missing. They don’t really understand the world yet, not really. AI fails in embarrassing ways. We as humans can write code to reason about \(m\) discrete things. We have a much harder time reasoning about all of the overlapping subtleties of the real world.
Conclusion
This post doesn’t really have a decisive answer. In fact, I hope it serves as food for thought.
I think it is worth pondering these questions as we move forward in this bold new world of Software 2.0, where everything is a transformer and we can do more than we ever could before but don’t really understand how it works or just how far it can take us.
I think this is an incredibly exciting time. It seems like we are very close to cracking the nut of “how we think”. Heck, even John Karmack started working on AI because he feels similarly.
There is likely still something to be learned from how the human brain works. It is the reference model that we have, the irrefutable evidence that there are systems that can reliably learn and then reliably perform well on real-world tasks. Intelligences that know that crossing at red when the road is blocked to cars. Intelligences that more-or-less do the right thing, with very few training examples. Those intelligences may not have figured it out just yet, but perhaps by searching more within, they can finally get to the bottom of things.